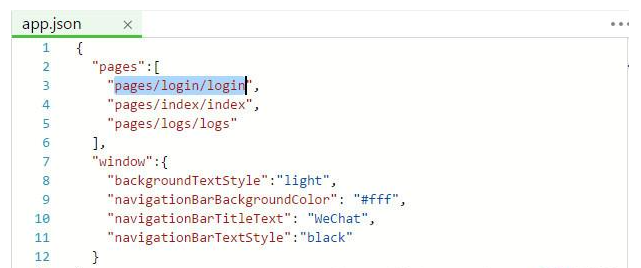
微信小程序本地存储与登录页面处理实例详细讲解
822
2022-08-28

redis集群复制和故障转移(rediscluster数据迁移方法)
")
一.集群的问题
1.当某个主节点宕机后,对应的槽位没有节点承担,整个集群处于失败状态,不可用,怎么办
2.如何判断某个主节点是否真正的岩机?
3.如果从某个主节点的所有从节点中选举出一个合适的节点作为新的主节点?
二.集群复制
1.复制原理与单节点的主从复制一样
2.从节点也是运行在集群模式下,所以安装主节点的方式配置即可
3.通过cluster meet把此节点添加到集群中去
4.在即将成为从节点的节点命令行执行cluster replicate
三.故障检测
1.集群中所有节点都会向其它节点发送PING消息,当在规定的时间内,没有收到对应的PONG消息,就把此节点标记为疑似下线
2.在发送的PING消息里面,会带着当前集群和节点的信息;通过这种方式,即可检测节点的存活,又能维护集群信息的统一性,不过有一定的时延
3.疑似下线不是真的下线,只有满足以下条件才是真的下线
主节点并且是被分配了slot槽位的主节点中有超过一半的节点都认为此节点疑似下线,才能真的下线
4.当某个节点通过消息得知有一个节点的疑似下线投票已经超过集群一半的时候,会发送一个标识此节点下线的广播消息
5.其它节点收到某节点已经下线的广播后,把自己内部的集群维护信息也修改为节点已下线状态
四.故障转移
1.从所有的从节点里面选举出一个新的主
2.选举出的新主会执行slaveof no one把自己的状态从slave变成master
3.撤销已下线的主节点的槽指派,并把这些槽位重新指派给自己
4.新的主节点向集群广播一条PONG消息,通过这个消息告诉所有集群节点:自己已经变成了主节点,接管了原来的主节点
5.新的主节点开始接收和处理与自己槽位相关的命令请求
五.如何从所有的从节点中选举产生新的主节点
1.每一次选举,配置纪元都会加一,从0开始
2.所有具备投票资格的节点在一次选举里面只能投一次票,并且是先到先得
条件一:主节点
条件二:被分配了槽位
3.当从节点发现自己所属的主节点宕机后,从节点会向集群广播一条CLUSTERMSGTYPE-FAILOVERAUTH-REQUEST的消息,要求具备投票资格的节点给自己投票
4.如果收到消息的节点具备资格,并且没有投过别的节点,则返回一条CLUSTERMSG-TYPE-FAILOVERAUTH-ACK消息,表示自己投票了
5.发起投票的节点计算自己收到的投票数,如果超过了一半,则自己变成主节点,执行故障转移操作
6.如果没有节点满足一半的要求,则配置纪元加一,重新进行选举
六.cluster的故障转移操作,截图展示
1.当前集群状态
127.0.0.1:6379> cluster nodes 9555a765592418cd9e975ace7df053d202bcc876 172.16.10.154:6379@16379 slave d0beb418f4682c1d93ab133df804626252fbc265 0 1542932936823 10 connected 0640b032745e6a0c5aae3fe1d5ad839a4f1fed7d 172.16.10.143:6379@16379 master - 0 1542932937000 2 connected 5803-10922 3e52dcc1694d213e47d0b7efbd1cb85fa69a8dba 172.16.10.142:6381@16381 slave 1f974aaa1ca841259b2f4c6ce6302f66b0aa2e27 0 1542932934000 11 connected afac608e5f37e399fe11bc5125a6f5a6548deef4 172.16.10.153:6379@16379 slave fea781a76cf0dc84b047bdee3f82112be362d483 0 1542932937825 12 connected d0beb418f4682c1d93ab133df804626252fbc265 172.16.10.142:6379@16379 myself,master - 0 1542932934000 9 connected 461-5460 1f974aaa1ca841259b2f4c6ce6302f66b0aa2e27 172.16.10.142:6380@16380 master - 0 1542932938827 11 connected 0-340 5461-5801 10923-11456 f7c1cf0ba03202dd9b6c520a038225d6dabbea5d 172.16.10.155:6379@16379 slave 0640b032745e6a0c5aae3fe1d5ad839a4f1fed7d 0 1542932935000 6 connected fea781a76cf0dc84b047bdee3f82112be362d483 172.16.10.144:6379@16379 master - 0 1542932936000 12 connected 341-460 5802 11457-16383
2.kill掉节点d0beb418f4682c1d93ab133df804626252fbc265 172.16.10.142:6379@16379 myself,master - 0 1542932934000 9 connected 461-5460
# 对应slave的log 172.16.10.154:6379 1058:S 23 Nov 08:34:51.104 # Connection with master lost. 1058:S 23 Nov 08:34:51.104 * Caching the disconnected master state. 1058:S 23 Nov 08:34:51.240 * Connecting to MASTER 172.16.10.142:6379 1058:S 23 Nov 08:34:51.240 * MASTER <-> SLAVE sync started 1058:S 23 Nov 08:34:51.240 # Error condition on socket for SYNC: Connection refused 1058:S 23 Nov 08:35:08.287 * Connecting to MASTER 172.16.10.142:6379 1058:S 23 Nov 08:35:08.287 * MASTER <-> SLAVE sync started 1058:S 23 Nov 08:35:08.287 # Error condition on socket for SYNC: Connection refused 1058:S 23 Nov 08:35:09.173 * FAIL message received from fea781a76cf0dc84b047bdee3f82112be362d483 about d0beb418f4682c1d93ab133df804626252fbc265 1058:S 23 Nov 08:35:09.174 # Cluster state changed: fail 1058:S 23 Nov 08:35:09.189 # Start of election delayed for 830 milliseconds (rank #0, offset 1912008). 1058:S 23 Nov 08:35:09.289 * Connecting to MASTER 172.16.10.142:6379 1058:S 23 Nov 08:35:09.289 * MASTER <-> SLAVE sync started 1058:S 23 Nov 08:35:09.289 # Error condition on socket for SYNC: Connection refused 1058:S 23 Nov 08:35:10.091 # Starting a failover election for epoch 13. 1058:S 23 Nov 08:35:10.093 # Failover election won: I'm the new master. 1058:S 23 Nov 08:35:10.094 # configEpoch set to 13 after successful failover 1058:M 23 Nov 08:35:10.094 # Setting secondary replication ID to 1dff33da4b26e7a3b350cc5eb3d1d908d6a40915, valid up to offset: 1912009. New replication ID is b328006d8d93ecdfb0d98d55cc0a01b897b17d95 1058:M 23 Nov 08:35:10.094 * Discarding previously cached master state. 1058:M 23 Nov 08:35:10.094 # Cluster state changed: ok
大概20秒后slave提升为master
3.其他节点的log
14818:M 23 Nov 08:35:06.313 * FAIL message received from fea781a76cf0dc84b047bdee3f82112be362d483 about d0beb418f4682c1d93ab133df804626252fbc265 14818:M 23 Nov 08:35:06.313 # Cluster state changed: fail 14818:M 23 Nov 08:35:07.232 # Failover auth granted to 9555a765592418cd9e975ace7df053d202bcc876 for epoch 13 14818:M 23 Nov 08:35:07.234 # Cluster state changed: ok
4.故障转以后的集群状态
172.16.10.153:6379> cluster nodes fea781a76cf0dc84b047bdee3f82112be362d483 172.16.10.144:6379@16379 master - 0 1542933587000 12 connected 341-460 5802 11457-16383 afac608e5f37e399fe11bc5125a6f5a6548deef4 172.16.10.153:6379@16379 myself,slave fea781a76cf0dc84b047bdee3f82112be362d483 0 1542933586000 4 connected 3e52dcc1694d213e47d0b7efbd1cb85fa69a8dba 172.16.10.142:6381@16381 slave 1f974aaa1ca841259b2f4c6ce6302f66b0aa2e27 0 1542933587455 11 connected 1f974aaa1ca841259b2f4c6ce6302f66b0aa2e27 172.16.10.142:6380@16380 master - 0 1542933588456 11 connected 0-340 5461-5801 10923-11456 d0beb418f4682c1d93ab133df804626252fbc265 172.16.10.142:6379@16379 master,fail - 1542933288229 1542933287000 9 disconnected 0640b032745e6a0c5aae3fe1d5ad839a4f1fed7d 172.16.10.143:6379@16379 master - 0 1542933588000 2 connected 5803-10922 9555a765592418cd9e975ace7df053d202bcc876 172.16.10.154:6379@16379 master - 0 1542933590459 13 connected 461-5460 f7c1cf0ba03202dd9b6c520a038225d6dabbea5d 172.16.10.155:6379@16379 slave 0640b032745e6a0c5aae3fe1d5ad839a4f1fed7d 0 1542933589458 6 connected
原slave 172.16.10.154:6379 提升为master,原master 172.16.10.142:6379 变为faild状态
5.重启开启原master
# 原master log,转变为slave,重新全量同步新的master 24809:M 23 Nov 08:45:08.078 # Configuration change detected. Reconfiguring myself as a replica of 9555a765592418cd9e975ace7df053d202bcc876 24809:S 23 Nov 08:45:08.078 * Before turning into a slave, using my master parameters to synthesize a cached master: I may be able to synchronize with the new master with just a partial transfer. 24809:S 23 Nov 08:45:08.078 # Cluster state changed: ok 24809:S 23 Nov 08:45:09.079 * Connecting to MASTER 172.16.10.154:6379 24809:S 23 Nov 08:45:09.079 * MASTER <-> SLAVE sync started 24809:S 23 Nov 08:45:09.079 * Non blocking connect for SYNC fired the event. 24809:S 23 Nov 08:45:09.080 * Master replied to PING, replication can continue... 24809:S 23 Nov 08:45:09.080 * Trying a partial resynchronization (request 1aa4d36b7bf6dcf3e87f41c5768436b8e26ccbb5:1). 24809:S 23 Nov 08:45:09.082 * Full resync from master: b328006d8d93ecdfb0d98d55cc0a01b897b17d95:1912008 24809:S 23 Nov 08:45:09.082 * Discarding previously cached master state. 24809:S 23 Nov 08:45:09.100 * MASTER <-> SLAVE sync: receiving 178 bytes from master 24809:S 23 Nov 08:45:09.100 * MASTER <-> SLAVE sync: Flushing old data 24809:S 23 Nov 08:45:09.100 * MASTER <-> SLAVE sync: Loading DB in memory 24809:S 23 Nov 08:45:09.100 * MASTER <-> SLAVE sync: Finished with success 24809:S 23 Nov 08:45:09.100 * Background append only file rewriting started by pid 24813 24809:S 23 Nov 08:45:09.122 * AOF rewrite child asks to stop sending diffs. 24813:C 23 Nov 08:45:09.123 * Parent agreed to stop sending diffs. Finalizing AOF... 24813:C 23 Nov 08:45:09.123 * Concatenating 0.00 MB of AOF diff received from parent. 24813:C 23 Nov 08:45:09.123 * SYNC append only file rewrite performed 24813:C 23 Nov 08:45:09.123 * AOF rewrite: 0 MB of memory used by copy-on-write 24809:S 23 Nov 08:45:09.179 * Background AOF rewrite terminated with success 24809:S 23 Nov 08:45:09.179 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB) 24809:S 23 Nov 08:45:09.179 * Background AOF rewrite finished successfully # master的log 1058:M 23 Nov 08:45:10.982 * Clear FAIL state for node d0beb418f4682c1d93ab133df804626252fbc265: master without slots is reachable again. 1058:M 23 Nov 08:45:11.964 * Slave 172.16.10.142:6379 asks for synchronization 1058:M 23 Nov 08:45:11.965 * Partial resynchronization not accepted: Replication ID mismatch (Slave asked for '1aa4d36b7bf6dcf3e87f41c5768436b8e26ccbb5', my replication IDs are 'b328006d8d93ecdfb0d98d55cc0a01b897b17d95' and '1dff33da4b26e7a3b350cc5eb3d1d908d6a40915') 1058:M 23 Nov 08:45:11.965 * Starting BGSAVE for SYNC with target: disk 1058:M 23 Nov 08:45:11.966 * Background saving started by pid 4063 4063:C 23 Nov 08:45:11.968 * DB saved on disk 4063:C 23 Nov 08:45:11.969 * RDB: 6 MB of memory used by copy-on-write 1058:M 23 Nov 08:45:11.983 * Background saving terminated with success 1058:M 23 Nov 08:45:11.983 * Synchronization with slave 172.16.10.142:6379 succeeded # 其他节点识别 14818:M 23 Nov 08:45:08.135 * Clear FAIL state for node d0beb418f4682c1d93ab133df804626252fbc265: master without slots is reachable again.
6.集群状态
3e52dcc1694d213e47d0b7efbd1cb85fa69a8dba 172.16.10.142:6381@16381 slave 1f974aaa1ca841259b2f4c6ce6302f66b0aa2e27 0 1542934118000 11 connected 0640b032745e6a0c5aae3fe1d5ad839a4f1fed7d 172.16.10.143:6379@16379 master - 0 1542934119000 2 connected 5803-10922 9555a765592418cd9e975ace7df053d202bcc876 172.16.10.154:6379@16379 master - 0 1542934118417 13 connected 461-5460 fea781a76cf0dc84b047bdee3f82112be362d483 172.16.10.144:6379@16379 master - 0 1542934120421 12 connected 341-460 5802 11457-16383 afac608e5f37e399fe11bc5125a6f5a6548deef4 172.16.10.153:6379@16379 slave fea781a76cf0dc84b047bdee3f82112be362d483 0 1542934120000 12 connected f7c1cf0ba03202dd9b6c520a038225d6dabbea5d 172.16.10.155:6379@16379 slave 0640b032745e6a0c5aae3fe1d5ad839a4f1fed7d 0 1542934116413 6 connected 1f974aaa1ca841259b2f4c6ce6302f66b0aa2e27 172.16.10.142:6380@16380 master - 0 1542934118000 11 connected 0-340 5461-5801 10923-11456 d0beb418f4682c1d93ab133df804626252fbc265 172.16.10.142:6379@16379 myself,slave 9555a765592418cd9e975ace7df053d202bcc876 0 1542934117000 9 connected
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

发表评论

暂时没有评论,来抢沙发吧~