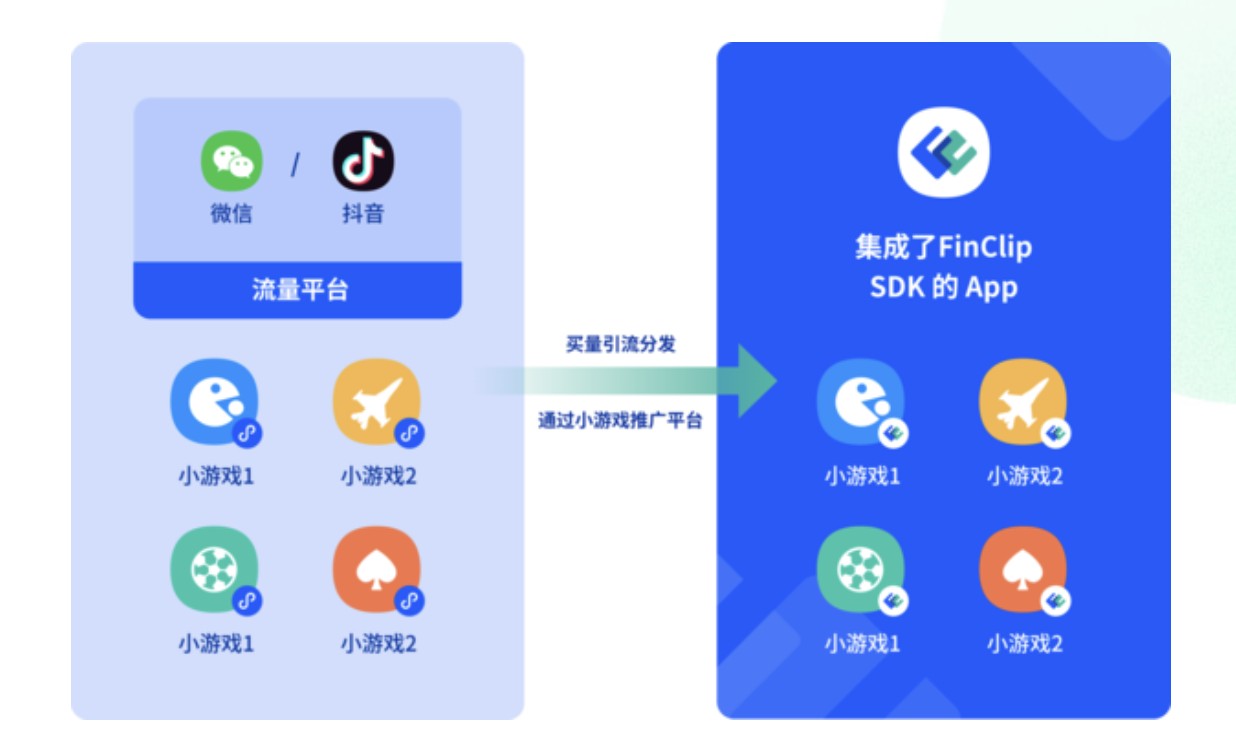
小程序容器助力企业在金融与物联网领域实现高效合规运营,带来的新机遇与挑战如何管理?
361
2023-12-05
这篇文章主要介绍“Oracle job定时任务怎么理解”,在日常操作中,相信很多人在Oracle job定时任务怎么理解问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Oracle job定时任务怎么理解”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!

Oracle job定时任务任务队列要能正常运行,还必须启动它自己专有的后台过程,参数如下:JOB_QUEUE_PROCESSES = n 这个是运行JOB时候所起的进程数,当然系统里面JOB大于这个数值后,就会有排队等候的,最小值是0,表示不运行JOB,最大值是1000,在OS上对应的进程时SNPn,9i以后OS上管理JOB的进程叫CJQn。可以使用下面这个SQL确定目前有几个SNP/CJQ在运行。SQL> set lines 200SQL> select * from v$bgprocess where name like CJQ%;PADDR PSERIAL# NAME DESCRIPTION ERROR---------------- ---------- ----- ---------------------------------------------------------------- ----------C0000005F4610F38 1 CJQ0 Job Queue Coordinator ##########这个paddr不为空的snp/cjq进程就是目前空闲的进程,有的表示正在工作的进程。三、DBMS_JOB包参数DBMS_JOB包中所有的过程都有一组相同的公共参数,用于定义任务,任务的运行时间以及任务定时运行的时间间隔。这些公共任务定义参数见表2所示。
下面我们来详细讨论这些参数的意义及用法。
1、job参数job是一个整数,用来唯一地标示一个任务。该参数既可由用户指定也可由系统自动赋予,这完全取决于提交任务时选用了哪一个任务提交过程。DBMS_JOB.SUBMIT过程通过获得序列SYS.JOBSEQ的下一个值来自动赋予一个任务号。该任务号是作为一个OUT参数返回的,所以调用者随后可以识别出提交的任务。而DBMS_JOB.ISUBMIT过程则由调用者给任务指定一个识别号,这时候,任务号的唯一性就完全取决于调用者了。除了删除或者重新提交任务,一般来说任务号是不能改变的。即使当数据库被导出或者被导入这样极端的情况,任务号也将被保留下来。所以在执行含有任务的数据的导入/导出操作时很可能会发生任务号冲突的现象。2、whatwhat参数是一个可以转化为合法PL/SQL调用的字符串,该调用将被任务队列自动执行。在what参数中,如果使用文字字符串,则该字符串必须用单引号括起来。 what参数也可以使用包含我们所需要字符串值的VARCHAR2变量。实际的PL/SQL调用必须用分号隔开。在PL/SQL调用中如果要嵌入文字字符串,则必须使用两个单引号。what参数的长度在Oracle7.3中限制在2000个字节以内,在Oracle 8.0以后,扩大到了4000个字节,这对于一般的应用已完全足够。该参数的值一般情况下都是对一个PL/SQL存储过程的调用。在实际应用中,尽管可以使用大匿名Pl/SQL块,但建议大家最好不要这样使用。还有一个实际经验就是最好将存储过程调用封装在一个匿名块中,这样可以避免一些比较莫名错误的产生。我来举一个例子,一般情况下,what参数可以这样引用:what =>’my_procedure(parameter1);’但是比较安全的引用,应该这样写:
what =>’begin my_procedure(parameter1); end;’任何时候,我们只要通过更改what参数就可以达到更改任务定义的目的。但是有一点需要注意,通过改变what参数来改变任务定义时,用户当前的会话设置也被记录下来并成为任务运行环境的一部分。如果当前会话设置和最初提交任务时的会话设置不同,就有可能改变任务的运行行为。意识到这个潜在的副作用是非常重要的,无论何时只要应用到任何DBMS_JOB过程中的what参数时就一定要确保会话设置的正确。3、next_dateNext_date参数是用来调度任务队列中该任务下一次运行的时间。这个参数对于DBMS_JOB.SUBMIT和DBMS_JOB.BROKEN这两个过程缺省为系统当前时间,也就是说任务将立即运行。当将一个任务的next_date参数赋值为null时,则该任务下一次运行的时间将被指定为4000年1月1日,也就是说该任务将永远不再运行。在大多数情况下,这可能是我们不愿意看到的情形。但是,换一个角度来考虑,如果想在任务队列中保留该任务而又不想让其运行,将next_date设置为null却是一个非常简单的办法。Next_date也可以设置为过去的一个时间。这里要注意,系统任务的执行顺序是根据它们下一次的执行时间来确定的,于是将next_date参数设置回去就可以达到将该任务排在任务队列前面的目的。这在任务队列进程不能跟上将要执行的任务并且一个特定的任务需要尽快执行时是非常有用的。4、IntervalInternal参数是一个表示Oracle合法日期表达式的字符串。这个日期字符串的值在每次任务被执行时算出,算出的日期表达式有两种可能,要么是未来的一个时间,要么就是null。这里要强调一点:很多开发者都没有意识到next_date是在一个任务开始时算出的,而不是在任务成功完成时算出的。当任务成功完成时,系统通过更新任务队列目录表将前面算出的next_date值置为下一次任务要运行的时间。当由interval表达式算出next_date是null时,任务自动从任务队列中移出,不会再继续执行。因此,如果传递一个null值给interval参数,则该任务仅仅执行一次。通过给interval参数赋各种不同的值,可以设计出复杂运行时间计划的任务。本文后面的“任务间隔和日期算法”将对interval表达式进行详细讨论,并给出一个实际有用interval表达式的例子。四、任务队列架构和运行环境当CJQn进程唤醒时,它首先查看任务队列目录中所有的任务是否当前的时间超过了下一次运行的日期时间。CJQn进程检测到需要该时间立即执行的任务后,这些任务按照下一次执行日期的顺序依次执行。当CJQn进程开始执行一个任务时,其过程如下:1.以任务所有者的用户名开始一个新的数据库会话。 2.当任务第一次提交或是最后一次被修改时,更改会话NLS设置和目前就绪的任务相匹配。 3.通过interval日期表达式和系统时间,计算下一次执行时间。4.执行任务定义的PL/SQL 5.如果运行成功,任务的下一次执行日期(next_date)被更新,否则,失败计数加1。 6.经过JOB_QUEUS_INTERVAL秒后,又到了另一个任务的运行时间,重复上面的过程。在前两步中,CJQn进程创建了一个模仿用户运行任务定义的PL/SQL的会话环境。然而,这个模仿的运行环境并不是和用户实际会话环境完全一样,需要注意以下两点:
第一,在任务提交时任何可用的非确省角色都将在任务运行环境中不可用。因此,那些想从非确省角色中取得权限的任务不能提交,用户确省角色的修改可以通过在任务未来运行期间动态修改来完成。
第二,任何任务定义本身或者过程执行中需要的数据库联接都必须完全满足远程的用户名和密码。CJQn进程不能在没有显式指明口令的情况下初始化一个远程会话。显然,CJQn进程不能假定将本地用户的口令作为远程运行环境会话设置的一部分。 当任务运行失败时,CJQn进程在1分钟后将再次试图运行该任务。如果这次运行又失败了,下一次尝试将在2分钟后进行,再下一次在4分钟以后。任务队列每次加倍重试间隔直到它超过了正常的运行间隔。在连续16次失败后,任务就被标记为中断的(broken),如果没有用户干预,任务队列将不再重复执行。五、任务队列字典表和视图任务队列中的任务信息可以通过表3所示的几个字典视图来查看,这些视图是由CATJOBQ.sql脚本创建的。表4和5是各个视图每个字段的含义。六、任务重复运行间隔设计算法任务重复运行的时间间隔取决于interval参数中设置的日期表达式。下面就来详细谈谈该如何设置interval参数才能准确满足我们的任务需求。一般来讲,对于一个任务的定时执行,有三种定时要求。1.在一个特定的时间间隔后,重复运行该任务。 2.在特定的日期和时间运行任务。 3.任务成功完成后,下一次执行应该在一个特定的时间间隔之后。 第一种调度任务需求的日期算法比较简单,即SYSDATE+n,这里n是一个以天为单位的时间间隔。表6给出了一些这种时间间隔设置的例子。表6所示的任务间隔表达式不能保证任务的下一次运行时间在一个特定的日期或者时间,仅仅能够指定一个任务两次运行之间的时间间隔。例如,如果一个任务第一次运行是在凌晨12点,interval指定为SYSDATE + 1,则该任务将被计划在第二天的凌晨12点执行。但是,如果某用户在下午4点手工(DBMS_JOB.RUN)执行了该任务,那么该任务将被重新定时到第二天的下午4点。还有一个可能的原因是如果数据库关闭或者说任务队列非常的忙以至于任务不能在计划的那个时间点准时执行。在这种情况下,任务将试图尽快运行,也就是说只要数据库一打开或者是任务队列不忙就开始执行,但是这时,运行时间已经从原来的提交时间漂移到了后来真正的运行时间。这种下一次运行时间的不断“漂移”是采用简单时间间隔表达式的典型特征。第二种调度任务需求相对于第一种就需要更复杂的时间间隔(interval)表达式,表7是一些要求在特定的时间运行任务的interval设置例子。第三种调度任务需求无论通过怎样设置interval日期表达式也不能满足要求。这时因为一个任务的下一次运行时间在任务开始时才计算,而在此时是不知道任务在何时结束的。遇到这种情况怎么办呢?当然办法肯定是有的,我们可以通过为任务队列写过程的办法来实现。这里我只是简单介绍以下,可以在前一个任务队列执行的过程中,取得任务完成的系统时间,然后加上指定的时间间隔,拿这个时间来控制下一个要执行的任务。这里有一个前提条件,就是目前运行的任务本身必须要严格遵守自己的时间计划。六、 实验概述目前,流行的主流数据库都拥有此项功能,最具代表性的是Microsoft SQL Server 7.0、Oracle8i/9i等。但是,要让Job工作,还需要我们加以配置才能实现。这些配置都有GUI操作。本文介绍Oracle9i之后通过命令行实现Job配置......
众所周知,一般操作系统会提供定时执行任务的方法,例如:Unix平台上提供了让系统定时执行任务的命令Crontab。但是,对于某些需求,例如:一些对数据库表的操作,最为典型的是证券交易所每日收盘后的结算,它涉及大量的数据库表操作,如果仍然利用操作系统去定时执行,不仅需要大量的编程工作,而且还会出现用户不一致等运行错误,甚至导致程序无法执行。
事实上,对于以上需求,我们可以利用数据库本身拥有的功能Job Queue(任务队列管理器)去实现。Job允许用户提前调度和安排某一任务,使其能在指定的时间点或时间段内自动执行一次或多次,由于任务在数据库中被执行,所以执行效率很高。
Job允许我们定制任务的执行时间,并提供了灵活的处理方式,还可以通过配置,安排任务在系统用户访问量少的时段内执行,极大地提高了工作效率。例如,对于数据库日常的备份、更新、删除和复制等耗时长、重复性强的工作,以及电信增值短信业务中的定时PUSH,我们就可以利用Job去自动执行以减少工作量。
目前,流行的主流数据库都拥有此项功能,最具代表性的是Microsoft SQL Server 7.0、Oracle8i/9i等。但是,要让Job工作,还需要我们加以配置才能实现。这些配置都有GUI操作。本文介绍Oracle9i以后通过命令行实现Job配置。
前提:写好的要定时执行的存储过程[不能带参数]。
定义一个Job,执行间隔是需要注意的一件重要的事情。SYSDATE+1/24 是存储在dba_jobs 视图中的间隔,它可以产生每小时一次的快照。可以将这个数据改变为不同的采样时间,在一天中有 24*60 = 1440 分钟,可以使用这个数字调整执行次数。比方说:我希望在每10分钟获取一次快照,应该使用下列命令:
execute dbms_job.submit(
:jobno, --作业编号
sp;, --执行的过程
trunc(sysdate+10/1440,MI), --下次执行时间
trunc(sysdate+10/1440,MI), --间隔时间
true, --no_parse
:instno);
1.创建JOB
创建一个任务,执行间隔是每5分钟。
Variable v_sn number;
Begin
dbms_job.submit(:v_sn,
p_push_send;,
trunc(sysdate+5/1440,MI),
trunc(sysdate+5/1440,MI));
commit;
end;
/
删除一个任务:
execute dbms_job.remove(jobno);
2.查询任务语句
涉及两个表:dba_jobs及dba_jobs_running
select * from dba_jobs;
select * from dba_jobs_running;
select job,what,to_char(last_date,yyyy-mm-dd HH24:mi:ss),to_char(next_date,yyyy-mm-dd HH24:m),interval from dba_jobs where job in (325,295)
select job,what,last_date,next_date,interval from dba_jobs where job in (1,3);3.必要的参数[修改initsid.ora参数]
job_queue_processes = 4 --可执行作业个数
job_queue_interval = 10 --默认间隔延迟时间10s
job_queue_keep_connections=true --job保持正常连接
修改可执行作业个数为20个:
ALTER SYSTEM SET JOB_QUEUE_PROCESSES = 2;0
修改取消限制模式:
ALTER SYSTEM DISABLE RESTRICTED SESSION;
4.相关的几个Job操作
删除job:
exec dbms_job.remove(jobno);
修改要执行的操作:
execdbms_job.what(jobno,what);
修改下次执行时间:
execdbms_job.next_date(job,next_date);
修改间隔时间:
execdbms_job.interval(job,interval);
停止job:
execdbms.broken(job,broken,nextdate);
启动job:
execdbms_job.run(jobno);
5. 关于Job 的延迟
Job都有不同程度的延迟,想完全排除这种误差最好使用操作系统的定时器crontab或者at,哈哈,开个玩笑。
A时间重叠的问题[网友论]:
比如我有两个JOB,都是在凌晨3点运行,那么如果其中一个在3点运行,那么另一个必须等待第一个JOB完成,然后才能执行。特别是有些象sysdate+1/24,这样每隔一小时运行的JOB就更容易冲突;即使没有时间重叠,ORACLE也是按job_queue_internal(通常是1分钟)的间隔进行检查JOB队列,这样1点钟的作业正好在3:00:45才检查到,那么就会在3:00:45才执行该job.我们知道ORACLE JOB如果第一次执行失败,那么按一定的时间间隔再次启动该JOB直到成功,如果直到运行16次还是失败,那么就中断该JOB,所以实际运行的时间会进行推迟。
B采用"精确定时"函数(从前面可能看到,其实是很难实现精确定时执行JOB的)
我们可以采用如trunc(sysdate)+(1+24)/25或trunc(sysdate)+25/24。表示每天1点执行job,这样就不会受上次JOB延时的影响。(没测过)。
6. 一个简单例子:
6.1 创建测试表
SQL> create table T(a date);
表已创建。
6.2 创建一个自定义过程
SQL> create or replace procedure MYPROC as
begin
insert into T values(sysdate);
end;
/
过程已创建。
6.3 创建JOB
SQL> variable job1 number;
SQL> begin
dbms_job.submit(:job1,MYPROC;,sysdate,sysdate+1/1440); --每天1440分钟,即一分钟运行test过程一次
end;
/
PL/SQL 过程已成功完成。
SQL> print job1;
JOB1
----------
3
6.4 运行JOB
SQL> begin
dbms_job.run(:job1);
end;
/
PL/SQL 过程已成功完成。
SQL>
----验证
SQL> select to_char(a,yyyy/mm/dd hh34:mi:ss) 时间 from T;
时间
-------------------
2017/11/09 14:54:14
SQL> alter session set nls_date_format=yyyy-mm-dd hh34:mi:ss;
Session altered.
SQL> select sysdate from dual;
SYSDATE
-------------------
2017-11-09 14:56:05
SQL> select to_char(a,yyyy/mm/dd hh34:mi:ss) 时间 from T;
时间
-------------------
2017/11/09 14:54:14
2017/11/09 14:55:14
SQL> select to_char(a,yyyy/mm/dd hh34:mi:ss) 时间 from T;
时间
-------------------
2017/11/09 14:54:14
2017/11/09 14:55:14
2017/11/09 14:56:14
SQL>
6.5 删除JOB
SQL> begin
dbms_job.remove(:job1);
end;
/
PL/SQL 过程已成功完成。
6.6 创建DBMS_JOB.submit注意点:
为什么刚刚创建后的JOB不能自动的执行呢?这是一个疏忽导致的!
在创建JOB的时候,需要在结尾处指定“COMMIT;”!表示创建完成之后便执行一次。
--删除之前的JOB,重新创建一个带有“COMMIT”语句的新JOB。
SQL> variable job1 number;
SQL> begin
dbms_job.submit(:job1,MYPROC;,sysdate,sysdate+1/1440);
commit;
end;
/
PL/SQL procedure successfully completed.
SQL>
SQL> print job1;
JOB1
----------
4
此次创建的JOB信息如下,可见LAST_DATE在创建完之后便有内容,表示已经被执行了一次。
SQL> col log_user for a10
SQL> col INTERVAL for a30
SQL> col what for a30
SQL> select job,log_user,to_char(last_date,yyyy-mm-dd hh34:mi:ss) last_date,to_char(next_date,yyyy-mm-dd hh34:mi:ss) next_date,interval, what from user_jobs;
JOB LOG_USER LAST_DATE NEXT_DATE INTERVAL WHAT
---------- ---------- ------------------- ------------------- ------------------------------ ------------------------------
4 SYS 2017-11-09 15:02:34 2017-11-09 15:03:34 sysdate+1/1440 MYPROC;
SQL>
SQL> select to_char(a,yyyy/mm/dd hh34:mi:ss) 时间 from T;
时间
-------------------
2017/11/09 14:54:14
2017/11/09 14:55:14
2017/11/09 14:56:14
2017/11/09 14:57:14
2017/11/09 14:58:14
2017/11/09 14:59:14
2017/11/09 15:00:32
2017/11/09 15:00:34
2017/11/09 15:01:34
2017/11/09 15:02:34
10 rows selected.
6.7 再次运行之前的未加commit的dbms_job.SUBMIT包
先删除:
SQL> begin
dbms_job.remove(:job1);
end;
/
PL/SQL procedure successfully completed.
SQL> select to_char(a,yyyy/mm/dd hh34:mi:ss) 时间 from T;
时间
-------------------
2017/11/09 14:54:14
2017/11/09 14:55:14
2017/11/09 14:56:14
2017/11/09 14:57:14
2017/11/09 14:58:14
2017/11/09 14:59:14
2017/11/09 15:00:32
2017/11/09 15:00:34
2017/11/09 15:01:34
2017/11/09 15:02:34
2017/11/09 15:03:34
时间
-------------------
2017/11/09 15:04:34
2017/11/09 15:05:34
2017/11/09 15:06:34
2017/11/09 15:07:34
15 rows selected.
SQL> select job,log_user,to_char(last_date,yyyy-mm-dd hh34:mi:ss) last_date,to_char(next_date,yyyy-mm-dd hh34:mi:ss) next_date,interval, what from user_jobs;
no rows selected
--运行dbms_job.submit:
SQL> variable job1 number;
SQL> begin
dbms_job.submit(:job1,MYPROC;,sysdate,sysdate+1/1440);
end;
/
PL/SQL procedure successfully completed.
SQL> print job1;
JOB1
----------
5
--查询user_jobs:
SQL> select job,log_user,to_char(last_date,yyyy-mm-dd hh34:mi:ss) last_date,to_char(next_date,yyyy-mm-dd hh34:mi:ss) next_date,interval, what from user_jobs;
JOB LOG_USER LAST_DATE NEXT_DATE INTERVAL WHAT
---------- ---------- ------------------- ------------------- ------------------------------ ------------------------------
5 SYS 2017-11-09 15:08:34 sysdate+1/1440 MYPROC;
SQL>
SQL> select to_char(a,yyyy/mm/dd hh34:mi:ss) 时间 from T;
时间
-------------------
2017/11/09 14:54:14
2017/11/09 14:55:14
2017/11/09 14:56:14
2017/11/09 14:57:14
2017/11/09 14:58:14
2017/11/09 14:59:14
2017/11/09 15:00:32
2017/11/09 15:00:34
2017/11/09 15:01:34
2017/11/09 15:02:34
2017/11/09 15:03:34
时间
-------------------
2017/11/09 15:04:34
2017/11/09 15:05:34
2017/11/09 15:06:34
2017/11/09 15:07:34
15 rows selected.
SQL>
注意:此处的LAST_DATE内容是空,表示此JOB没有被执行过,因此这个JOB将永远不会被自动的执行。
那么,如何才能使它自动执行起来呢?很简单,只要我们手动将这个JOB执行一下即可。到此,关于“Oracle job定时任务怎么理解”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注网站,小编会继续努力为大家带来更多实用的文章!
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

发表评论

暂时没有评论,来抢沙发吧~