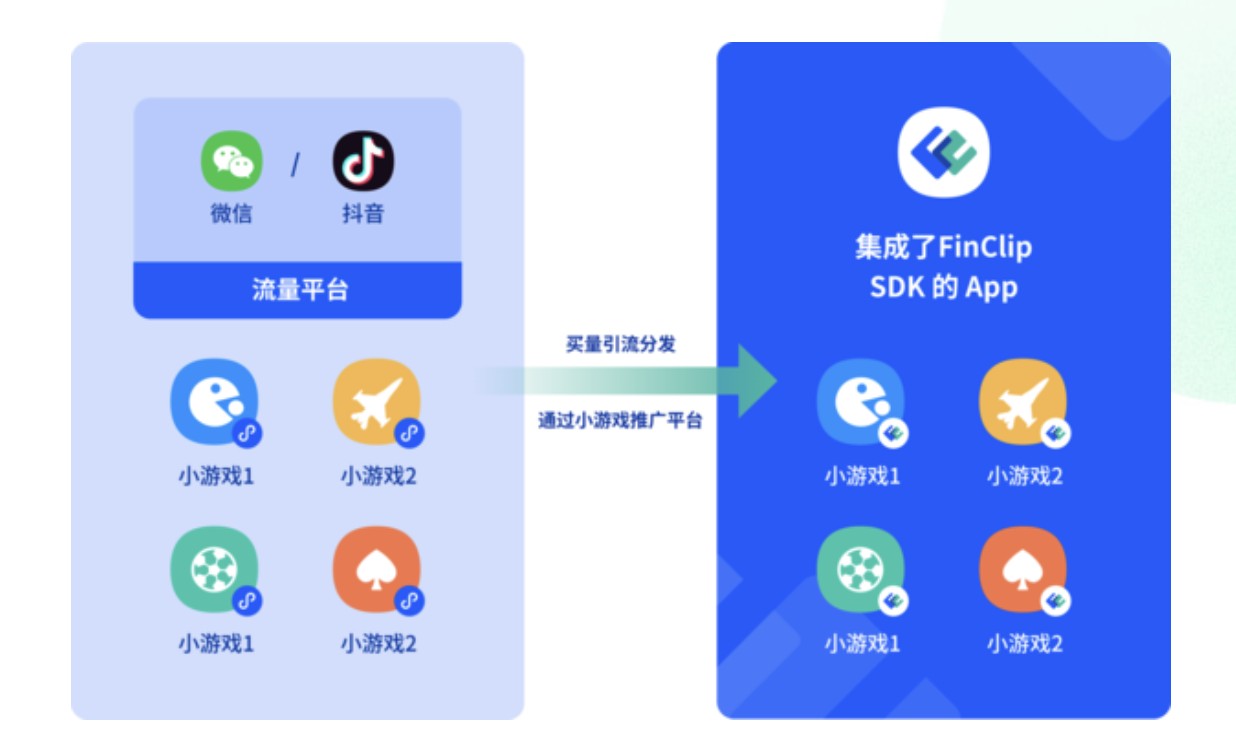
如何利用小游戏开发框架提升企业小程序的用户体验与运营效率
628
2022-11-26

python爬虫基础

文章目录
预备知识requestsretrying模块与cookie相关请求
预备知识
爬虫就是模拟客户端(浏览器)发送网络请求,获取响应,按照规则提取数据的程序
url = 请求协议+网站域名+资源的路径+参数
浏览器请求url地址:当前url对应的响应+js+css+图片—>elemennts中的内容 爬虫请求url地址:当前url对应的响应 elements的内容和爬虫获取到的url地址的响应不同,爬虫中需要以当前url地址对应的 响应为准提取数据
以明文的形式传输 效率较高,但是不安全 传输之前数据先加密,之后解密获取内容 效率较低,但是安全
get请求和post请求的区别 get请求没有请求体,post有,get请求把数据放在url地址中 post请求常用于登录注册 post请求携带的数据量比get请求大、多,常用语传输大文本的时候
1.请求行 2.请求头 user-agent(用户代理):对方服务器能够通过user-agent知道当前请求对方资源 的是什么浏览器。如果需要模拟手机版的浏览器发送请求, 对应的就需要把user-agent改成手机版。 cookie:用来存储用户信息,每次请求会被携带上发送给对方的浏览器 要获取登录后才能访问的页面 对方的服务器会通过cookie来判断我们是否是一个爬虫。 3.请求体 携带数据 get请求没有请求体 post请求有请求体 1.响应头 set-cookie:对方服务器通过该字段设置cookie到本地 2.响应体:url地址对应的响应
requests
发送get,post请求,获取响应 response = requests.get(url) #发送get请求,请求url地址对应的响应 response = requests.post(url, data={请求体的字典}) #发送post请求
response的方法 response.text:该方法往往会出现乱码,出现乱码使用response.encoding=“utf-8” response.content:获取网页的二进制字节流 response.content.decode():把相应的二进制字节流转化为str类型 response.request.url #发送请求的url地址 response.url #response响应的url地址 response.request.headers #请求头 response.headers #响应头
import requestsurl = "= requests.get(url)response.encoding = "utf-8" #获取网页的html字符串print(response.text)#print(response.content)仅仅获取网页内容,二进制字节流,需要解码print(response.content.decode())
import requestsurl = "= {"query": "你好", "from": "zh", "to": "en"}requests.post(url, data=query_string)print(response.contend.decode())
获取网页源码的正确打开方式(通过下面三种方式一定可以获取网页的源码) 1.response.content.decode() 2.response.content.decode(“gbk”) 3.response.encoding=“utf-8” , response.text
发送带header的请求 为了模拟浏览器,获取和浏览器一模一样的内容
import requestsurl = "= {"query": "你好", "from": "zh", "to": "en"}headers = {"User-Agent": "...", "Referer": "..."}response = requests.post(url, data=query_string, headers=headers)# 或 response = requests.get(url, headers=headers)print(response.content.decode())
使用超时参数 requests.get(url, headers=headers, timeout=3)#3秒之内必须返回响应,否则报错
retrying模块与cookie相关请求
retrying模块
from retrying import retry@retry(stop_max_attemp_number=3)def func1(): print("this is func1") raise ValueError("this is test error")
import requestsfrom retrying import retry"""专门请求url地址的方法"""headers = {"User-Agent": "Mozilla/5.0"}@retry(stop_max_attempt_number=3)#让被装饰的函数反复执行三次,三次全部报错才 #报错,如果有一次没抱错,就不会报错def _parse_url(url): response = requests.get(url, headers=headers, timeout=5) return response.content.decode()def parse_url(url): try: html_str = _parse_url(url) except: html_str = None return html_strif __name__ == '__main__': url = " print(parse_url(url)[:100])
处理cookie相关的请求 人人网{“email”: “mr_mao_hacker@163.com”,“password”: “alarmchime”} 直接携带cookie请求url地址 1.cookie放在headers中 headers = {“User-Agent”:"…", “Cookie”:“cookie字符串”}
2.cookie字典传给cookies参数 requests.get(url, cookies=cookie_dict)
先发送post请求,获取cookie,带上cookie请求登录后的页面 1.session = requests.session() #session具有的方法和requests一样 2.session.post(url, data, headers) #服务器设置在本地的cookie会保存在session 3.session.get(url)#会带上之前保存在session中的cookie,能够请求成功
improt requests#实例化sessionseesion = requests.session()#使用session发送post请求,获取对方保存在本地的cookiepost_url = "= {"User-Agent":"...", "Cookie":"cookie字符串"}post_data = {"email":"...", "password":"...."}session.post(post_url, headers=headers, data=post_data)#再使用session请求登录后的页面url = "= session.get(url, headers=headers)with open("renren3.html", 'w", encoding="utf-8") as f: f.write(response.contnet.decode())
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
发表评论

暂时没有评论,来抢沙发吧~