

提升BERT fine-tune正确率0.2%-0.3%的一个细节
提升BERT fine-tune正确率0.2%-0.3%的一个细节

字级别分词,不要用官方的tokenizer (tokenize_to_str_list(textString): split_tokens = [] for i in range(len(textString)): split_tokens.append(textString[i]) return split_tokensdef convert_to_int_list(split_tokens): output = [] for token in split_tokens: if token in char2id: output.append(char2id[item]) return
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。
相关文章
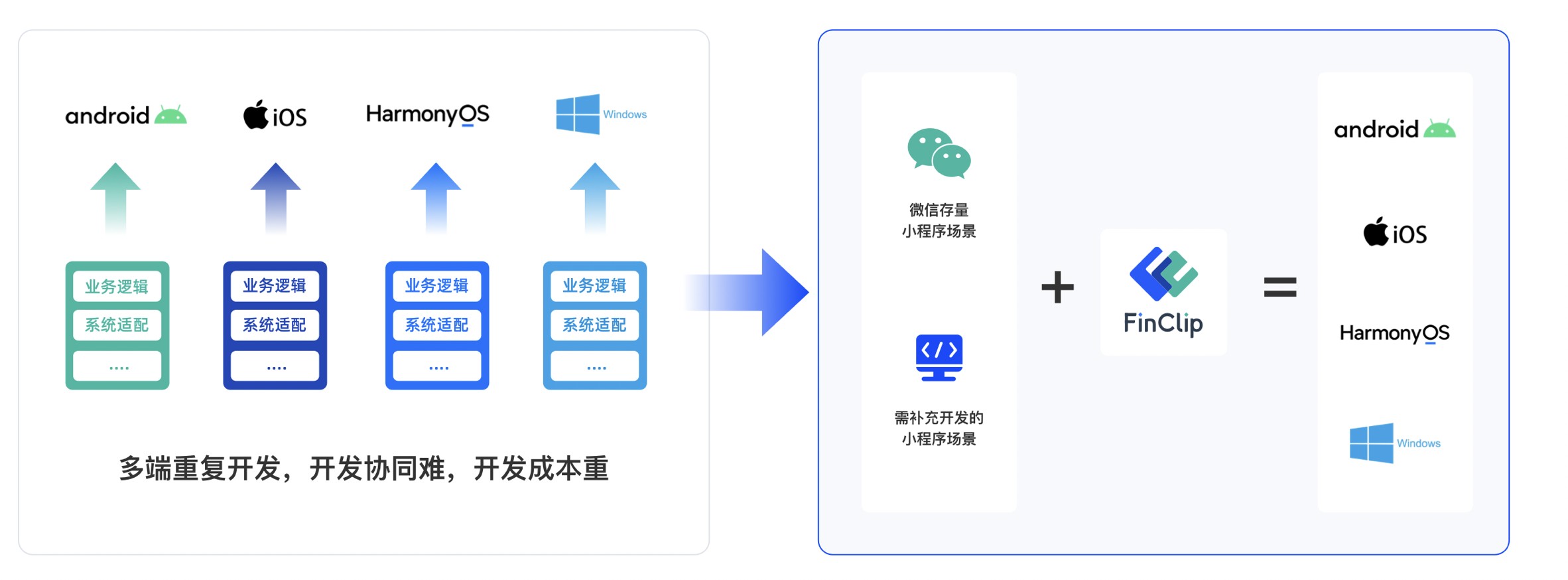

发表评论
最近发表
- 智慧屏安装APP的最佳实践与跨平台小程序开发的结合
- 洞察探索小米电视app开发如何利用FinClip的小程序容器技术,实现跨平台便捷开发,并助力企业快速数字化转型。
- 洞察掌握android电视app开发中的安全与合规策略,提升企业运营效率
- 如何通过低成本的代驾app系统开发实现高效运营和企业数字化转型?
- 洞察如何通过FinClip提升国产操作系统App开发效能与安全性
- 洞察如何通过低成本家政服务app实现高效管理与数字化转型
- 洞察如何利用小程序容器技术助力工程供应商的数字化转型
- 洞察探索如何通过创新技术提升直播软件应用的开发效率,助力企业成功实现数字化转型
- 洞察热更新技术在跨平台小程序开发中的重要性,助力企业快速响应市场需求。
- 在金融与物联网领域,如何利用前端跨端方案优化小程序开发与安全管理?
推荐文章
热评文章

暂时没有评论,来抢沙发吧~