
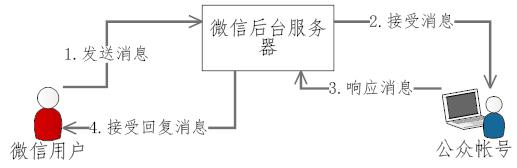
Asp.Net MVC 开发微信扫码支付详细步骤与教程
994
2022-11-23

基于大幅遥感图像的目标检测划框预测过程(水平框)
")
前言
划框预测
简单描述下预测的过程:
predict.py
import cv2import gcimport osfrom torch.autograd import Variablefrom eval.dataset_eval import build_dataloaderfrom effdet import EfficientDet, DetBenchEvalfrom effdet.config import get_efficientdet_configfrom effdet.efficientdet import HeadNetfrom eval.wbf import *from itertools import productfrom eval.tta import *def load_net(cfg): config = get_efficientdet_config(cfg.model_name) net = EfficientDet(config, pretrained_backbone=False) config.num_classes = cfg.num_classes config.image_size = cfg.image_size net.class_net = HeadNet(config, num_outputs=config.num_classes, norm_kwargs=dict(eps=.001, momentum=.01)) checkpoint = torch.load(cfg.checkpoint_path) net.load_state_dict(checkpoint['model_state_dict']) del checkpoint gc.collect() net = DetBenchEval(net, config) net.eval() return net.cuda()def make_predictions(images, net, score_threshold=0.11): images = Variable(torch.from_numpy(np.array(images)).cuda().float()) predictions = [] with torch.no_grad(): det = net(images, torch.tensor([1]*images.shape[0]).float().cuda()) for i in range(images.shape[0]): boxes = det[i].detach().cpu().numpy()[:, :4] scores = det[i].detach().cpu().numpy()[:, 4] indexes = np.where(scores > score_threshold)[0] boxes = boxes[indexes] boxes[:, 2] = boxes[:, 2] + boxes[:, 0] boxes[:, 3] = boxes[:, 3] + boxes[:, 1] predictions.append({ 'boxes': boxes[indexes], 'scores': scores[indexes], }) return [predictions]def make_tta_predictions(images, net, image_size, score_threshold=0.5): tta_transforms = [] for tta_combination in product([TTAHorizontalFlip(image_size), None], [TTAVerticalFlip(image_size), None], [TTARotate90(image_size), None]): tta_transforms.append(TTACompose([tta_transform for tta_transform in tta_combination if tta_transform])) with torch.no_grad(): images = Variable(torch.from_numpy(np.array(images)).cuda().float()) predictions = [] for tta_transform in tta_transforms: result = [] det = net(tta_transform.batch_augment(images.clone()), torch.tensor([1]*images.shape[0]).float().cuda()) for i in range(images.shape[0]): boxes = det[i].detach().cpu().numpy()[:,:4] scores = det[i].detach().cpu().numpy()[:,4] labels = det[i].detach().cpu().numpy()[:,5] indexes = np.where(scores > score_threshold)[0] boxes = boxes[indexes] boxes[:, 2] = boxes[:, 2] + boxes[:, 0] boxes[:, 3] = boxes[:, 3] + boxes[:, 1] boxes = tta_transform.deaugment_boxes(boxes.copy()) result.append({ 'boxes': boxes, 'scores': scores[indexes], 'labels': labels[indexes], }) predictions.append(result) return predictionsdef run_wbf(predictions, image_index, image_size=512, iou_thr=0.44, skip_box_thr=0.43, weights=None): boxes = [(prediction[image_index]['boxes']/(image_size-1)).tolist() for prediction in predictions] scores = [prediction[image_index]['scores'].tolist() for prediction in predictions] labels = [prediction[image_index]['labels'].tolist() for prediction in predictions] boxes, scores, labels = weighted_boxes_fusion(boxes, scores, labels, weights=None, iou_thr=iou_thr, skip_box_thr=skip_box_thr) boxes = boxes*(image_size-1) return boxes, scores, labelsdef run_wbf2(boxes, scores, labels, image_size, iou_thr=0.44, skip_box_thr=0.43): boxes = [(box/(image_size-1)).tolist() for box in boxes] scores = [score.tolist() for score in scores] labels = [label.tolist() for label in labels] boxes, scores, labels = weighted_boxes_fusion(boxes, scores, labels, weights=None, iou_thr=iou_thr, skip_box_thr=skip_box_thr) boxes = boxes*(image_size-1) return boxes, scores, labels# Color map for bounding boxes of detected objects from = {1: (0, 0, 255), 2: (0, 255, 0), 3: (255, 0, 0), 4: (255, 255, 0), 5: (0, 255, 255), 6: (50, 50, 50), 7: (0, 50, 50), 8: (50, 0, 50), 9: (100, 255, 100), 10: (255, 100, 255), 11: (0, 50, 50), 12: (0, 0, 50), 13: (50, 0, 0), 14: (100, 0, 100), 15: (0, 100, 255), 16: (0, 150, 255), 17: (150, 255, 0), 18: (255, 150, 0), 19: (255, 255, 150), 20: (150, 255, 255), }def get_key(dct, value): return [k for (k, v) in dct.items() if v == value]def mkdir(path): if not os.path.exists(path): os.mkdir(path)if __name__ == '__main__': import matplotlib.pyplot as plt import glob import tqdm from eval.config_eval import Config cfg = Config() imglist = glob.glob(f'{cfg.DATA_ROOT_PATH}/*.jpg') mkdir(cfg.out_dir) net = load_net(cfg) font = cv2.FONT_HERSHEY_SIMPLEX # 定义字体 font_size = 1 frame_size = cfg.image_size - cfg.gap for j, imgPath in tqdm.tqdm(enumerate(imglist)): image_name = os.path.split(imgPath)[-1].split('.')[0] image = cv2.imread(imgPath, cv2.IMREAD_COLOR) image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB).astype(np.float32) raw_image = image.copy() raw_h, raw_w = image.shape[:2] row = raw_h // frame_size + 1 col = raw_w // frame_size + 1 radius_h = row * frame_size - raw_h radius_w = col * frame_size - raw_w image = cv2.copyMakeBorder(image, 0, radius_h, 0, radius_w, cv2.BORDER_REFLECT) image = cv2.copyMakeBorder(image, 0, cfg.gap, 0, cfg.gap, cv2.BORDER_REFLECT) sample = raw_image.copy() boxes_, scores_, labels_ = [], [], [] for i in tqdm.tqdm(range(row)): for j in range(col): image1 = image.copy() subImg = image1[i * frame_size:(i + 1) * frame_size + cfg.gap, j * frame_size:(j + 1) * frame_size + cfg.gap, :] subImg /= 255.0 subImg = np.transpose(subImg, (2, 0, 1)) predictions = make_tta_predictions([subImg], net, cfg.image_size) index = 0 # subImg = subImg.transpose(1, 2, 0) boxes, scores, labels = run_wbf(predictions, image_index=index, image_size=cfg.image_size) print(labels) boxes = boxes.astype(np.int32).clip(min=0, max=cfg.image_size - 1) boxes[:, 0] = boxes[:, 0] + j * frame_size boxes[:, 1] = boxes[:, 1] + i * frame_size boxes[:, 2] = boxes[:, 2] + j * frame_size boxes[:, 3] = boxes[:, 3] + i * frame_size boxes_.append(boxes) scores_.append(scores) labels_.append(labels) # fig, ax = plt.subplots(1, 1, figsize=(16, 8)) # # for box, score, label in zip(boxes, scores, labels): # color = distinct_colors[label] # cv2.rectangle(sample, (box[0], box[1]), (box[2], box[3]), color, 3) # text_location = (box[0] + 2, box[1] - 4) # key = get_key(cfg.class_dict, label)[0] # sample = cv2.putText(sample, f'{key} {score * 100:.2f}%', text_location, font, # fontScale=0.5, color=color) # # plt.subplot(131) # plt.imshow(subImg) # plt.subplot(132) # plt.imshow(sample.astype(np.uint8)) # plt.subplot(133) # plt.imshow(image.astype(np.uint8)) # plt.show() boxes, scores, labels = run_wbf2(boxes_, scores_, labels_, image_size=cfg.image_size) fig, ax = plt.subplots(1, 1, figsize=(16, 8)) all_annotations = np.array([[box[0], box[1], box[2], box[3], score, label] for box, score, label in zip(boxes, scores, labels)]) # 丢弃原图像边界外的框 keep = (all_annotations[:, 0] < raw_w) & (all_annotations[:, 1] < raw_h) result_annotations = all_annotations[keep] # 限制xmax和ymax的值 result_annotations[:, 2] = np.clip(result_annotations[:, 2], 0, raw_w) result_annotations[:, 3] = np.clip(result_annotations[:, 3], 0, raw_h) for ann in result_annotations: color = distinct_colors[int(ann[5])] cv2.rectangle(sample, (int(ann[0]), int(ann[1])), (int(ann[2]), int(ann[3])), color, 3) text_location = (int(ann[0]) + 2, int(ann[1]) - 4) key = get_key(cfg.class_dict, ann[5])[0] sample = cv2.putText(sample, f'{key} {ann[4]*100:.2f}%', text_location, font, fontScale=0.5, color=color) plt.imshow(sample.astype(np.uint8)) plt.show()
wbf.py
# coding: utf-8__author__ = 'ZFTurbo: numpy as npdef bb_intersection_over_union(A, B): xA = max(A[0], B[0]) yA = max(A[1], B[1]) xB = min(A[2], B[2]) yB = min(A[3], B[3]) # compute the area of intersection rectangle interArea = max(0, xB - xA) * max(0, yB - yA) if interArea == 0: return 0.0 # compute the area of both the prediction and ground-truth rectangles boxAArea = (A[2] - A[0]) * (A[3] - A[1]) boxBArea = (B[2] - B[0]) * (B[3] - B[1]) iou = interArea / float(boxAArea + boxBArea - interArea) return ioudef prefilter_boxes(boxes, scores, labels, weights, thr): # Create dict with boxes stored by its label new_boxes = dict() for t in range(len(boxes)): for j in range(len(boxes[t])): score = scores[t][j] if score < thr: continue label = int(labels[t][j]) box_part = boxes[t][j] b = [int(label), float(score) * weights[t], float(box_part[0]), float(box_part[1]), float(box_part[2]), float(box_part[3])] if label not in new_boxes: new_boxes[label] = [] new_boxes[label].append(b) # Sort each list in dict by score and transform it to numpy array for k in new_boxes: current_boxes = np.array(new_boxes[k]) new_boxes[k] = current_boxes[current_boxes[:, 1].argsort()[::-1]] return new_boxesdef get_weighted_box(boxes, conf_type='avg'): """ Create weighted box for set of boxes :param boxes: set of boxes to fuse :param conf_type: type of confidence one of 'avg' or 'max' :return: weighted box """ box = np.zeros(6, dtype=np.float32) conf = 0 conf_list = [] for b in boxes: box[2:] += (b[1] * b[2:]) conf += b[1] conf_list.append(b[1]) box[0] = boxes[0][0] if conf_type == 'avg': box[1] = conf / len(boxes) elif conf_type == 'max': box[1] = np.array(conf_list).max() box[2:] /= conf return boxdef find_matching_box(boxes_list, new_box, match_iou): best_iou = match_iou best_index = -1 for i in range(len(boxes_list)): box = boxes_list[i] if box[0] != new_box[0]: continue iou = bb_intersection_over_union(box[2:], new_box[2:]) if iou > best_iou: best_index = i best_iou = iou return best_index, best_ioudef weighted_boxes_fusion(boxes_list, scores_list, labels_list, weights=None, iou_thr=0.55, skip_box_thr=0.0, conf_type='avg', allows_overflow=False): ''' :param boxes_list: list of boxes predictions from each model, each box is 4 numbers. It has 3 dimensions (models_number, model_preds, 4) Order of boxes: x1, y1, x2, y2. We expect float normalized coordinates [0; 1] :param scores_list: list of scores for each model :param labels_list: list of labels for each model :param weights: list of weights for each model. Default: None, which means weight == 1 for each model :param iou_thr: IoU value for boxes to be a match :param skip_box_thr: exclude boxes with score lower than this variable :param conf_type: how to calculate confidence in weighted boxes. 'avg': average value, 'max': maximum value :param allows_overflow: false if we want confidence score not exceed 1.0 :return: boxes: boxes coordinates (Order of boxes: x1, y1, x2, y2). :return: scores: confidence scores :return: labels: boxes labels ''' if weights is None: weights = np.ones(len(boxes_list)) if len(weights) != len(boxes_list): print('Warning: incorrect number of weights {}. Must be: {}. Set weights equal to 1.'.format(len(weights), len(boxes_list))) weights = np.ones(len(boxes_list)) weights = np.array(weights) if conf_type not in ['avg', 'max']: print('Unknown conf_type: {}. Must be "avg" or "max"'.format(conf_type)) exit() filtered_boxes = prefilter_boxes(boxes_list, scores_list, labels_list, weights, skip_box_thr) if len(filtered_boxes) == 0: return np.zeros((0, 4)), np.zeros((0,)), np.zeros((0,)) overall_boxes = [] for label in filtered_boxes: boxes = filtered_boxes[label] new_boxes = [] weighted_boxes = [] # Clusterize boxes for j in range(0, len(boxes)): index, best_iou = find_matching_box(weighted_boxes, boxes[j], iou_thr) if index != -1: new_boxes[index].append(boxes[j]) weighted_boxes[index] = get_weighted_box(new_boxes[index], conf_type) else: new_boxes.append([boxes[j].copy()]) weighted_boxes.append(boxes[j].copy()) # Rescale confidence based on number of models and boxes for i in range(len(new_boxes)): if not allows_overflow: weighted_boxes[i][1] = weighted_boxes[i][1] * min(weights.sum(), len(new_boxes[i])) / weights.sum() else: weighted_boxes[i][1] = weighted_boxes[i][1] * len(new_boxes[i]) / weights.sum() overall_boxes.append(np.array(weighted_boxes)) overall_boxes = np.concatenate(overall_boxes, axis=0) overall_boxes = overall_boxes[overall_boxes[:, 1].argsort()[::-1]] boxes = overall_boxes[:, 2:] scores = overall_boxes[:, 1] labels = overall_boxes[:, 0] return boxes, scores, labels
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
发表评论

暂时没有评论,来抢沙发吧~