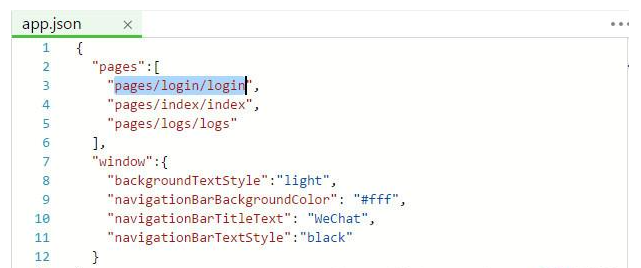
微信小程序本地存储与登录页面处理实例详细讲解
658
2022-09-11

Python爬虫(学习准备)(python爬虫应该怎么学)
(python爬虫应该怎么学)")
编码格式的认识:
字符:各种文字和符号的统称
字符集:多个字符的集合
字符集包括:ASCII字符集,GB2312字符集,GB18030,Unicode字符集等
1个字符ASCII编码占1个字节,用Unicode编码占2个字节
UTF-8是Unicode的实习方式之一,是一种变长的编码方式,可以是1,2,3个字节等
在Python中字符串分为两种类型:
bytes:二进制,互联网上数据都是以二进制传输
str:unicode的呈现方式
str与bytes的转换:
encode() #str->bytes
decode() #bytes->str
1
2
3
4
5
6
7
a = '华南理工大学广州学院'
print(type(a)) #
b = a.encode() #参数不填默认utf-8编码
print(b)
print(type(b)) #
a = b.decode('utf-8')
print(a) #华南理工大学广州学院
cookie和session区别:
cookie数据存放在客户的浏览器上,session数据放在服务器上。
cookie不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗
session会在一定时间内保存在服务器。当访问增多,会比较占服务器性能
单个cookie保存的数据不能超过4k,很多浏览器都限制一个站点最多保存20个cookie
Http和Https:
Http
超文本传输协议
默认端口号:80
Https
Http + ssl(安全套接字层)
默认端口号:443
Https比http更安全,但是性能更低(耗时更长)
Url的形式:
http请求格式:
http常见请求头:
常见响应状态码:
200:成功
302:转移至新的url
307:转移至新的url
404:not found
500:服务器内部错误
爬虫的分类:
通用爬虫:通常指搜索引擎的爬虫
聚焦爬虫:针对特定网站的爬虫
通用爬虫与聚焦爬虫的流程:
Robots协议:
网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取
浏览器发送Http请求的过程:
浏览器渲染出来的页面与爬虫请求的页面不一样
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

发表评论

暂时没有评论,来抢沙发吧~