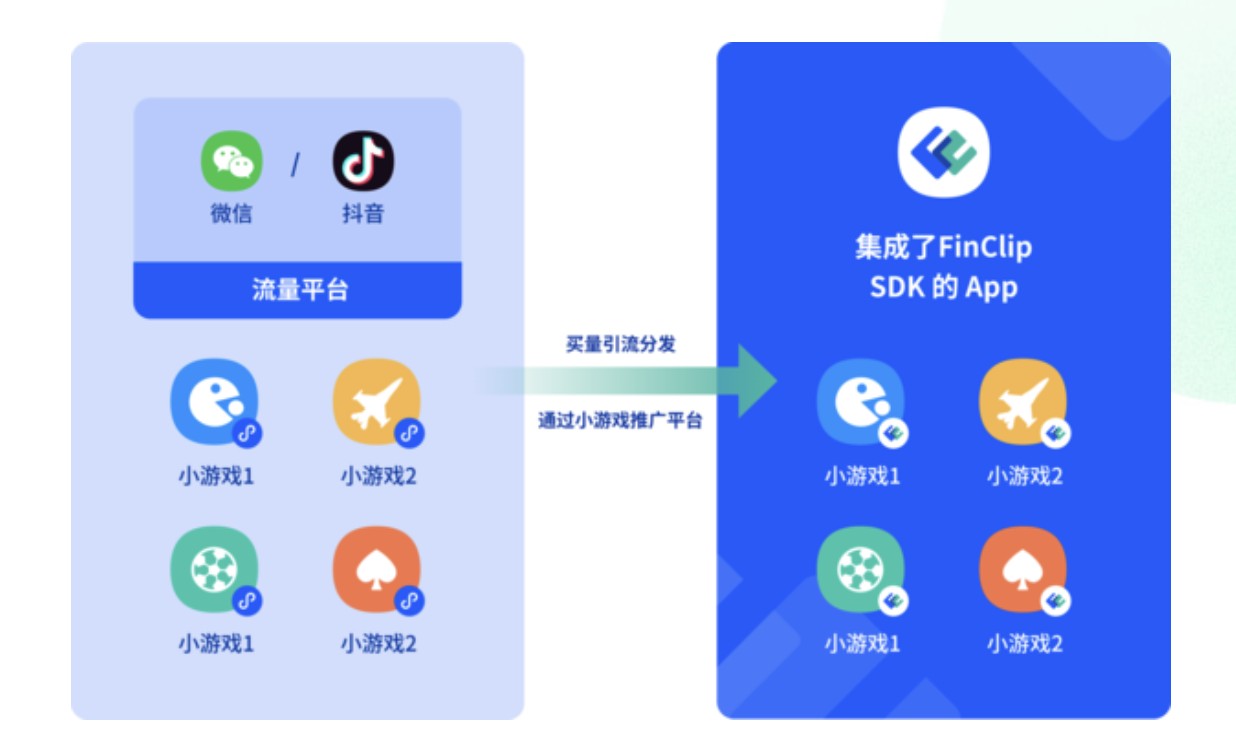
小程序容器助力企业在金融与物联网领域实现高效合规运营,带来的新机遇与挑战如何管理?
894
2022-11-17

初识爬虫之requests库使用篇

之前我们了解过了urllib的库的使用方法,但是我们发现在实际的运用过程中,我们使用requests更加的频繁一些。它可以解决之前的一些繁琐的语法,强大的地方我们就开始看看吧!
import requestsr=requests.get("print(type(r))#类型print(r.status_code)#状态码# print(type(r.text))#响应体类型# print(r.text)#内容print(r.cookies)#cookies
它的方便之处不仅仅在于这里,它还可以用一句话来设置自己请求方法,例如我们用:requests.post(put)(delete)(head)(options)这些是不是比urllib简单的多。
get请求
r=requests.get(" "name":"bob", "age":18}r=requests.get(" "name":"bob", "age":18}r=requests.get("json ()方法,就可以将返回结果是 JSON 格式的字符串转化为字典。比如我们看看这个实例
我们请求普通的网页,来获取信息
抓取二进制数据 平时我们爬虫肯定要-图片,音乐,视频,还有一些东西,这个时候我们就需要用到二进制抓取了。图片、音频、视频这些文件本质上都是由二进制码组成的,由于有特定的保存格式和对应的解析方式, 我们才可以看到这些形形色色的多媒体 。
r=requests.get("print(r.text) #乱码with open("E:\Python实验位置\图片\图片3\pavico.jpg","wb") as f: f.write(r.content) print("保存成功!")
这样你就可以去你的文件目录里面看看这些东西是否已经抓取成功了。
这里简单介绍一下这个东西
python 中os模块os.path.exists()含义,os.path模块主要用于文件的属性获取,exists是“存在”的意思,所以顾名思义,os.path.exists()就是判断括号里的文件是否存在的意思,括号内的可以是文件路径。
import ospath = os.path.exists('user.py')print(path)
True Process finished with exit code 0
不存在false,存在true
POST请求
和get请求差不多一样的,将get换为POST即可,例如我们可以打印一些属性值
其他
这里分别打印输出 status_code 属性得到状态码,输出 headers 属性得到响应头,输出headers属性,得到 Cookies ,输出 url 属性得到 URL ,输出 history 属性得到请求历史。
状态码有Python内置的状态码,我们可以互相比较来获得正常的响应
import requestsr = requests.get("if not r.status_code == requests.codes.ok else print("请求成功")
exit() if not r.status_code == requests.codes.ok else print("请求成功")
这个经常用到的,保障程序正常运行
高级语法
文件上传:
import requestsfiles={"file":open("文件名","rb")}r=requests.post("url",files=files)print(r.text)
里面的东西需要自己去添加,注意这个时候的文件的路径必须和该程序是一样的,在同一目录。
cookies:
首先我们要把自己的网站里面的cookies找到,之后再去复制粘贴在我们程序里面,这个也是我们经常在进行爬虫需要做的一个工作之一。它的功能就是维持我们用户的 登陆状态,通常我们加入headers里面,比如我看看这个实例
爬取一些高级的网站,知乎
也可以自己获取
import requestsr=requests.get("key ,value in r.cookies.items(): print(key+"="+value)
session对象
在 requests 中,如果直接利用 get ()或 post ()等方法的确可以做到模拟网页的请求,但是这实际上是相当于不同的会话,也就是说相当于你用了两个浏览器打开了不同的页面。其实解决这个问题的主要方法就是维持同一个会话 , 也就是相当于打开一个新的浏览器选项卡而不是新开一个浏览器 。
import requestss = requests.Session()s.get('= s.get('还提供了证书验证的功能 。当发送 HTTP 请求的时候,它会检查 SSL 证书,我们可以使用 verify 参数控制是否检查此证书 。 其实如果不加 verify 参数的话,默认是 True ,会自动验证。
通常变为false之后,他还是会弹出警告
这里我们屏蔽警告
前方高能
代理设置
对于某些网站,在测试的时候请求几次 , 能正常获取内容。 但是一旦开始大规模爬取,对于大规模且频繁的请求,网站可能会弹出验证码,或者跳转到登录认证页面 , 更甚者可能会直接封禁客户端的 IP ,导致一定时间段内无法访问 。在爬取一些淘宝,京东这些反爬技术较强的网站,代理的技术不可或缺。
import requestsproxies={ " "200 状态码 ;如果认证失败, 则返回 401 状态码。
优化:
数据结构
之前在urllib里面有request.Request这个用法,在这里我们也可以这样用
requests.Request()
from requests import Request,Sessionurl = ""data={}headers={}s=Session()req=Request("POST",url=url,data=data,headers=headers)pre=s.prepare_request(req)r=s.send(pre)print(r.text)
爬虫正则表达式也是基础,虽然Xpath比较强,但是我们还是要了解这个东西
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

发表评论

暂时没有评论,来抢沙发吧~