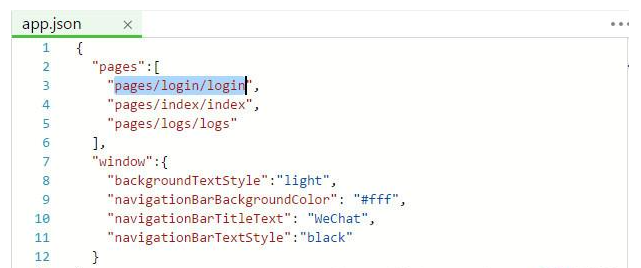
微信小程序本地存储与登录页面处理实例详细讲解
936
2022-11-05

Python爬虫框架,内置微博、自如、豆瓣图书、拉勾网、拼多多等爬虫

PyLoom,爬龙!
PyLoom想为有价值的网站编写爬虫,让开发者便捷地获取结构化的数据。
PyLoom由三个部分组成,
框架,减少编写、运行、维护爬虫的工作量。 爬虫,寻找有价值的目标为其开发爬虫,并维护既有爬虫的可用性。 预期19年底,PyLoom将拥有围绕电子商务、房屋租售、社交网络、新闻媒体的数十个爬虫。 升级爬虫,对于频繁使用的爬虫,增强其能力增强定制能力,例如支持限定地区、类别、关键字抓取;增强抓取策略,减少对代理、打码接口的使用;增强更新策略,更细粒度地计算重复抓取的时间。
目前进度,
①部分完成,开发常见爬虫够用了,随爬虫的开发迭代出更多功能;
②已有几款爬虫,放置于spiders目录。
安装
环境要求python 3.6.0+redis 2.6+类unix系统 安装PyLoomgit clone https://github.com/spencer404/PyLoom.gitpython3.6 -m pip install -e ./PyLoom添加 -i https://pypi.douban.com/simple 参数,利用豆瓣镜像提速。出现错误fatal error: Python.h: No such file or directory时,需安装对应平台的python3.x-devel包
运行
以运行spiders/WeiBo为例,
最简参数启动爬虫pyloom run -s PyLoom/spiders/WeiBo在爬虫目录中执行run时,可省略-s参数。 启动代理池pyloom proxy run 添加代理 根据命令提示,添加名为"xxx"的代理pyloom proxy add 使用代理启动爬虫pyloom run --proxy xxx 命令run的部分常用参数:-l, --level 日志级别-s, --spider 指定爬虫目录-r, --redis 指定redis地址(URL形式)-C, --clear 清空队列、代理数据后运行--proxy 使用指定代理运行,逗号分隔多个代理--damon 作为守护进程运行-p 子进程数量-t 每个子进程的线程数量 在多台服务器上运行时,若参数-s、-r所指向的目标相同,即可横向扩容性能。 默认地,PyLoom将抓到数据打印在日志中,你可以修改on_save函数自定义如何保存。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。

发表评论

暂时没有评论,来抢沙发吧~