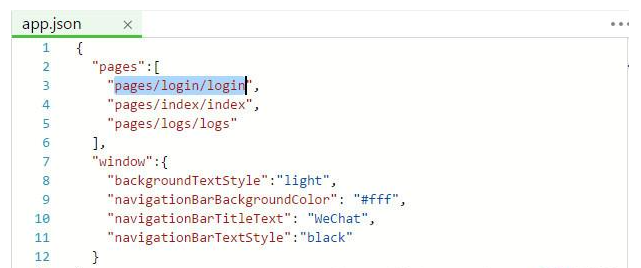
微信小程序本地存储与登录页面处理实例详细讲解
2320
2022-11-30

Prometheus 监控 CoreDNS

1、简介
prometheus 插件主要用于暴露CoreDNS相关的监控数据,除了coredns本身外,其他支持prometheus的插件(如cache插件)在启用的时候也可以通过prometheus插件暴露出相关的监控信息,默认情况下暴露出的监控数据在localhost:9153,路径为/metrics,配置文件中的每个server块只能使用一次prometheus。下面是一些coredns自身相关的指标:
coredns_build_info{version, revision, goversion} - 关于 CoreDNS 本身的信息coredns_panics_total{} - panics的总数coredns_dns_requests_total{server, zone, proto, family, type} - 总查询次数coredns_dns_request_duration_seconds{server, zone, type} - 处理每个查询的耗时coredns_dns_request_size_bytes{server, zone, proto} - 请求的大小(以bytes为单位)coredns_dns_do_requests_total{server, zone} - 设置了 DO 位的查询(queries that have the DO bit set)coredns_dns_response_size_bytes{server, zone, proto} - 响应的大小(以bytes为单位)coredns_dns_responses_total{server, zone, rcode} - 每个zone的响应码和数量coredns_plugin_enabled{server, zone, name} - 每个zone上面的各个插件是否被启用
需要注意的是上面频繁出现的几个标签(label),这里额外做一些解释:
zone:每个request/response相关的指标都会有一个zone的标签,也就是上述的大多数监控指标都是可以细化到每一个zone的。这对于需要具体统计相关数据和监控排查问题的时候是非常有用的server:是用来标志正在处理这个对应请求的服务器,一般的格式为
If monitoring is enabled, queries that do not enter the plugin chain are exported under the fake name “dropped” (without a closing dot - this is never a valid domain name).
2、监控 coreDNS:要寻找什么?
请求延迟:根据黄金信号,请求的延迟是检测服务质量下降的重要指标。要检查这一点,您必须始终将百分位数与平均值进行比较。在 Prometheus 中执行此操作的方法是使用运算符histogram。
histogram_quantile(0.99, sum(rate(coredns_dns_request_duration_seconds_bucket{job="kube-dns"}[5m])) by(server, zone, le))
错误率:错误率是您必须监控的另一个黄金信号。尽管错误并不总是由 DNS 故障引起的,但它仍然是您必须仔细观察的关键指标。coreDNS 关于错误的关键指标之一是coredns_dns_responses_total, 并且code也是相关的。例如,该NXDOMAIN错误表示 DNS 查询失败,因为查询的域名不存在。
coredns_dns_responses_total 响应状态码计数器。# TYPE coredns_dns_responses_total 计数器coredns_dns_responses_total{rcode="NOERROR",server="dns://:53",zone="."} 1336coredns_dns_responses_total{rcode="NXDOMAIN",server="dns://:53",zone="."} 471519
3、grafana配置dashboard
coredns原生支持的prometheus指标数量和丰富程度在众多DNS系统中可以说是首屈一指的,此外在grafana的官网上也有着众多href="list of pregenerated alerts is available here.
coredns
CoreDNSDown
CoreDNSDownannotations: message: CoreDNS has disappeared from Prometheus target discovery. runbook_url: | absent(up{job="kube-dns"} == 1)for: 15mlabels: severity: critical
CoreDNSLatencyHigh
CoreDNSLatencyHighannotations: message: CoreDNS has 99th percentile latency of {{ $value }} seconds for server {{ $labels.server }} zone {{ $labels.zone }} . runbook_url: | histogram_quantile(0.99, sum(rate(coredns_dns_request_duration_seconds_bucket{job="kube-dns"}[5m])) by(server, zone, le)) > 4for: 10mlabels: severity: critical
CoreDNSErrorsHigh
CoreDNSErrorsHighannotations: message: CoreDNS is returning SERVFAIL for {{ $value | humanizePercentage }} of requests. runbook_url: | sum(rate(coredns_dns_responses_total{job="kube-dns",rcode="SERVFAIL"}[5m])) / sum(rate(coredns_dns_responses_total{job="kube-dns"}[5m])) > 0.03for: 10mlabels: severity: critical
CoreDNSErrorsHigh
CoreDNSErrorsHighannotations: message: CoreDNS is returning SERVFAIL for {{ $value | humanizePercentage }} of requests. runbook_url: | sum(rate(coredns_dns_responses_total{job="kube-dns",rcode="SERVFAIL"}[5m])) / sum(rate(coredns_dns_responses_total{job="kube-dns"}[5m])) > 0.01for: 10mlabels: severity: warning
coredns_forward
CoreDNSForwardLatencyHigh
CoreDNSForwardLatencyHighannotations: message: CoreDNS has 99th percentile latency of {{ $value }} seconds forwarding requests to {{ $labels.to }}. runbook_url: | histogram_quantile(0.99, sum(rate(coredns_forward_request_duration_seconds_bucket{job="kube-dns"}[5m])) by(to, le)) > 4for: 10mlabels: severity: critical
CoreDNSForwardErrorsHigh
CoreDNSForwardErrorsHighannotations: message: CoreDNS is returning SERVFAIL for {{ $value | humanizePercentage }} of forward requests to {{ $labels.to }}. runbook_url: | sum(rate(coredns_forward_responses_total{job="kube-dns",rcode="SERVFAIL"}[5m])) / sum(rate(coredns_forward_responses_total{job="kube-dns"}[5m])) > 0.03for: 10mlabels: severity: critical
CoreDNSForwardErrorsHigh
CoreDNSForwardErrorsHighannotations: message: CoreDNS is returning SERVFAIL for {{ $value | humanizePercentage }} of forward requests to {{ $labels.to }}. runbook_url: | sum(rate(coredns_forward_responses_total{job="kube-dns",rcode="SERVFAIL"}[5m])) / sum(rate(coredns_forward_responses_total{job="kube-dns"}[5m])) > 0.01for: 10mlabels: severity: warning
CoreDNSForwardHealthcheckFailureCount
CoreDNSForwardHealthcheckFailureCountannotations: message: CoreDNS health checks have failed to upstream server {{ $labels.to }}. runbook_url: | sum(rate(coredns_forward_healthcheck_failures_total{job="kube-dns"}[5m])) by (to) > 0for: 10mlabels: severity: warning
CoreDNSForwardHealthcheckBrokenCount
CoreDNSForwardHealthcheckBrokenCountannotations: message: CoreDNS health checks have failed for all upstream servers. runbook_url: | sum(rate(coredns_forward_healthcheck_broken_total{job="kube-dns"}[5m])) > 0for: 10mlabels: severity: warning
CoreDNS : Embedded exporter (1 rules)
# CoreDNS Panic Count Number of CoreDNS panics encountered
- alert: CorednsPanicCount expr: increase(coredns_panics_total[1m]) > 0 for: 0m labels: severity: critical annotations: summary: CoreDNS Panic Count (instance {{ $labels.instance }}) description: "Number of CoreDNS panics encountered\n VALUE = {{ $value }}\n LABELS = {{ $labels }}"
Dashboards
Following dashboards are generated from mixins and hosted on github:
coredns
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
发表评论

暂时没有评论,来抢沙发吧~