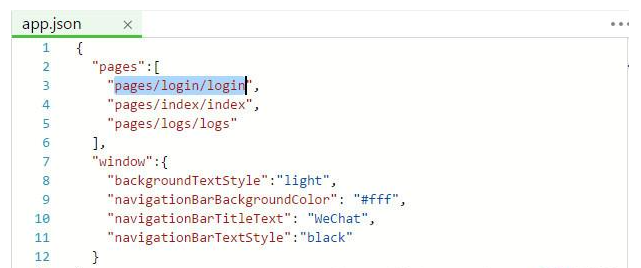
微信小程序本地存储与登录页面处理实例详细讲解
1873
2022-08-31

prometheus学习笔记(1)
")
目录
prometheus架构 3
部署 6
PromQL 9
PromQL的指标类型: 12
node_exporter 15
api 17
process_exporter 19
nohup ./blackbox_exporter --config.file="./blackbox.yml" --web.listen-address=":9115" --log.level=info > blackbox.log 2>&1 &
删除数据:
curl -X POST -g '-X POST -g 'API 调用并不会立即删除数据,实际数据任然还存在磁盘上,会在后面进行数据清理;要确定何时删除旧数据,可以使用--storage.tsdb.retention参数进行配置(默认情况下,Prometheus 会将数据保留15天);
curl -XPOST --web.listen-address=0.0.0.0:9999 --config.file=prometheus.yml --log.level=debug --web.enable-admin-api --web.enable-lifecycle
./promtool check config ./prometheus.yml
curl -XPOST io|processes|kernel parameters...),网络监控(网络设备|工作负载|网络延迟|丢包率));
中间件及基础设施类系统监控(消息中间件(kafka|rocketMQ|rabbitMQ),web服务容器(tomcat|jetty),数据库及缓存系统(mysql|postgresql|mongodb|elasticsearch|redis),数据库连接池(shardingShere等),存储系统(ceph等));
应用层监控,用于衡量应用程序代码的状态和性能;
业务层监控,用于衡量应用程序的价值,如电子商务网站上的销售量;QPS|DAU日活|转化率;业务接口|登录数|注册数|订单量|搜索量|支付量等;
云原生时代的可观测性:
可观测性系统(metrics指标监控(随时间推移产生的一些与监控相关的可聚合数据点),logging日志监控(离散式的日志或事件),tracing链接跟踪(分布式应用调用链跟踪));
CNCF将可观测性和数据分析归类一个单独的类别,且划分成了4个子类:
监控系统:以prometheus等为代表;
日志系统:以elasticsStack和PLG stack等为代表;
分布式调用链跟踪系统:以zipkin|jaeger|skywalking|pinpoint等为代表;
混沌工程系统:以chaosMonkey和chaosBlade等为代表;
著名的监控方法论:
google的四个黄金指标(常用于在服务级别帮助衡量终端用户体验、服务中断、业务影响等层面的问题|适用于应用及服务监控);
netflix的USE方法(全称为utilization saturation and errors method,主要用于分析系统性能问题,可指导用户快速识别资源瓶颈及错误的方法,应用于主机指标监控);
weave cloud的RED方法(Weave Cloud基于google的四个黄金指标的原则下结合prometheus及kubernetes容器实践,细化和总结的方法论,特别适合于云原生应用及微服务架构应用的监控和度量);
黄金指标(四个黄金指标源于google的SRE一书):
latency延迟(服务请求所需要的时长,如gregg提出,主要用于分析系统性能问题;
utilization使用率(关注系统资源的使用情况,这里的资源主要包括但不限于cpu|memory|network|disk等,100%的使用率通常是系统性能瓶颈的标志);
saturation饱和度(如cpu的平均运行排队长度,主要针对资源的饱和度(不同于4大黄金信号);任何资源在某种程度上的饱和都可能导致系统性能的下降);
errors错误(错误计数,如网卡在数据包传输过程中检测到的以太网网络冲突了14次);
RED方法:
是Weave Cloud在基于google的4个黄金指标的原则下结合prometheus及kubernetes容器实践,细化和总结的方法论,特别适合于云原生应用及微服务架构应用的监控和度量;
在4大黄金指标的原则下,RED方法可以有效地帮助用户衡量云原生及微服务应用下的用户体验问题;
RED方法主要关注以下3种关键指标:
request rate,每秒钟接收的请求数;
request errors,每秒失败的请求数;
request duration,每个请求所花费的时长;
prometheus架构
what is prometheus monitoring?
首先是一款time series时序数据库;内置了TSDB;默认只存1个月数据;建议使用外部的TSDB,remote storage;
但它的功能却并非止步于TSDB,而是一款设计用于进行target目标监控的关键组件;
结合生态系统内的其它组件,如pushgateway|altermanager|grafana等,可构成一个完整的IT监控系统;
go语言开发的;
时序数据简介:
时序数据,是在一段时间内通过重复measurement测量而获得的观测值的集合,将这些观测值绘制于图形之上,它会有一个数据轴和一个时间轴;
as our world gets increasingly instrumented, sensors and systems are constantly emitting a relentless stream of time series data;
weather records, economic indicators and patient health evolution metrics--all are time series data;
服务指标数据、应用程序性能监控数据、网络数据等也都是时序数据;
what does prometheus do?
基于call,从配置文件中指定的网络endpoint端点上周期性获取指标数据;
prometheus server周期性的从target上Pull数据;
How does prometheus work?
prometheus_server可通过3种方式从target上pull数据:exporters|instrumentation|pushagteway;
pull and push:
prometheus同其它TSDB相比,有一个非常典型的特性,它主动从target上pull数据,而非等待被监控端的push;
2种方式各有优劣,pull模型的优势在于:集中控制(有利于将配置集在prometheus server上完成,包括指标及采取速率等),根本目标在于收集在target上预先完成聚合的聚合型数据,而非一款由事件驱动的存储系统;
prometheus生态组件:
prometheus server负责时序型指标数据的采集及存储,但数据的分析、聚合及直观展示及告警等功能并非由prometheus server负责;
Rules and Alerts,即PromQL告警规则;
prometheus生态圈中包含了多个组件,其中部分组件可选:
prometheus server,收集和存储时间序列数据;
client library,为那些期望原生提供instrumentation功能的应用程序提供便捷的开发途径;
pushgateway,接收那些通常由短期作业生成的指标数据的网关,并支持由prometheus server进行指标拉取操作;
exporters,用于暴露现有应用程序或服务(不支持instrumentation)的指标给prometheus server;
alert manager,从prometheus server接收到告警通知后,通过去重、分组、路由等预处理功能后以高效向用户完成告警信息发送;
data visualization,proemtheus web UI(prometheus server内建)、grafana等;
service discover,动态发现待监控的target,从而完成监控配置的重要组件,在容器化环境中尤为有用,该组件目前由prometheus server内建支持;
prometheus数据模型:
prometheus仅用于以键值形式存储时序式的聚合数据,它并不支持存储文本信息;
其中的键称为metric指标,它通常意味着cpu速率|内存使用率|分区空闲比例等;
同一指标可能会适配到多个目标或设备,因而它使用标签作为元数据,从而为metric添加更多的信息描述维度;
这些标签还可作为过滤器进行指标过滤及聚合运算;
metric types指标类型:
prometheus使用4种方法来描述监控的指标:
counter计数器,用于保存单调递增型的数据,如站点访问次数等,不能为负值,也不支持减少,但可重置回0;
gauge仪表盘,用于存储有着起伏特征的指标数据,如内存空闲大小等,gauge是counter的超集,但存在指标数据丢失的可能性时,counter能让用户确切了解指标随时间的变化状态,而gauge则可能随时间流逝而精准度越来越低;
histogram直方图,它会在一段时间范围内对数据进行采样,并将其计入可配置的bucket之中,histogram能够存储更多的信息,包括样本值分布在每个bucket(bucket自身的可配置)中的数量,所有样本值之和及总的样本数量,从而prometheus能够使用内置的函数进行如下操作(计算样本平均值,以值的总和除以值的数量;计算样本分位值,分位数有助于了解符合特定标准的数据个数,如评估响应时长超过1s的请求比例,若超过20%即发送告警等);
summary摘要,histogram的扩展类型,但它是直接由被监测端自行聚合计算出分位数,并将计算结果响应给prometheus server的样本采集请求,因而其分位数计算是由监控端完成;
#
Counter,用于累计值,如记录请求数、任务完成数、错误发生次数;一直增加不会减少;重启进程后会被重置;
Gauge,常规数值,如温度变化、内存使用变化;可变大、可变小;重启进程后会被重置;
Histogram,柱状图,常用于跟踪事件发生的规模,如请求耗时、响应大小;特别之处是可以对记录的内容进行分组,提供count|sum全部值的功能,如{小于10=5次,小于20=1次,小于30=2次},count=8次,sum=8次的求和值;
Summary,和Histogram类似,常用于跟踪事件发生的规模,如请求耗时、响应大小,同样提供count|sum全部值的功能,如count=7次,sum=7次的值求和;它提供一个quantiles的功能,可按%比划分跟踪的结果,如quantile取值0.95,表示取采样值里面的95%数据;
Summary和Histogram的选择:
Summary结构有频繁的全局锁操作,对高并发程序性能存在一定影响,Histogram公是给每个桶做一个原子变量的计数就可以了,而Summary要每次执行算法计算出最新的X分位值是多少,算法需要并发保护,会占用客户端的cpu|memory;
不能对Summary产生的quantile值进行aggregation运算(如sum|avg),如有2个实例同时运行,都对外提供服务,分别统计各自的响应时间,最后分别计算出的0.5-quantile的值为60和80,这时如果简单的求平均(60+80)/2,认为是总体的0.5-quantile值,就错了;
Summary的百分位是提前在客户端里指定的,在服务端观测指标数据时不能获取未指定的分位数,而Histogram则可以通过promql随便指定,虽然计算的不如Summary准确,但带来了灵活性;
Histogram不能得到精确的分位数,设置的bucket不合理的话,误差会非常大,会消耗服务端的计算资源;
对比得到的结果,如果需要聚合选择Histogram,如果比较清楚要观测的指标的范围和分布情况,选择Histogram,如果需要精确的分位数选择Summary;
job作业和instance实例:
instance,能接收prometheus server数据scrape操作的每个网络endpoint端点,即为一个instance实例(instance实实在在工作的target,能吐出监控的数据;target配置的可作为instance的节点,可自动发现或直接配置);
job,具有类似功能的instance的集合称为一个job,如一个mysql主从复制集群中的所有mysql进程(多个同类型的instance(即target)称为一个job);
如:
cpu_usage{job="1", instance="128.0.0.1"}
cpu_usage{job="1", instance="128.0.0.1"}
cpu_usage{job="1", instance="128.0.0.2"}
PromQL:
prometheus query language,prometheus提供了内置的数据查询语言,支持用户进行实时的数据查询及聚合操作;
PromQL支持处理2种向量,并内置提供了一组用于数据处理的函数;
instant vector即时向量(最近一次的时间戳上跟踪的数据指标)|range vector时间范围向量(指定时间范围内的所有时间戳上的数据指标);
Alterts:
抓取到异常值后,prometheus支持通过alert告警机制向用户发送反馈或警示,以触发用户能够及时采取应对措施;
prmetheus server仅负责生成告警指示,具体的告警行为由另一个独立的应用程序alert manager负责;
告警指示由prometheus server基于用户提供的告警规则周期性计算生成;
alert manager接收到prometheus server发来的告警指示后,基于用户定义的告警路由route向告警接收人receivers发送告警信息;
部署
rpm方式(Centos上);
二进制方式;
tar xf prometheus-2.24.1.linux-amd64.tar.gz -C /usr/local/
./prometheus # 默认9090,勾选Enable autocomplete输入PromQL表达式
--web.read-timeout=5m # 请求链接的最大等待时间,防止太多的空闲链接占用资源
--web.max-cnotallow=512 # 最大链接数
--storage.tsdb.ratentinotallow=15d # prom开始采集监控数据后,会在内存和硬盘中对于保留期限的设置,很重要,太长的话硬盘和内存都吃不消,太短的话要查历史数据就没有了,企业中设置15d为宜
--storage.tsdb.path="data/" # 存储数据路径,重要,不要随便放在一个地方就执行,会把/塞满
--query.timeout=2m # 查询时优化设置,防止太多的用户同时查询,也防止单个用户执行过大的查询而一直不退出
--query.max-cnotallow=20
--web.enable-lifecycle # 热加载
--web.enable-admin-api
172.29.1.11:9090/metrics
172.29.1.11:9090 # Status下targets
node_cpu_seconds_total{mode='idle'}
node_exporter-1.0.1.linux-amd64.tar.gz
./node_exporter # 默认9100
cpu使用率:
(1-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by (instance)) * 100 # 5min内各主机的平均使用率
cpu的饱和度:
跟踪cpu的平均负载就能获取到相关主机的cpu饱和度,实际上,它是将主机上的cpu数量考虑在内的一段时间内的平均运行队列长度;
平均负载少于cpu的数量是正常情况,而长时间内超过cpu数量则表示cpu已然饱和;
cpu的满载率,不能长时间大于cpu核心数;
node_load1 > on (instance) 2* count(node_cpu_seconds_total){mode="idle"} by (instance) # 查询1min平均负载超过主机cpu数量两倍的时间序列
内存使用率:
node_exporter暴露了多个node_memory为前缀的指标,重点关注node_memory_MemTotal_bytes|node_memory_MemFree_bytes|node_memory_Buffers_bytes|node_memory_Cached_bytes;
计算使用率:
可用空间=node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes;
已用空间=node_memory_MemTotal_bytes - 可用空间;
使用率=已用空间/总空间;
MySQL exporter:
PromQL
prometheus时间序列:
时序数据:按时间顺序记录系统、设备状态变化的数据,每个数据称为一个样本;
数据采集以特定的时间周期进行,因而随着时间流逝,将这些样本数据记录下来,将生成一个离散的样本数据序列;
该序列也称为vector向量,而将多个序列放在同一个坐标内(以时间为M轴,以序列为纵轴),将形成一个由数据点组成的矩阵;
prometheus基于metric name指标名称及附属的labelset标签集唯一定义一条时间序列;
指标名称代表着监控目标上某类可测量属性的基本特征标识;
标签则是这个基本特征上两次细分的多个可测量维度;
基于PromQL表达式,用户可以针对指定的特征及其细分的维度进行过滤、聚合、统计等运算从而产生期望的计算结果;
PromQL是prometheus server内置数据查询语言;
PromQL使用expression表达式来表述查询需求;
根据其使用的指标和标签,及时间范围,表达式的查询请求可灵活地覆盖在一个或多个时间序列的一定范围内的样本之上,甚至是只包含单个时间序列的单个样本;
prometheus数据模型:
每个时间序列都由metric name指标名称和label标签来唯一标识,格式:
指标名称:通常用于描述系统上要测定的某个特征,如name的表示方式有2种:
method="GET"}
{__name__:"status="200", method="GET"} # 此种通常用于prometheus内部
指标名称和标签的特定组合代表着一个时间序列;
指标名称相同,但标签不同的组合分别代表着不同的时间序列;
不同的指标名称自然更是代表着不同的时间序列;
PromQL支持基于定义的指标维度进行过滤和聚合;
更改任何标签值,包括添加或删除标签,都会创建一个新的时间序列;
应该尽可能地保持标签的稳定性,否则很可能创建新的时间序列,更甚者会生成一个动态的数据环境,并使得监控的数据难以跟踪,从而导致建立在该指标之上的图形、告警及记录规则变得无效;
PromQL的数据类型:
PromQL的表达式中支持4种数据类型:
instant vector即时向量,特定或全部的时间序列集合上,具有相同时间戳的一组样本值称为即时向量;
range vector范围向量,特定或全部的时间序列集合上,在指定的同一时间范围内的所有样本值;
scalar标量,一个浮点型的数据值;
string字符串,支持使用单引号、双引号或反引号进行引用,但反引号不会对转义字符进行转义;
time series selectors时间序列选择器:
PromQL的查询操作需要针对有限个时间序列上的样本数据进行,挑选出目标时间序列是构建表达式时最为关键的一步;
用户可使用向量选择器表达式来挑选出给定指标名称下的所有时间序列或部分时间序列的即时(当前)样本值或至过去某个时间范围内的样本值,前者称为即时向量选择器,后者称为范围向量选择器;
instant vector selectors即时向量选择器,返回0个、1个或多个时间序列上的给定时间戳的各自的一个样本,该样本也可称为即时样本;
range vector selectors,返回0个、1个或多个时间序列上的给定时间范围内的各自的一组样本;
向量表达式使用要点:
表达式的返回值类型亦是即时向量、范围向量、标题或字符串4种数据类型其中之一,但有些使用场景要求表达式返回值必须满足特定的条件,如需要将返回值绘制成图形时,仅支持即时向量类型的数据,对于诸如rate一类的速率函数来说,其要求使用的却又必须是范围向量型的数据;
由于范围向量选择器的返回是范围向量型数据,它不能用于表达式浏览器中图形绘制功能,否则表达式浏览器会返回“Error executing query: invalid expression type "range vector" for range query, must be Scalar or instant Vector”一类的错误,事实上范围向量选择几乎问题结合速率类的rate函数一同使用;
range vector selectors范围向量一般用于聚合;绘图用即时向量;
即时向量选择器:
由2部分组成:指标名称:用于限定特定指标下的时间序列,即负责过滤指标,可选;matcher匹配器,或称为标签选择器,用于过滤时间序列上的标签,定义在{}之中,可选;
显然,定义即时向量选择器时,以上2个部分应至少给出一个,于是这将存在以下三种组合:
仅给定指标名称,或在标签名称上使用了空值的匹配器,返回给定的指标下的所有时间序列各自的即时样本,如method="get"},这些时间序列可能会有着不同的指标名称;
指标名称和匹配器的组合,返回给定的指定下的,且符合给定的标签过滤器的所有时间序列上的即时样本,如labels that are exactly equal to the provided string
!=,select labels that are not equal to the provided string
=~,select labels that regex-match the provided string
!~,select labels that do not regex-match the provided string
注意:
匹配到空标签值的匹配器时,所有未定义该标签的时间序列同样符合条件,如# 对于文本,使用单引号|双引号|反引号都可
node_cpu_seconds_total{cpu='0',mode=~'i.*'}
{cpu='0',mode=~'i.*'}可以,至少有一个不会匹配到空字符串的匹配器
{cpu=''} # 错误,匹配为空
范围向量选择器:
同即时向量选择器的唯一不同之处在于,范围向量选择器需要在表达式后紧跟一个方括号[]来表达需在时间时序上返回的样本所处的时间范围;
时间范围,以当前时间为基准时间点,指向过去一个特定的时间长度,如[5m]指5min之内;
时间格式,一个整数后紧跟一个时间单位,如5m,另ms、s、m、h、d、w周、y年,必须使用整数时间且能将多个不同级别的单位进行串联组合,以时间单位由大到小为顺序,如1h30m不能使用1.5目
注意,范围向量选择器返回的是一定时间范围内的数据样本,虽然不同时间序列的数据抓取时间点相同,但它们的时间戳并不会严格对齐,多个target上的数据抓取需要分散在抓取时间点前后一定的时间范围内,以均衡prometheus server的负载,因而prometheus在趋势上准确但并非绝对精准;
偏移量修改器:
默认即时向量选择器和范围向量选择器都以当前时间为基准时间点,而偏移量修改器能修改该基准;
偏移量修改器的使用方法是紧跟在选择器表达式之后使用offset关键字指定,offset 5m表示获取以offset 1d表示获取距此刻1天时间之前的5min之内的所有样本;
PromQL的指标类型:
prometheus server并不使用类型信息,而是将所有数据展平为时间序列;
有4个指标类型:
Counter计数器,单调递增,除非重置,如服务器或进程重启;
Gauge仪表盘,可增可减的数据;
Histogram直方图,将时间范围内的数据划分成不同的时间段,并各自评估其样本个数及样本值之和,因而可计算出分位数,可用于分析因异常值而引起的平均值过大的问题,分位数计算要使用专用的histogram_quantile函数;
Summary,类似于Histogram,但客户端会直接计算并上报分位数;
Counter:
通常,Counter的总数并没有直接作用,而是需要借助于rate|topk|increase|irate等函数来生成样本数据的变化状况(增长率);
rate(range-vector, t, scalar),可预测时间序列v在t秒后的值,它通过线性回归的方式来预测样本数据的Gauge变化趋势;
delta(v range-vector),计算范围向量中每个时间序列元素的第一个值与最后一个值之差,从而展示不同时间点上的样本值的差值,delta(cpu_temp_celsius{host="web01.test.com"}[2h]),返回该服务器上的cpu温度与2h之前的差异;
Histogram:
会在一段时间范围内对数据进行采样(通常是请求持续时长或响应大小等),并将其计入可配置的bucket(存储桶)中;
Histogram事先将特定测度可能的取值范围分隔为多个样本空间,并通过对落入bucket内的观测值进行计数及求和操作;
与常规方式略有不同的是,prometheus取值间隔的划分采用的是cumulative累积区间间隔机制,即每个bucket中的样本均包含了其前面所有bucket中的样本,因而也称为累积直方图,可降低histogram的维护成本,支持粗略计算样本值的分位数,单独提供了_sum和_count指标从而支持计算平均值;
Histogram类型的每个指标有一个基础指标名称
累积间隔机制生成的样本数据需要额外使用内置的histogram_quantile()函数即可根据Histogram指标来计算相应的分位数quantitle,即某个bucket的样本数在所有样本数中占据的比例,histogram_quantile()在计算分位数时会假定每个区间内的样本满足线性分布状态,因而它的结果仅是一个预估值,并不完全准确,预估的准确度取决于bucket区间划分的粒度,粒度越大,准确度越低;
Summary:
指标类型是客户端库的特性,而Histogram在客户端仅是简单的桶划分和分桶计数,分位数计算由prometheus server基于样本数据进行估算,因而其结果未必准确,甚至不合理的bucket划分会导致较大的误差;
Summary是一种类似于Histogram的指标类型,但它在客户端一段时间内(默认10min)的每个采样点进行统计,计算并存储了分位数数值,server端直接抓取相应值即可;
但Summary不支持sum或avg一类的聚合运算,而且其分位数由客户端计算并生成,server端无法获取客户端未定义的分位数,而Histogram可通过PromQL任意定义,有着较好的灵活性;
sum()|count()|topk()见prometheus2;
predict_linear(),根据前一个时间段的值来预测未来某个时间点数据的走势,如可根据近1天的磁盘使用来预测在未来2天增长情况,大概在未来多长时间可将磁盘占满,predict_linear(node_filesystem_free_bytes{device=”rootfs”,nodename=~”monitor01”,mountpoint=”/”}[1d], 2*86400)
1、cpu使用率监控:
(1-(avg(irate(node_cpu_seconds_total{nodename=~"api01",mode="idle"}[5m]))))*100
或
100-(avg(irate(node_cpu_seconds_total{instance=~"api01",mode="idle"}[5m]))*100)
2、内存使用率监控:
(1-(node_memory_MemAvailable_bytes{nodename="api01"})/node_memory_MemTotal_bytes{nodename="api01"})*100
或
(node_memory_MemTotal_bytes{nodename="api01"}-node_memory_MemAvailable_bytes{nodename="api01"})/node_memory_MemTotal_bytes{nodename="api01"}*100
如果将Buffers和Cached也作为可用内存,则内存使用率为:
(node_memory_MemTotal_bytes{nodename="api01"}-(node_memory_MemFree_bytes{nodename="api01"}+node_memory_Buffers_bytes{nodename="api01"}+node_memory_Cached_bytes{nodename="api01"}))/node_memory_MemTotal_bytes{nodename="api01"}*100
3、磁盘分区使用率监控:
(1-(node_filesystem_avail_bytes{nodename="api01",mountpoint="/"}/node_filesystem_size_bytes{nodename="api01",mountpoint="/"}))*100
4、CPU饱和度监控:
通常是按系统的平均负载来衡量,如观察主机cpu数量(通常按逻辑cpu来算)在一段时间内平均运行队列长度,当平均负载小于vCPU数量则认为是正常的,若负载长时间超出cpu的数量则认为cpu饱和;
cat /proc/cpuinfo | grep "physical id" | uniq | wc -l # 物理cpu数
cat /proc/cpuinfo | grep "cpu cores" | uniq # 每个物理cpu有多个核数
cat /proc/cpuinfo | grep "siblings" | uniq # 物理cpu下有多少个逻辑cpu数
cat /proc/cpuinfo | grep "processor" | wc -l # 所有物理cpu下的逻辑cpu个数
avg(node_load1{nodename="api01"} by (nodename)/count(node_cpu_seconds_total{nodename="api01",mode="system"}) by (nodename))
或
avg(node_load1{nodename="api01"})/count(node_cpu_seconds_total{nodename="api01",mode="system"})
5、内存饱和度
node_vmstat_pswpin # 系统每秒从磁盘读到内存的字节数
node_vmstat_pswpout # 系统每秒从内存写到磁盘的字节数
6、网卡接收|发送流量监控
irate(node_network_receive_bytes_total{nodename=~"api01",device=~"ens5"}[5m])*8
irate(node_network_transmit_bytes_total{nodename=~"api01",device=~"ens5"}[5m])*8
node_exporter
配置用户名密码认证,用htpasswd命令(yum -y install web.config.yaml
basic_auth_users:
的加密串
./node_exporter --web-otallow=./web.config.yaml
# vim prometheus.yml
scrape_configs:
- job_name: node
basic_auth:
username: node
password: node@2021
- targets:
- "localhost:9100"
count(node_cpu_seconds_total{mode="system"}) by (instance) # cpu核数
count(node_cpu_seconds_total{mode="system"}) by (instance,job)
up[5m] # 若采样间隔为15s,则5m获取到20个值
up[5m:1m] # 子查询,若采样间隔为15s,则5m获取到5个值,每1m1个值
prometheus_> bool 100 # 得到布尔值,结果是0或1(是>100)
node_cpu_present < bool node_mem_present # 得到布尔值
scrape_samples_scraped # 采集指标的数量
cat > /usr/lib/systemd/system/node_exporter.service << EOF
[Unit]
Descriptinotallow=node_exporter
[Service]
ExeStart=/usr/local/node_exporter/node_exporter \
--web.listen-address=:9100 \
--collector.systemd \
--collector.systemd.unit-whitelist="(ssh|docker|rsyslog|redis-server).service" \
--collector.textfile.directory=/usr/local/node_exporter/textfile.collected
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl enable node_exporter
systemctl start node_exporter.service
启动参数说明:
1、启用systemd收集器:
systemd收集器记录systemd中的服务和系统状态,需要通过参数--collector.systemd启用该收集器,如果不希望收集所有服务只收集部分关键服务,node_exporter在启动时可用--collector.systemd.unit-whitelist参数配置指定的服务;
2、指定textfile收集器目录:
使用textfile收集器可让用户添加自定义的度量指标,功能类似pushgateway,同zabbix中自定义的item一样,只要将度量指标和值按照prometheus规范的样式输出到指定位置且以.prom后缀文件保存,textfile收集器会自动读取collector.textfile.directory目录下所有以.prom结尾的文件,并提取所有格式为prometheus的指标暴露给prometheus来抓取;
textfile收集器默认是开启的,只需指定--collector.textfile.directory的路径即可,如--collector.textfile.directory=/usr/local/node_exporter/textfile.collected;
crontab中任务:
*/1 * * * * echo "node_login_users $(who | wc -l)" > /usr/local/node_exporter/textfile.collected/login_users.prom
*/1 * * * * echo "node_processes $(ps -ef | wc -l)" > /usr/local/node_exporter/textfile.collected/node_process.prom
3、启用或禁用收集器:
./node_exporter -h,可看到默认启用了哪些收集器(default: enabled),若要禁用某个收集器,如--collector.ntp,可修改为--no-collector.ntp即可;
4、只添加指定收集器:
node_exporter等各种收集器默认会收集非常多的指标数据,有很多并非我们所需要的,是可以不收集的,可在启动node_exporter时指定禁用某些收集器,也可在prometheus配置文件中的scrape_configs配置块下指定只收集哪些指标,使用场景,只有我们非常清楚每一个收集器用途时才使用该方法,官方推荐按默认收集所有数据,然后禁用不需要的收集器, 配置格式(详细配置在job_name: 'node_exporter'
static_configs:
- targets: ['node01:9100']
params:
collect[]:
- cpu
- meminfo
- netstat
- xfs
api
--web.enable-lifecycle # 生命周期管理
/-/healthy # GET,健康状态
/-/ready # GET,准备状态
/-/reload # PUT|POST,重新加载配置
/-/quit # PUT|POST,退出
--web.enable-admin-api # 管理员
/api/v1/admin/tsdb/snapshot # PUT|POST,快照,查询参数skip-head跳过头数据
/api/v1/admin/tsdb/delete_series # PUT|POST,查询参数match[]|start|end,数据并未真正从硬盘删除,后续在压缩时进行清理
/api/v1/admin/tsdb/clean_tombstones # PUT|POST,清理磁盘数据
查询:
/api/v1/query # GET|POST,即时向量查询,查询参数query(promql表达式),time(截止时间),timeout(超时时间),若query携带范围参数(如up[5m])api查询结果为范围向量
范围向量查询:
指标查询:
查询标签:
查询标签值
查询采集目标
查询规则
查询告警
查询采集目标元数据
查询元数据
查询告警管理器
查询配置信息
查询命令行配置
查询运行时信息
查询编译信息
查询TSDB状态
process_exporter
做进程监控,如某个服务的进程数、消耗了多少cpu|内存|IO资源等;
非官方出品,但能基本满足对进程监控的需求;
/usr/local/process_exporter/config.yaml
process_names:
- name: "{{.Matches}}"
cmdline:
- '/usr/sbin/zabbix_agentd'
- name: "{{.Matches}}"
cmdline:
- "SimpleHTTPServer'
- name: "{{.Matches}}"
cmdline:
- 'nginx'
- name: "{{.Matches}}"
cmdline:
- '/usr/bin/supervisord -c /etc/supervisord.conf'
- name: "{{.Matches}}"
cmdline:
- '/usr/local/prometheus/prometheus'
- name: "{{.Matches}}"
cmdline:
- '/usr/local/alertmanager/alertmanager'
- name: "{{.Matches}}"
cmdline:
- '/usr/local/node_exporter/node_exporter'
cat > /lib/systemd/system/process_exporter.service << EOF
[Unit]
Descriptinotallow=process-exporter
[Service]
ExecStart=/usr/local/process_exporter/process_exporter --config.path=/usr/local/process_exporter/config.yaml
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable process_exporter
systemctl start process_exporter # 9256port
vim /usr/local/prometheus/prometheus.yml
- job_name: 'process_exporter'
static_configs:
- targets: ['monitor01:9256']
labels:
app: process_exporter
nodename: monitor01
role: process_exporter
vim /etc/supervisord.d/process_exporter.ini
command=/usr/local/process_exporter/process_exporter -config.path=/usr/local/process_exporter/config.yaml
user=root
autostart=true ; 允许自动启动
autorestart=true ; 进程退出后自动重启
startsecs=5 ; 启动后运行5s后进程仍存在将被认为服务启动成功
exitcodes=0 ; 退出码
redirect_stderr=true ; 标准错误输出重定向到标准输出
stdout_logfile=/var/log/process_exporter.log
stdout_logfile_backups=5 ; 日志文件保留个数
supervisorctl -uadmin -p 12345 update
namedprocess_namegroup_num_procs{groupname=~".*prometheus.*"} # 进程数监控
sum(rate(namedprocess_namegroup_cpu_seconds_total{groupname=~".*prometheus.*"}[2m])) # 进程所占cpu监控,包括system和user两类
namedprocess_namegroup_memory_bytes{groupname=~".*prometheus.*",memtype="resident"} # 进程所常驻内存监控
rate(namedprocess_namegroup_read_bytes_total{groupname=~".*prometheus.*"}[2m]) # 进程磁盘读
rate(namedprocess_namegroup_write_bytes_total{groupname=~".*prometheus.*"}[2m]) # 进程磁盘写
prom的局限性:
prom是基于metric的监控,不适用于日志logs|事件event|调用链tracing;
默认是pull模型,合理规划网络,尽量不要转发;
对于集群化和水平扩展,官方和社区都没有银弹,需要合理选择federate|cortex|thanos等方案;
监控系统一般情况下可用性大于一致性,容忍部分副本数据丢失,保证查询请求成功,thanos去重;
prom不一定保证数据准确,不准确指:1、rate|histogram_quantile等函数会做统计和推断,产生一些反直觉的结果;2、查询范围过长要做降采样,势必会造成数据精度丢失,不过这是时序数据的特点,也是不同于日志系统的地方;
prom容量规划:
单机版内存问题:
# 计算公式
prom的内存消耗主要是因为每隔2h做一个block数据落盘,落盘之前所有数据都在内存里,因此和采集量有关;
加载历史数据时,是从磁盘到内存的,查询范围越大内存越大,这里面有一定的优化空间;
一些不合理的查询条件也会加大内存,如Group或大范围的rate;
./tsdb ls /data/prometheus/ # BLOCK_ULID|MIN_TIME|MAX_TIME|NUM_SAMPLES|NUM_CHUNKS|NUM_SERIES
NUM_SAMPLES数量超过了200万就不要单实例了,需做分片,然后通过Victoriametrics|Thanos|Trickster等方案合并数据;
评估哪些metric和label占用较多,去掉没用的指标,2.14以上可看tsdb状态;
查询尽量避免大范围查询,注意时间范围和step的比例,慎用Group;
如果需要关联查询,先想想能否通过Relabel的方式给原始数据多加个label,一条sql能查出来不用join,时序DB不是关系DB;
如
rate(prometheus_tsdb_compaction_chunk_size_bytes_sum[1h]) / rate(prometheus_tsdb_compaction_chunk_samples_sum[1h])
磁盘大小 = 保留时间*每秒获取样本数*样本大小 # retention_time_seconds保留时间和bytes_per_sample样本大小不变的情况下,如果想减少本地磁盘的容量需求,只能通过减少ingrested_samples_per_seconds每秒获取样本数的方式(1减少时间序列的数量,2增加采集样本的时间间隔,考虑到prom会对时间序列进行压缩,因此减少时间序列的数量效果更明显)
rate(prometheus_tsdb_head_samples_appended_total[1h]) # 当前每秒获取的样本数
redis-cli info | grep $1":" | cut -d ':' -f 2 #
redis-cli ping | grep -c PONG # 1 or 0
redis-server --version | cut -d " " -f 3 | cut -d "=" -f 2
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

发表评论

暂时没有评论,来抢沙发吧~