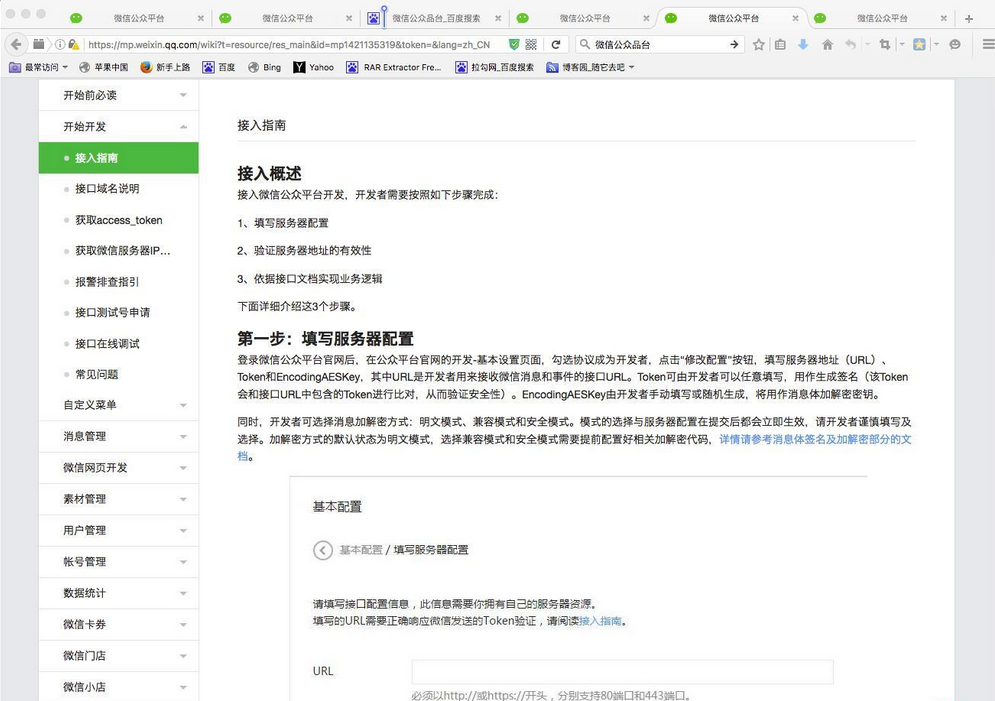
开发微信公众平台配置接口程序详细步骤
556
2022-10-28

基于Scikit-Learn和Pandas的机器学习测试框架

ML Testing
The goal of this module is to create a flexible and easy to use module for testing machine learning models, specifically those in scikit-learn.
The tests will be readable enough that anyone can extend them to other frameworks and APIs with the major notions kept the same, but more or less the ideas will be extended, no work will be taken in this library to extend passed the scikit-learn API.
You can read the docs for a more detailed explaination.
Tests Covered
Testing Against Metrics Classification Tests Rule Based Testing: precision lower boundaryrecall lower boundaryf1 score lower boundaryAUC lower boundaryprecision lower boundary per classrecall lower boundary per classf1 score lower boundary per classAUC lower boundary per class Decision Based Testing: precision fold below averagerecall fold below averagef1 fold below averageAUC fold below averageprecision fold below average per classrecall fold below average per classf1 fold below average per classAUC fold below average per class Against New Predictions proportion of predictions per classclass imbalance testsprobability distribution similarity testscalibration tests environmental impact tests energyusage upper bound test Regression Tests Rule Based Testing: Mean Squared Error upper boundaryMedian Absolute Error upper boundary Decision Based Testing: Mean Squared Error fold above averageMedian Absolute Error fold above average Testing Against Run Time Performance prediction run time for simulated samples of size X Testing Against Input Data percentage of correct imputes for any columns requiring imputationdataset testing - http://vldb.org/pvldb/vol11/p1781-schelter.pdf Memoryful Tests cluster testing - this is about the overall structure of the data If the number of clusters increases or decreases substantially that should be an indicator that the data has changed enough that things should possibly be reruncorrelation testing - this is about ensuring that the correlation for a given column with previous data collected in the past does not change very much. If the data does change then the model should possibly be rerun.shape testing - this is about ensuring the general shape of for the given column does not change much over time. The idea here is the same as the correlation tests.
Possible Issues
Some known issues with this, any machine learning tests are going to require human interaction because of type 1 and type 2 error for statistical tests. Additionally, one simply needs to interrogate models from a lot of angles. It can't be from just one angle. So please use with care!
Future Features
cross validation score testingadd custom loss functionadd custom accuracy functionadd these tests: https://datasciencecentral.com/profiles/blogs/a-plethora-of-original-underused-statistical-testsclustering for classificationUnsupervised and semi supervised tests verify similarity in clusters to similarity in labelsgenerate a small representative set of labels and then propagate other labels
References
https://dzone.com/articles/quality-assurancetesting-the-machine-learning-modehttps://medium.com/datadriveninvestor/how-to-perform-quality-assurance-for-ml-models-cef77bbbcfbExplaination of UAT: https://techopedia.com/definition/3887/user-acceptance-testing-uathttps://mice.cs.columbia.edu/getTechreport.php?techreportID=419&format=pdfhttps://xenonstack.com/blog/unit-testing-tdd-bdd-deep-machine-learning/
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。


发表评论

暂时没有评论,来抢沙发吧~