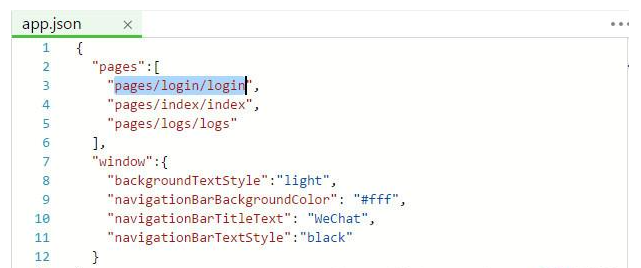
微信小程序本地存储与登录页面处理实例详细讲解
2511
2022-11-06

协程入门,这可能是全网最简单易懂的扫盲贴了

文章目录
引言
协程是什么哪里提升了效率?适用的场景协程的实现原理总结
引言
还记得大概是去年十一月份的时候,心中萌发了用协程去优化下写的race,也就是我们通常所说的条件竞争,仔细一想也很好理解,两个线程分别运行在两个CPU上,并在同一个时间点执行同一条指令,这就会产生数据竞争,解决的方法就是加锁,这伴随着加锁解锁两个用户态转向内核态的过程,但是确实解决了我们的问题。这个时候非抢占式的好处就体现出来了,因为协程A很清楚我什么时候可以把数据用完,当协程A用完的时候把CPU交给协程B,协程B再去执行,这实际是一个串行的过程,当然就省去了线程上我们做的那些努力。
再来说说协程,协程听名字就知道它是一个协作式多任务的模型。其实协程本质上就是一个用户态的线程,实现一个协程库也实际就是去实现一个用户态的调度器,也就是说对于内核来说,如果我们在一个线程内申请了10个协程,它眼里的始终只是一个线程不停的在跑,而在我们用户眼中,十个不同的“程序”在不停的切换执行,确实十分神奇,也看似十分高效,我们不妨来思考一下它到底在哪些地方提升了效率。
哪里提升了效率?
以上面的一个线程十个协程举例,内核看来只有一个线程在跑,极其显然,这些协程是在串行,而不是并行,尽管你有十个协程,但你也只能使用一个CPU。所以想要高效的利用CPU我们还是需要使用线程。那么协程究竟快在哪里?我想最大的优势就是协程的切换相比于线程的切换更快,我们知道在线程执行一些阻塞的系统调用的时候线程会从执行态转化为阻塞态,伴随着内核态到用户态的转化,这一过程有以下几个消耗资源的地方:
上下文切换(本质就是寄存器切换)。特权模式切换。(调度算法中的动态特权级)而且内核代码对用户不信任,需要进行额外的检查。
而协程的切换就只需要执行一个上下文的切换,且全部的操作都在用户空间完成,当然这里效率的提升有提升,但肯定不是量级的。第二个效率提升的地方在于使得两个互相依赖的代码不需要再去考虑data race,省去了维护同步所带来的开销,这个开销不得不说是非常可观的,光是加锁解锁就要进行两次内核态到用户态的转换。
适用的场景
协程只是一种解决问题的方式,且不是一种通用方式,它只是为我们提供了有一种新的运行时抽象,而这种抽象可以在某些场景被完美的契合。那么协程的适用场景是什么呢?答案就是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远低于CPU,缓存,内存的速度)。在学习多线程编程的时候我们知道,当任务为IO密集型任务时,我们需要把线程数设置为大于CPU物理核数的一个值,因为在IO密集型任务执行期间,99%的时间都花在IO上,花在CPU上的时间很少。为了充分的利用CPU,我们需要大量的线程,而这意味着大量的线程切换,这一点我们上面已经讨论过了,这种情况下显然协程可以提升我们程序的效率。
当然我们在编写协程代码的时候时刻脑子里要清楚一件事情,在一个线程上,无论你开了多少协程,始终只是一个CPU在跑罢了。所以一般情况下我们的模型是多线程搭配多协程或者多进程搭配多协程,做到充分的利用CPU。
协程的实现原理
说了那么多,你一定对这个东西充满了疑惑,到底怎么才能做到在一个线程上还能执行十个协程,且这些协程的还有各自的不同的代码段呢?我上面提到了一点,实现一个协程库实际上就是实现一个用户态的“线程”调度器,因为我们知道程序的执行依赖的是寄存器上的值,包括我们熟知的PC,ESP,EBP,CS,DS,FLAGS等等,所以上下文的切换实际上就是把寄存器的值进行切换,但是什么时候切换呢?我们知道一般来说协程库为我们的会提供以下两个函数,一个是resume,功能为执行一个指定协程,一个是yield,功能为切换CPU执行权到另一个协程,有了这两个函数,我们可以随心所欲的去切换协程了。那么什么时候切换呢?答案就是在进行阻塞式系统调用进行切换,当然你可能会问如何做到在执行系统提供给我们的函数时执行我们自己的逻辑呢?这里有两个方法,一个是协程库替换系统调用,这当然比较直接了。还有一种巧妙的方法,腾讯的libco就使用了这种方法,即库打桩机制,原理为通过动态链接时先加载自己定义的函数已做到把系统提供的函数“hook”掉,使用dlsym系列函数得到原函数地址,执行相关逻辑。
当然以上只是简单的陈述了一些原理性的东西,实际实现的话还有很多的细枝末节,比如对于协程栈的实现,到底值一个协程一个栈还是共享栈呢?所说的无栈协程到底是怎么一回事呢?在协程切换出去以后何时切换回来呢?剩下的问题还需要有兴趣的同学继续深入理解。
总结
协程也可以并发的执行多线逻辑,但完全不会给CPU带来额外负担,因为是串行执行,所以不存在任何资源竞争。但是其使用场景是有限制的,比如计算密集型的引用完全没有必要使用协程,因为相比于单线程协程的切换也需要不少操作和上下文的切换,让一个线程不管不顾的计算显然是一个更优的选择。至于单机千万连接,我到现在也认为连接数是与fd相关的,而fd的改变是靠改内核参数的。一个博主的一句话我觉得很有意思,也送给大家:一个协程就想以一敌百吗,纵使你有百般能耐,也不可能以一敌百…
参考:
博文《Linux | 为什么用户态和内核态的切换耗费时间?》博文《为什么协程切换的代价比线程切换低?》博文《编程珠玑番外篇-Q 协程的历史,现在和未来》知乎《https://zhihu.com/question/32218874》博文《也来谈谈协程》
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

发表评论

暂时没有评论,来抢沙发吧~