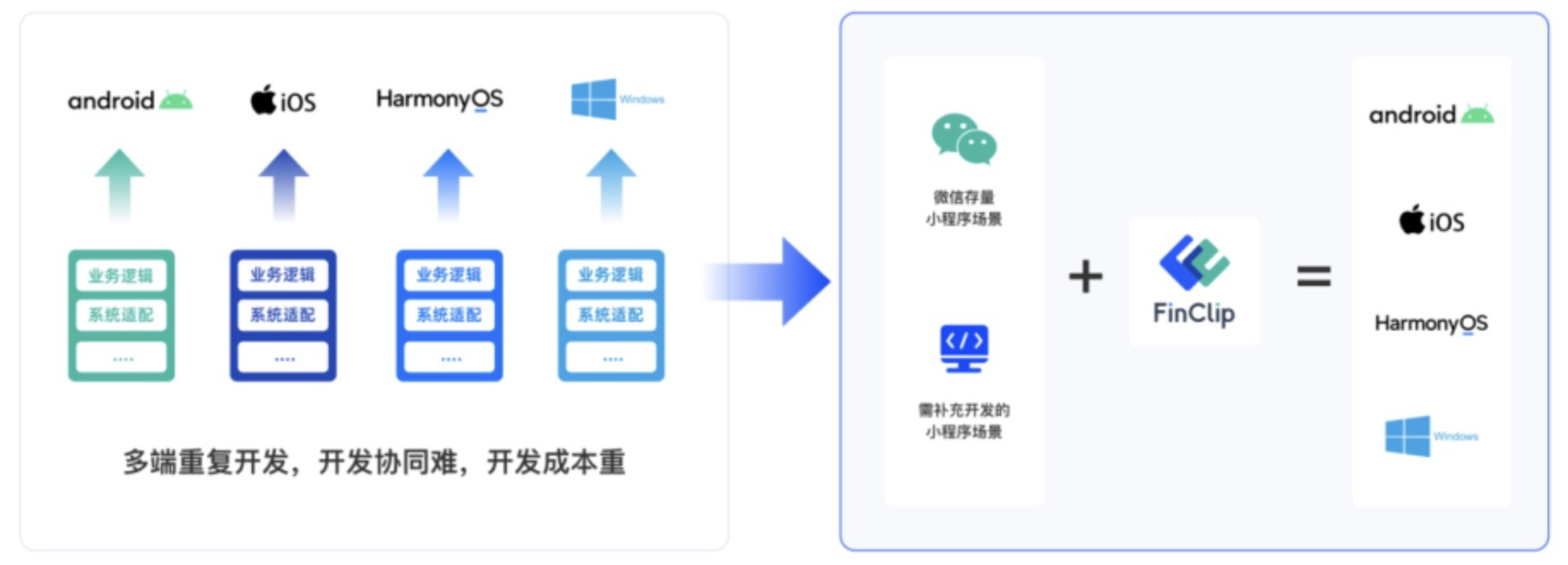
洞察了解前端三大主流框架如何影响企业跨平台小程序开发的效率与灵活性
896
2022-12-17

SpringBoot+Nacos+Kafka微服务流编排的简单实现

目录前言准备工作Nacos安装及使用入门准备三个SpringBoot服务,引入Nacos及Kafka业务解读Nacos配置创建配置读取配置监听配置改变总结
前言
最近一直在做微服务开发,涉及了一些数据处理模块的开发,每个处理业务都会开发独立的微服务,便于后面拓展和流编排,学习了SpringCloud Data Flow等框架,感觉这个框架对于我们来说太重了,维护起来也比较麻烦,于是根据流编排的思想,基于我们目前的技术栈实现简单的流编排功能。
简单的说,我们希望自己的流编排就是微服务可插拔,微服务数据入口及输出可不停机修改。
准备工作
Nacos安装及使用入门
自己学习的话推荐使用docker安装,命令如下
拉取镜像 docker pull nacos/nacos-server
创建服务 docker run --env MODE=standalone --name nacos -d -p 8848:8848 nacos/nacos-server
然后在浏览器输入 ip:8848/nacos 账号nacos 密码nacos
docker能够帮助我们快速安装服务,减少再环境准备花的时间
准备三个SpringBoot服务,引入Nacos及Kafka
配置文件
spring:
kafka:
bootstrap-servers: kafka-server:9092
producer:
acks: all
consumer:
group-id: node1-group #三个服务分别为node1 node2 node3
enable-auto-commit: false
# 部署的nacos服务
nacos:
config:
server-addr: nacos-server:8848
建议配置本机host 就可以填写xxx-server 不用填写服务ip
业务解读
我们现在需要对三个服务进行编排,保障每个服务可以插拔,也可以调整服务的位子示意图如下:
node1服务监听前置服务发送的数据流,输入的topic为前置数据服务输出topic
node2监听node1处理后的数据,所以node2监听的topic为node1输出的topic,node3同理,最终node3处理完成后将数据发送到数据流终点
我们现在要调整流程 移除node2-server,我们只需要把node1-sink改变成node2-sink即可,这样我们这几个服务就可以灵活的嵌入的不同项目的数据流处理业务中,做到即插即用(当然,数据格式这些业务层面的都是需要约定好的)
动态可调还可以保证服务某一节点出现问题时候,即时改变数据流向,比如发送到数暂存服务,避免Kafka中积累太多数据,吞吐不平衡
Nacos配置
创建配置
通常nVqBXSDX流编排里面每个服务都有一个输入及输出,分别为input及sink,所以每个服务我们需要配置两个topic,分别是input-topic output-topic,我们就在nacos里面添加输入输出配置
nacos配置项需要配置groupId,dataId,通常我们用服务名称作为groupId,配置项的名称作为dataId,如node1-server服务有一个input配置项,配置如下:
完成其中一个服务的配置,其它服务参考下图配置即可
读取配置
@Configuration
@NacosPropertySource(dataId = "input", groupId = "node1-server", autoRefreshed = true)
// autoRefreshed=true指的是nacos中配置发生改变后会刷新,false代表只会使用服务启动时候读取到的值
@NacosPropertySource(dataId = "sink", groupId = "node1-server", autoRefreshed = true)
public class NacosConfig {
@NacosValue(value = "${input:}", autoRefreshed = true)
private String input;
@NacosValue(value = "${sink:}", autoRefreshed = true)
private String sink;
public String getInput() {
return input;
}
public String getSink() {
return sink;
}
}
监听配置改变
服务的输入需要在服务启动时候创建消费者,在topic发生改变时候重新创建消费者,移除旧topic的消费者,输出是业务驱动的,无需监听改变,在每次发送时候读取到的都是最新配置的topic,因为在上面的配置类中autoRefreshed = true,这个只会刷新nacosConfig中的配置值,服务需要知道配置改变去驱动消费的创建业务,需要创建nacos配置监听
/**
* 监听Nacos配置改变,创建消费者,更新消费
*/
@Component
public class ConsumerManager {
@Value("${spring.kafka.bootstrap-servers}")
private String servers;
@Value("${spring.kafka.consumer.enable-auto-commit}")
private boolean enableAutoCommit;
@Value("${spring.kafka.consumer.group-id}")
private boolean groupId;
@Autowired
private NacosConfig nacosConfig;
@Autowired
private KafkaTemplate kafkaTemplate;
// 用于存放当前消费者使用的topic
private String topic;
// 用于执行消费者线程
private ExecutorService executorService;
/**
* 监听input
*/
@NacosConfigListener(dataId = "node1-server", groupId = "input")
public void inputListener(String input) {
// 这个监听触发的时候 实际NacosConfig中input的值已经是最新的值了 我们只是需要这个监听触发我们更新消费者的业务
String inputTopic = nacosConfig.getInput();
// 我使用nacosConfig中读取的原因是因为监听到内容是input=xxxx而不是xxxx,如果使用需要自己截取一下,nacosConfig中的内容框架会处理好,大家看一下第一张图的配置内容就明白了
// 先检查当前局部变量topic是否有值,有值代表是更新消费者,没有值只需要创建即可
if(topic != null) {
// 停止旧的消费者线程
executorService.shutdownNow();
executorService == null;
}
// 根据为新的topic创建消费者
topic = inputTopic;
ThreadFactory threadFactory = new ThreadFactoryBuilder().setNameFormat(topic + "-pool-%d").build();
executorService = new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue
// 执行消费业务
executorService.execute(() -> consumer(topic));
}
/**
* 创建消nVqBXSDX费者
*/
public void consumer(String topic) {
Properties properties = new Properties();
properties.put("bootstrap.servers", servers);
properties.put("enable.auto.commit", enableAutoCommit);
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("group.id", groupId);
KafkaConsumer
consumer.subscribe(Arrays.asList(topic));
try {
while (!Thread.currentThread().isInterrupted()) {
Duration duration = Duration.ofSeconds(1L);
ConsumerRecords
for (ConsumerRecord
String message = record.value();
// 执行数据处理业务 省略业务实现
String handleMessage = handle(message);
// 处理完成后发送到下一个节点
kafkaTemplate.send(nacosConfig.getSink(), handleMessage);
}
}
consumer.commitAsync();
}
} catch (Exception e) {
LOGGER.error(e.getMessage(), e);
} finally {
try {
consumer.commitSync();
} finally {
consumer.close();
}
}
}
}
总结
流编排的思路整体来说就是数据流方向可调,我们以此为需求,根据一些主流框架提供的api实现自己的动态调整方案,可以帮助自己更好的理解流编码思想及原理,在实际业务中,还有许多业务问题需要去突破,我们这样处理更多是因为服务可插拔,便于流处理微服务在项目灵活搭配,因为我现在工作是在传统公司,由于一些原因很难去推动新框架的使用,经常会用一些现有技术栈组合搞一些sao操作,供大家参考,希望大家多多指教。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。


发表评论

暂时没有评论,来抢沙发吧~