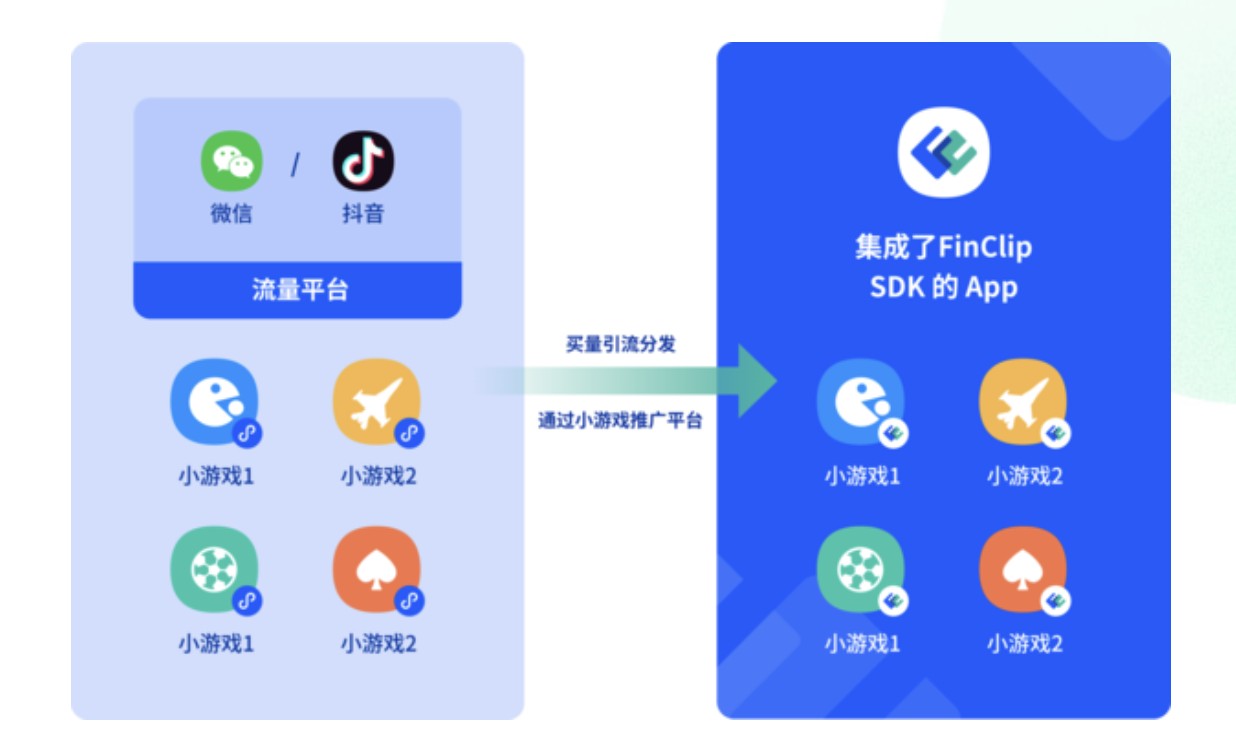
小程序容器助力企业在金融与物联网领域实现高效合规运营,带来的新机遇与挑战如何管理?
845
2022-11-29

JDBC批量插入数据的方法

一、使用Statement而不是PreparedStatement对象 JDBC驱动的最佳化是基于使用的是什么功能. 选择PreparedStatement还是Statement取决于你要怎么使用它们. 对于只执行一次的SQL语句选择Statement是最好的. 相反, 如果SQL语句被多次执行选用PreparedStatement是最好的. PreparedStatement的第一次执行消耗是很高的. 它的性能体现在后面的重复执行. 例如, 假设我使用Employee ID, 使用prepared的方式来执行一个针对Employee表的查询. JDBC驱动会发送一个网络请求到数据解析和优化这个查询. 而执行时会产生另一个网络请求. 在JDBC驱动中,减少网络通讯是最终的目的. 如果我的程序在运行期间只需要一次请求, 那么就使用Statement. 对于Statement, 同一个查询只会产生一次网络到数据库的通讯. 对于使用PreparedStatement池的情况下, 本指导原则有点复杂. 当使用PreparedStatement池时, 如果一个查询很特殊, 并且不太会再次执行到, 那么可以使用Statement. 如果一个查询很少会被执行,但连接池中的Statement池可能被再次执行, 那么请使用PreparedStatement. 在不是Statement池的同样情况下, 请使用Statement. 二、使用PreparedStatement的Batch功能 Update大量的数据时, 先Prepare一个INSERT语句再多次的执行, 会导致很多次的网络连接. 要减少JDBC的调用次数改善性能, 你可以使用PreparedStatement的AddBatch()方法一次性发送多个查询给数据库. 例如, 让我们来比较一下下面的例子. 例 1: 多次执行Prepared Statement
1. PreparedStatement ps = conn.prepareStatement(2. "INSERT into employees values (?, ?, ?)" );3. 4. for (n = 0 ; n < 100 ; n++) {5. 6. ps.setString(name[n]);7. ps.setLong(id[n]);8. ps.setInt(salary[n]);9. ps.executeUpdate();10. }例 2: 使用Batch 1. PreparedStatement ps = conn.prepareStatement(2. "INSERT into employees values (?, ?, ?)" );3. 4. for (n = 0 ; n < 100 ; n++) {5. 6. ps.setString(name[n]);7. ps.setLong(id[n]);8. ps.setInt(salary[n]);9. ps.addBatch();10. }11. ps.executeBatch();
在例 1中, PreparedStatement被用来多次执行INSERT语句. 在这里, 执行了100次INSERT操作, 共有101次网络往返. 其中,1次往返是预储statement, 另外100次往返执行每个迭代. 在例2中, 当在100次INSERT操作中使用addBatch()方法时, 只有两次网络往返. 1次往返是预储statement, 另一次是执行batch命令. 虽然Batch命令会用到更多的数据库的CPU周期, 但是通过减少网络往返,性能得到提高. 记住, JDBC的性能最大的增进是减少JDBC驱动与数据库之间的网络通讯.
注:Oracel 10G的JDBC Driver限制最大Batch size是16383条,如果addBatch超过这个限制,那么executeBatch时就会出现“无效的批值”(Invalid Batch Value) 异常。因此在如果使用的是Oracle10G,在此bug减少前,Batch size需要控制在一定的限度。
三、选择合适的光标类型
的光标类型以最大限度的适用你的应用程序. 本节主要讨论三种光标类型的性能问题.
对于从一个表中顺序读取所有记录的情况来说, Forward-Only型的光标提供了最好的性能. 获取表中的数据时, 没有哪种方法比使用Forward-Only型的光标更快. 但不管怎样, 当程序中必须按无次序的方式处理数据行时, 这种光标就无法使用了.
对于程序中要求与数据库的数据同步以及要能够在结果集中前后移动光标, 使用JDBC的Scroll-Insensitive型光标是较理想的选择. 此类型的光标在第一次请求时就获取了所有的数据(当JDBC驱动采用'lazy'方式获取数据时或许是很多的而不是全部的数据)并且储存在客户端. 因此, 第一次请求会非常慢, 特别是请求长数据时会理严重. 而接下来的请求并不会造成任何网络往返(当使用'lazy'方法时或许只是有限的网络交通) 并且处理起来很快. 因为第一次请求速度很慢, Scroll-Insensitive型光标不应该被使用在单行数据的获取上. 当有要返回长数据时, 开发者也应避免使用Scroll-Insensitive型光标, 因为这样可能会造成内存耗尽. 有些Scroll-Insensitive型光标的实现方式是在数据库的临时表中缓存数据来避免性能问题, 但多数还是将数据缓存在应用程序中.
Scroll-Sensitive型光标, 有时也称为Keyset-Driven光标, 使用标识符, 像数据库的ROWID之类. 当每次在结果集移动光标时, 会重新该标识符的数据. 因为每次请求都会有网络往返, 性能可能会很慢. 无论怎样, 用无序方式的返回结果行对性能的改善是没有帮助的.
现在来解释一下这个, 来看这种情况. 一个程序要正常的返回1000行数据到程序中. 在执行时或者第一行被请求时, JDBC驱动不会执行程序提供的SELECT语句. 相反, 它会用键标识符来替换SELECT查询, 例如, ROWID. 然后修改过的查询都会被驱动程序执行,跟着会从数据库获取所有1000个键值. 每一次对一行结果的请求都会使JDBC驱动直接从本地缓存中找到相应的键值, 然后构造一个包含了'WHERE ROWID=?'子句的最佳化查询, 再接着执行这个修改过的查询, 最后从服务器取得该数据行.
当程序无法像Scroll-Insensitive型光标一样提供足够缓存时, Scroll-Sensitive型光标可以被替代用来作为动态的可滚动的光标.
四、使用有效的getter方法
JDBC提供多种方法从ResultSet中取得数据, 像getInt(), getString(), 和getObject()等等. 而getObject()方法是最泛化了的, 提供了最差的性能。 这是因为JDBC驱动必须对要取得的值的类型作额外的处理以映射为特定的对象. 所以就对特定的数据类型使用相应的方法.
要更进一步的改善性能, 应在取得数据时提供字段的索引号, 例如, getString(1), getLong(2), 和getInt(3)等来替代字段名. 如果没有指定字段索引号, 网络交通不会受影响, 但会使转换和查找的成本增加. 例如, 假设你使用getString("foo") ... JDBC驱动可能会将字段名转为大写(如果需要), 并且在到字段名列表中逐个比较来找到"foo"字段. 如果可以, 直接使用字段索引, 将为你节省大量的处理时间.
例如, 假设你有一个100行15列的ResultSet, 字段名不包含在其中. 你感兴趣的是三个字段 EMPLOYEENAME (字串型), EMPLOYEENUMBER (长整型), 和SALARY (整型). 如果你指定getString(“EmployeeName”), getLong(“EmployeeNumber”), 和getInt(“Salary”), 查询旱每个字段名必须被转换为metadata中相对应的大小写, 然后才进行查找. 如果你使用getString(1), getLong(2), 和getInt(15). 性能就会有显著改善.
五、获取自动生成的键值
有许多数据库提供了隐藏列为表中的每行记录分配一个唯一键值. 很典型, 在查询中使用这些字段类型是取得记录值的最快的方式, 因为这些隐含列通常反应了数据在磁盘上的物理位置. 在JDBC3.0之前, 应用程序只可在插入数据后通过立即执行一个SELECT语句来取得隐含列的值.
例 3: JDBC3.0之前
//插入行int rowcount = stmt.executeUpdate ("insert into LocalGeniusList (name) values ('Karen')" );// 现在为新插入的行取得磁盘位置 - rowidResultSet rs = stmt.executeQuery ("select rowid from LocalGeniusList where name = 'Karen'" );
这种取得隐含列的方式有两个主要缺点. 第一, 取得隐含列是在一个独立的查询中, 它要透过网络送到服务器后再执行. 第二, 因为不是主键, 查询条件可能不是表中的唯一性ID. 在后面一个例子中, 可能返回了多个隐含列的值, 程序无法知道哪个是最后插入的行的值.
(译者:由于不同的数据库支持的程度不同,返回rowid的方式各有差异。在SQL Server中,返回最后插入的记录的id可以用这样的查询语句:SELECT @IDENTITY )
JDBC3.0规范中的一个可选特性提供了一种能力, 可以取得刚刚插入到表中的记录的自动生成的键值.
例 4: JDBC3.0之后
int rowcount = stmt.executeUpdate ("insert into LocalGeniusList (name) values ('Karen')" ,// 插入行并返回键值Statement.RETURN_GENERATED_KEYS);ResultSet rs = stmt.getGeneratedKeys ();// 得到生成的键值
现在, 程序中包含了一个唯一性ID, 可以用来作为查询条件来快速的存取数据行, 甚至于表中没有主键的情况也可以.
这种取得自动生成的键值的方式给JDBC的开发者提供了灵活性, 并且使存取数据的性能得到提升.
六、选择合适的数据类型
接收和发送某些数据可能代价昂贵. 当你设计一个schema时, 应选择能被最有效地处理的数据类型. 例如, 整型数就比浮点数或实数处理起来要快一些. 浮点数的定义是按照数据库的内部规定的格式, 通常是一种压缩格式. 数据必须被解压和转换到另外种格式, 这样它才能被数据的协议处理.
七、获取ResultSet
由于数据库系统对可滚动光标的支持有限, 许多JDBC驱动程序并没有实现可滚动光标. 除非你确信数据库支持可滚动光标的结果集, 否则不要调用rs.last()和rs.getRow()方法去找出数据集的最大行数. 因为JDBC驱动程序模拟了可滚动光标, 调用rs.last()导致了驱动程序透过网络移到了数据集的最后一行. 取而代之, 你可以用ResultSet遍历一次计数或者用SELECT查询的COUNT函数来得到数据行数.
通常情况下,请不要写那种依赖于结果集行数的代码, 因为驱动程序必须获取所有的数据集以便知道查询会返回多少行数据.
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

发表评论

暂时没有评论,来抢沙发吧~