
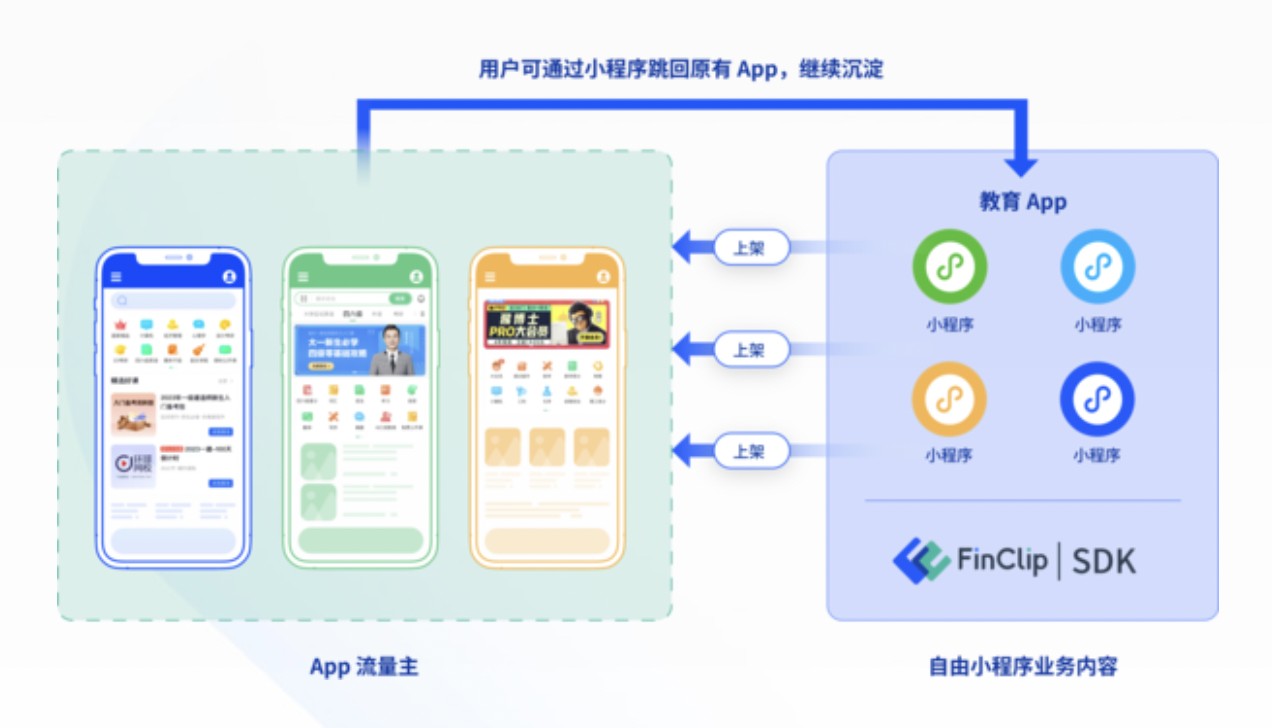
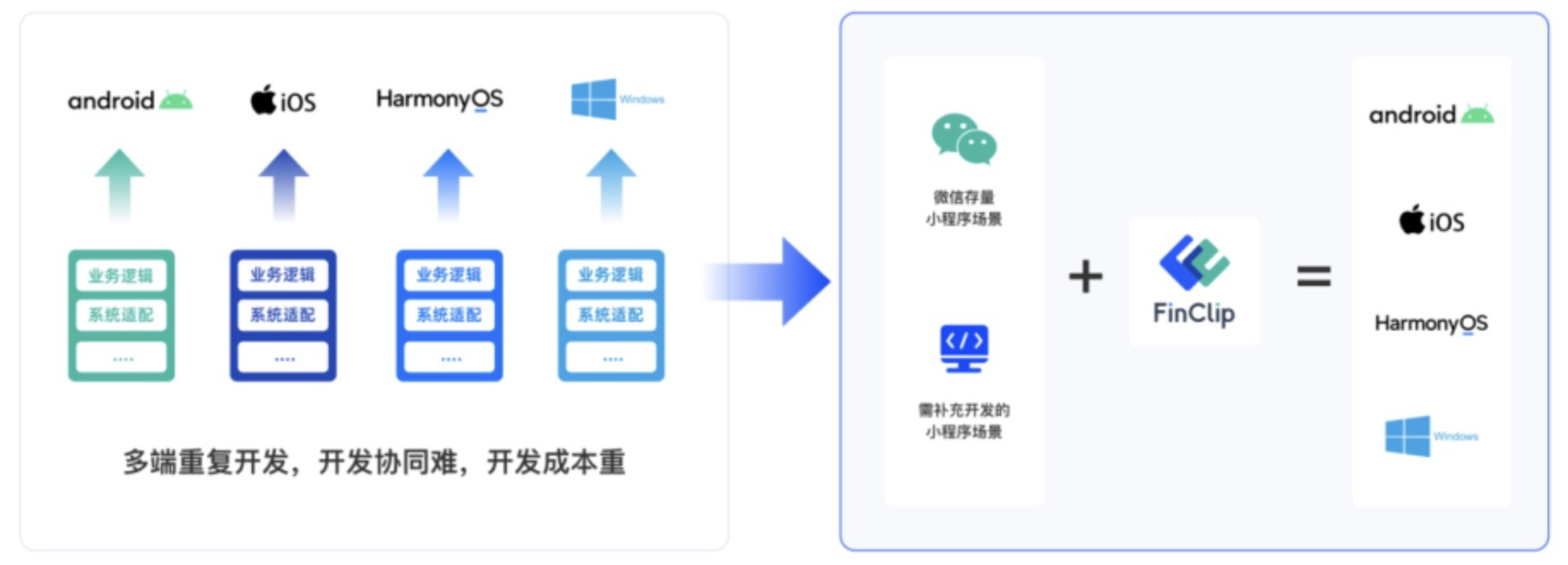
洞察探索如何通过一套代码实现跨平台小程序开发与高效管理,助力企业数字化转型
770
2022-11-27

浅谈为什么重写equals()就要重写hashCode()
就要重写hashCode()")
目录一、hashCode()方法二、equals()方法三、hashCode() 与 equals()3.1 不会创建“类对应的散列表”的情况3.2 会创建“类对应的散列表”的情况3.2.1 Set无法去重问题3.2.2 哈希冲突问题3.2.3 equals()和hashCode()完全对应3.2.4 进一步解释为什么重写equals()就要重写hashCode()四、重写hashCode()的目标五、面试金手指5.1 为什么重写equals()一定要重写hashCode()5.1.1 不会创建“类对应的散列表”的情况5.1.2 创建“类对应的散列表”的情况下5.2 hashCode()底层实现,一个好的哈希算法六、尾声
一、hashCode()方法
hashCode() 方法:
(1) 作用:用于判断两个对象是否相等;
(2) 实现:通过获取到的哈希码来确定该对象在哈希表中的索引位置,哈希码也称散列码,实际上就是返回一个int整数;
(3) Object类:hashCode() 定义在JDK的Object.java中,这就意味着Java中的任何类都包含有hashCode() 函数,并且通过调用hashCode()方法获取对象的hash值。
举个例子
public class DemoTest {
public static void main(String[] args) {
Object obj = new Object();
System.out.println(obj.hashCode());
}
}
这段代码中,obj引用就是通过调用hashCode()方法来获取对象的hash值。
二、equals()方法
equals()方法:
(1) 作用:用于判断两个对象是否相等;
(2) 实现:如果对象重写了equals()方法,重写的比较逻辑一般是比较两个对象的内容是否相等;如果没有重写,那就是比较两个对象的地址是否相同,等价于“==”;
(3) Object类:equals()定义在JDK的Object.java中,这就意味着Java中的任何类都包含有equals()函数,并且通过调用equals()方法比较两个引用相等,引用复制就相等,浅复制和深复制都不相等。
举个例子
public class DemoTest {
public static void main(String[] args) {
Object obj = new Object();
System.out.println(obj.equals(obj));
}
}
这段代码中,obj引用就是通过调用equals()方法来比较对象引用的。
三、hashCode() 与 equals()
接下面,我们讨论另外一个话题——hashCode() 和 equals() 这两个方法有什么关系?为什么重写equals就要重写hashcode?
3.1 不会创建“类对应的散列表”的情况
不会创建“类对应的散列表”的情况下,
(1) hashCode():hashCode()除了打印引用所指向的对象地址看一看,没有任何调用,重写hashCode()逻辑也没有用,反正没有调用;
(2) equals():equals()用来比较,可以自定义比较逻辑;
(3) 关系:hashCode()和equals()是两个独立方法,没有任何关系,所以不存在重写equals()要重写hashCode()。
这里所说的“不会创建类对应的散列表”是说:我们不会在HashSet, HashTable, HashMap等这些本质是散列表的数据结构中使用该类作为泛型。在这种情况下,该类的“hashCode() 和 equals() ”没有半毛钱关系。
小结:当我们不在HashSet, HashTable, HashMap等等这些本质是散列表的数据结构中用到这个类,此时,equals() 用来比较该类的两个对象是否相等,而hashCode() 则根本没有任何作用,所以,不用理会hashCode()。
举个例子
class Main2cumtomzieEquals {
public static void main(String[] args) {
Person p1 = new Person("eee", 100);
Person p2 = new Person("eee", 100);
Person p3 = new Person("aaa", 200);
System.out.printf(MGdopJw"p1.equals(p2) : %s; p1(%d) p2(%d)\n", p1.equals(p2), p1.hashCode(), p2.hashCode());
System.out.printf("p1.equals(p3) : %s; p1(%d) p3(%d)\n", p1.equals(p3), p1.hashCode(), p3.hashCode());
}
private static class Person {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
/**
* 重写equals方法
*/
@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
// 如果是同一个对象返回true,反之返回false
if (this == obj) {
return true; // 引用相同,返回为true
}
// 判断是否类型相同
if (this.getClass() != obj.getClass()) {
return false; // getClass() 不相同,为false
}
Person person = (Person) obj; // 引用赋值
return name.equals(person.name) && age == person.age; // name引用相同 && age引用相同
}
}
}
运行结果:
p1.equals(p2) : true; p1(2133927002) p2(1836019240)
p1.equals(p3) : false; p1(2133927002) p3(1625635731)
这段程序证明:对于当我们不在HashSet, HashTable, HashMap等等这些本质是散列表的数据结构中用到这个类作为泛型,此时,这个类的hashCode() 和 equals()没有任何关系,在p1和p2使用equals()比较相等的情况下,hashCode()也不一定相等。
小结:不会创建“类对应的散列表”的情况下,
对于hashCode():默认hashCode()仅仅返回一个int型哈希值,但是这个返回的哈希值没卵用;
对于equals():默认的equals)比较两个引用是否相等,而我们自己重写的equals用来比较两类的属性是否相等,因为引用赋值,所有最后两个属性int string一定是一样的
Person person = (Person) obj; // 引用赋值
return name.equals(person.name) && age == person.age; // name引用相同 && age引用相同
3.2 会创建“类对应的散列表”的情况
不会创建“类对应的散列表”的情况下,该类的“hashCode() 和 equals() ”是有关系的:
(1) 如果两个对象相等,那么它们的hashCode()值一定相同。这里的“对象相等”是指通过equals()比较两个对象时返回true。
(2) 如果两个对象hashCode()相等,它们的equals()不一定相等。因为在散列表中,hashCode()相等,即两个键值对的哈希值相等,然而哈希值相等,并不一定能得出键值对相等,此时就出现所谓的哈希冲突场景。
这里所说的“会创建类对应的散列表”是说:我们会在HashSet, HashTable, HashMap等等这些本质是散列表的数据结构中用到该类。
3.2.1 Set无法去重问题
自定义类作为HashSet的泛型,自定义类重写equals()不重写hashCode(),equals()的return true的范围比hashCode() return 哈希值范围大,导致HashSet中中出现重复元素,举个例子,如下:
import java.util.HashSet;
class Main3cumtomizeEquals {
public static void main(String[] args) {
Person p1 = new Person("eee", 100);
Person p2 = new Person("eee", 100);
Person p3 = new Person("aaa", 200);
// 新建HashSet对象
HashSet
set.add(p1);
set.add(p2);
set.add(p3);
// 比较p1 和 p2, 并打印它们的hashCode()
System.out.printf("p1.equals(p2) : %s; p1(%d) p2(%d)\n", p1.equals(p2), p1.hashCode(), p2.hashCode());
// 打印set
System.out.printf("set:%s\n", set);
}
private static class Person {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
/**
* 重写equals方法,当其 name引用相同 && age引用相同 的时候就认为它相同,
*/
@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
// 如果是同一个对象返回true,反之返回false
if (this == obj) {
return true; // 引用相同,返回为true
}
// 判断是否类型相同
if (this.getClass() != obj.getClass()) {
return false; // getClass() 不相同,为false
}
Person person = (Person) obj; // 引用赋值
return name.equals(person.name) && age == person.age; // name引用相同 && age引用相同
}
}
}
运行结果:
p1.equals(p2) : true; p1(2133927002) p2(1836019240)
set:[package1.Main3cumtomizeEquals$Person@6d6f6e28, package1.Main3cumtomizeEquals$Person@7f31245a, package1.Main3cumtomizeEquals$Person@135fbaa4]
结果分析:
问题:上面的程序中,重写了Person的equals(),但是,HashSet中仍然有重复元素:p1 和 p2。为什么会出现这种情况呢?
回答:因为虽然p1 和 p2的内容相等,但是它们的hashCode()不等,所以,HashMGdopJwSet在添加p1和p2的时候,认为它们不相等,从而导致存储HashSet存储重复元素。
3.2.2 哈希冲突问题
自定义类作为HashSet的泛型,自定义类重写equals()并重写hashCode(),hashCode() return 哈希值范围比equals() return true范围大,造成哈希冲突,举个例子,如下:
import java.util.HashSet;
class Main4cumtomizeEqualsAndhashcode {
public static void main(String[] args) {
// 新建Person对象
Person p1 = new Person("eee", 100);
Person p2 = new Person("eee", 100);
Person p3 = new Person("aaa", 200);
Person p4 = new Person("EEE", 100);
// 新建HashSet对象
HashSet
set.add(p1);
set.add(p2);
set.add(p3);
set.add(p4);
// 比较p1 和 p2, 并打印它们的hashCode()
System.out.printf("p1.equals(p2) : %s; p1(%d) p2(%d)\n", p1.equals(p2), p1.hashCode(), p2.hashCode());
// 比较p1 和 p4, 并打印它们的hashCode()
System.out.printf("p1.equals(p4) : %s; p1(%d) p4(%d)\n", p1.equals(p4), p1.hashCode(), p4.hashCode());
// 打印set
System.out.printf("set:%s\n", set);
}
private static class Person {
private String name;
private int age;
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
/**
* 重写equals方法,当其 name引用相同 && age引用相同 的时候就认为它相同
*/
@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
// 如果是同一个对象返回true,反之返回false
if (this == obj) {
return true; // 引用相同,返回为true
}
// 判断是否类型相同
if (this.getClass() != obj.getClass()) {
return false; // getClass() 不相同,为false
}
Person person = (Person) obj; // 引用赋值
return name.equals(person.name) && age == person.age; // name引用相同 && age引用相同
}
/**
* 重写hashCode方法,逻辑为 name的哈希值^age
*/
@Override
public int hashCode() {
// 68517 ^ 100 = 68545
// 64545 ^ 200 =68545
// 68517 ^ 100 =68545
int nameHash = name.toUpperCase().hashCode();
return nameHash ^ age; // ^ 异或运算,相同为0,不同为1
}
}
}
运行结果:
p1.equals(p2) : true; p1(68545) p2(68545) //
p1.equals(p4) : false; p1(68545) p4(68545) // hashcode相等,equals不相等,这样还是不好
set:[package1.Main4cumtomizeEqualsAndhashcode$Person@10bc1, package1.Main4cumtomizeEqualsAndhashcode$Person@10bc1, package1.Main4cumtomizeEqualsAndhashcode$Person@fce9]
结果分析:上面程序中,重写hashCode()的同时重写了equals(),equals()生效了,HashSet中没有重复元素。
因为在HashSet比较p1和p2时,HashSet会发现,它们的hashCode()相等,通过equals()比较它们也返回true,所以,HashSet将p1和p2被视为相等,不会存储多份。 同样地,在比较p1和p4时,HashSet发现:虽然它们的hashCode()相等,但是通过equals()比较它们返回false,所以,HashSet将p1和p4被视为不相等,p1和p4各存储一份。
3.2.3 equals()和hashCode()完全对应
上面代码好的修改方法(让equals和hashcode完全对应):
/**
* 重写equals方法,当其 name引用相同 &MGdopJwamp;& age引用相同 的时候就认为它相同,
*/
@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
// 如果是同一个对象返回true,反之返回false
if (this == obj) {
return true; // 引用相同,返回为true
}
// 判断是否类型相同
if (this.getClass() != obj.getClass()) {
return false; // getClass() 不相同,为false
}
Person person = (Person) obj; // 引用赋值
return name.equals(person.name) && age == person.age; // name引用相同 && age引用相同
}
/**
* 重写hashCode方法,逻辑为 name的哈希值^age
*/
@Override
public int hashCode() {
int nameHash = name.hashCode();
return nameHash ^ age; // ^ 异或运算,相同为0,不同为1
}
最后返回
p1.equals(p2) : true; p1(68545) p2(68545) // hashcode相等,equals相等
p1.equals(p4) : false; p1(68545) p4(68548) // hashcode不相等,equals不相等
set:[package1.Main4cumtomizeEqualsAndhashcode$Person@10bc1, package1.Main4cumtomizeEqualsAndhashcode$Person@10bc1, package1.Main4cumtomizeEqualsAndhashcode$Person@fce9]
3.2.4 进一步解释为什么重写equals()就要重写hashCode()
/**
* HashSet部分
*/
public boolean add (E e){
return map.put(e, PRESENT) == null;
}
/**
* map.put方法部分
*/
public V put (K key, V value){
return putVal(hash(key), key, value, false, true);
}
/**
* putVal方法部分
*/
final V putVal ( int hash, K key, V value,boolean onlyIfAbsent, boolean evict){
Node
Node
int n, i;
if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);
else {
Node
K k;
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p;
else if (p instanceof TreeNode) e = ((TreeNode
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) treeifyBin(tab, hash);
break;
}
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break;
p = e;
}
}
if (e != null) {
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null) e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold) resize();
afterNodeInsertion(evict);
return null;
}
由上面HashSet源码可知,HashSet使用的是HashMap的put方法,而hashMap的put方法,使用hashCode()用key作为参数计算出hash值,然后进行比较,如果相同,再通过equals()比较key值是否相同,如果相同,返回同一个对象。
所以,如果类使用再散列表的集合对象中,要判断两个对象是否相同,除了要覆盖equals()之外,也要覆盖hashCode()函数,否则,equals()无效。
所以,在HashSet中,一定要同时重写hashCode()和equals(),HashSet底层是由于HashMap的数据结构(数组+链表/红黑树)的比较逻辑决定的。
四、重写hashCode()的目标
理论上,一个好的hashCode的方法的目标:为不相等的对象(equals为false)产生不相等的散列码,而相等的对象(equals为true)必须拥有相等的散列码。
即equals和hashcode对应,向默认的那样,既不会出现hashcode相等,equals不相等的哈希冲突,也不会出现equals相等,hashcode不相等造成HashSet存放equals为truehttp://的元素。
实际上,一般来说,hashcode相等,equals不相等的哈希冲突还能忍受,但是equals相等造成hashcode不相等,造成HashSet存放相同是一定不能忍受的,就是说,重写equals放宽return true的同时一定要重写hashcode放宽return 哈希码。
以下验证本文中心问题:
(1) 把某个非零的常数值,比如17,保存在一个int型的result中。
(2) 对于每个关键域f(equals方法中设计到的每个域),为该域计算int类型的散列码,并
① 如果该域是boolean类型,则计算(f?1:0);
② 如果该域是byte,char,short或者int类型,计算(int)f;
③ 如果是long类型,计算(int)(f^(f>>>32));
④ 如果是float类型,计算Float.floatToIntBits(f);
⑤ 如果是double类型,计算Double.doubleToLongBits(f),然后再计算long型的hash值;
⑥ 如果是对象引用,则递归的调用域的hashCode,如果是更复杂的比较,则需要为这个域计算一个范式,然后针对范式调用hashCode,如果为null,返回0;
⑦ 如果是一个数组,则把每一个元素当成一个单独的域来处理。
(3) 执行result = 31 * result + name.hashcode(),并返回result。
(4) 编写单元测试验证有没有实现所有相等的实例都有相等的散列码。
给个简单的例子(一个好的hashCode()的使用):
@Overridepublic int hashCode() {
int result = 17;
result = 31 * result + name.hashCode();
return result;
}
这里再说下2.b中为什么采用31*result + c,乘法使hash值依赖于域的顺序,如果没有乘法那么所有顺序不同的字符串String对象都会有一样的hash值,而31是一个奇素数,如果是偶数,并且乘法溢出的话,信息会丢失,31有个很好的特性是31*i ==(i<<5)-i,即2的5次方减1,虚拟机会优化乘法操作为移位操作的。
五、面试金手指
5.1 为什么重写equals()一定要重写hashCode()
5.1.1 不会创建“类对应的散列表”的情况
当我们不在HashSet, HashTable, HashMap等这些本质是散列表的数据结构中,用到这个类作为泛型,此时,这个类的hashCode() 和 equals()没有任何关系;
equals()方法
(1) 作用: equals() 用来比较该类的两个对象是否相等。
(2) 实现:equals未被重写就直接进行引用比较,源码如下:
public boolean equals(Object obj) {
return (this == obj);
}
若equals已被重写,就按照自己的重写equals逻辑来。
hashCode():默认的hashcode()就是返回哈希值,但是此时返回的哈希值根本没有任何作用,不用理会hashCode()。
当我们不在HashSet, HashTable, HashMap等等这些本质是散列表的数据结构中,用到这个类作为泛型,这种情况下,
(1) 不重写equals,不重写hashCode()
equals直接比较引用,hashCode()也是直接返回对象地址, 所以,equals()与hashCode()完全对应,即对于两个引用:
① equals为true,hashCode()一定相等;
② equals为false,hashCode()一定不相等;
③ hashCode()相等,equals一定为true;
④ hashCode()不相等,equals一定为false。
(2) 重写equals()为比较对象的属性,不重写hashCode()
① 如果equals()相等,表示两个引用相等或两个引用指向的对象各个属性(基本类型+String)相等,hashcode()不一定相等(理由:因为一定要两个引用相等,指向的对象地址才相等)。
② 如果hashCode()相等,表示两个引用指向的对象哈希地址相等,则引用相等(因为哈对象哈希地址是任意分配的),equals()一定相等(未重写比较引用相等,已重写)。
③ 如果equals不相等,表示两个引用一定不相等,hashcode()两个引用所指向的对象地址一定不相等(因为哈希地址随机分配)。
④ 如果hashcode不相等,两个引用指向的对象地址不相等,equals()可以相等,可以不相等。
小结:不能说明equals()和hashCode()有关系,只是因为重写equals()把return true;的条件放宽了,只要两个引用指向的对象中属性相等就好,不一定引用相等,但是hashCode()还是返回对象地址。
5.1.2 创建“类对应的散列表”的情况下
当我们在HashSet, HashTable, HashMap等等这些本质是散列表的数据结构中,用到这个类,就是这个类作为集合框架的泛型,此时,这个类的hashCode() 和 equals()紧密相关;因为这些散列表数据结构,对其泛型,要求两个引用所指向的对象hashCode() 和 equals()均相同,才认为是同一个对象。
(1) 重写equals()为比较对象的属性,不重写hashCode()
equals()相等,hashcode()可以不相等:HashSet中放入两个相同就有相同属性的Person对象,两个Person对象属性相同,所以equals比较两个引用得到的结果相等,但是底层指向不同的对象地址,因此hashcode不相等,则HashSet在添加p1和p2的时候认为它们不相等,所以,HashSet中仍然有重复元素:p1 和 p2。
这说明默认的hashcode()不够好,一个好的哈希算法不应该让HashSet中有重复元素。因为要对应equals()的判断为true要和hashCode()的判断完全对应,默认的equals()和hashCode()就是比较引用和对象地址的,我们重写的equals()和hashCode(),是比较引用所指向的对象的个数属性的,总之,equals()和hashCode()要一一对应,所以重写equals()就要重写hashCode()。
(2) 重写equals为比较对象的属性,并且重写hashCode()
重写的equals():两个引用相等或者两个引用所指向的对象的属性相等,返回true,其余返回为false。
重写的hashCode(): name的哈希值^age,异或运算,相同为0,不同为1。
重写equals并且重写hashCode(),三种情况如下:
① equals相等,hashcode()不相等:HashSet集合中的内容相同的元素(这就是重写equals不重写hashcode带来的问题);
② equals相等,hashcode()相等:完全对应;
③ hashCode()相等,equals不相等:HashMap中的哈希冲突.
在完全对应的情况下,在HashSet看来:比较p1和p2,它们的hashCode()相等,通过equals()比较它们也返回true,所以p1和p2被视为相等;比较p1和p4,虽然它们的hashCode()相等;但是,通过equals()比较它们返回false,p1和p4被视为不相等。
小结:
(1) 不会创建“类对应的散列表”,hashcode除了打印引用所指向的对象地址看一看,没有任何调用,重写hashcode逻辑也没有用,反正没有调用,equals用来比较,可以自定义比较逻辑,hashcode和equals是两个独立方法,没有任何关系,不存在重写equals要重写hashcode。
(2) 当我们在HashSet, HashTable, HashMap等等这些本质是散列表的数据结构中,用到这个类,就是这个类作为集合框架的泛型,此时,这个类的hashCode() 和 equals()紧密相关,因为这些散列表数据结构,对其泛型,要求两个引用所指向的对象hashCode() 和 equals()均相同,才认为是同一个对象。
5.2 hashCode()底层实现,一个好的哈希算法
理论上,一个好的hashCode的方法的目标:为不相等的对象(equals为false)产生不相等的散列码,同样的,相等的对象(equals为true)必须拥有相等的散列码,即equals和hashcode对应,向默认的那样,既不会出现hashcode相等,equals不相等的哈希冲突,也不会出现equals相等,hashcode不相等造成HashSet存放equals为true的元素。
实践上,一般来说,hashcode相等,equals不相等的哈希冲突还能忍受,但是equals相等造成hashcode不相等,造成HashSet存放相同是一定不能忍受的,就是说,重写equals放宽return true;一定要重写hashcode放宽return 哈希码,验证本文中心问题,一定要hashcode范围和equals范围一样大,不能保证的化,就让hashcode范围比equals范围大,允许哈希冲突不允许HashSet存放重复元素。
六、尾声
为什么重写equals()就要重写hashCode(),完成了。
源代码工程地址:hashcode-equals_jb51.rar
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
发表评论

暂时没有评论,来抢沙发吧~