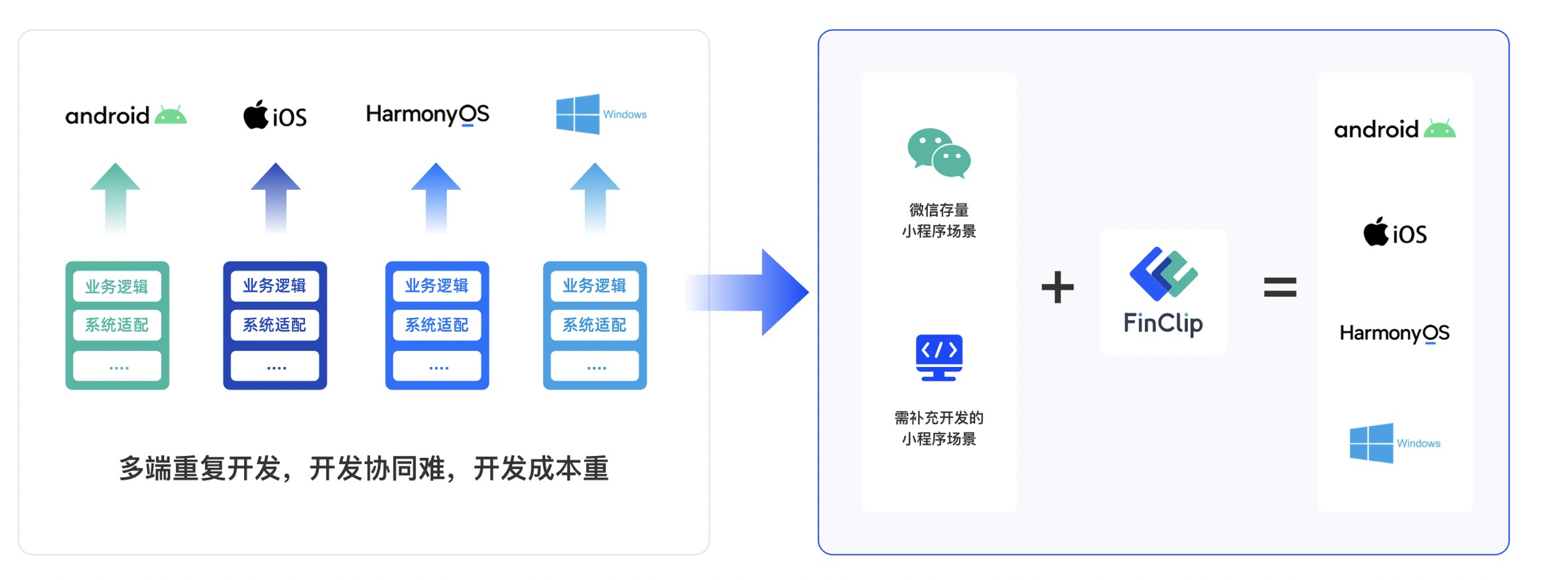
uniapp开发app框架在提升开发效率中的独特优势与应用探索
963
2022-10-24

Ganzo:基于PyTorch的GAN开发研究框架

Ganzo
Ganzo is a framework to implement, train and run different types of GANs, based on PyTorch.
It aims to unify different types of GAN architectures, loss functions and generator/discriminator game strategies, as well as offer a collection of building blocks to reproduce popular GAN papers.
The guiding principles are:
be fully runnable and configurable from the command line or from a jsON filebe usable as a libraryallow for reproducible experiments
Experiments
Some examples of configuration are available in the experiments folder, together with their output. For instance, a WGAN with gradient penalty running on the bedrooms dataset produces
Installing
The only hard dependencies for Ganzo are PyTorch and TorchVision. For instance, in Conda you can create a dedicated environment with:
conda create -n ganzo python=3.7 pytorch torchvision -c pytorch
If available, Ganzo supports TensorBoardX. This is detected at runtime, so Ganzo can run with or without it. TensorBoardX can be installed with Pip:
pip install tensorboardX
If you want to use LMDB datasets such as LSUN, you will also need that dependency:
conda install python-lmdb
To download the LSUN image dataset, use the instructions in the linked repository.
Running
Ganzo can be used either from the command line or as a library. Each component in Ganzo can be imported and used separately, but everything is written in a way that allows for full customization on the command line or through a JSON file.
To see all available options, run python src/ganzo.py --help. Most options are relative to a component of Ganzo (data loading, generator models, discriminator models, loss functions, logging and so on) and are explained in detail together with the relative component.
Some options are global in nature:
experiment this is the name of the experiment. Models, outputs and so on are saved using this name. You can choose a custom experiment name, or let Ganzo use a hash generated based on the options passed.device this is the device name (for instance cpu or cuda). If left unspecified, Ganzo will autodetect the presence of a GPU and use it if available.epochs number of epochs for training.model-dir path to the directory where models are saved. Models are further namespaced according to the experiment name.restore if this flag is set, and an experiment with this name has already been run, Ganzo will reload existing models and keep running from there.delete if this flag is set, and an experiment with this name has already been run, Ganzo will delete everything there and start from scratch. Note that by default Ganzo will ask on the command line what to do, unless at least one flag among delete and restore is active (delete takes precedence over restore).seed this is the seed for PyTorch random number generator. This is used in order to reproduce results.from-json: load configuration from this JSON file (see below)start-epoch: the epoch to start with. By default it is 1, but it can make sense to override this if you are restoring from a previous session of training, so that statistics and snapshots will be assigned the correct epoch.parallel: if this flag is active, the computation will be distributed across all available GPUs. You can limit the visible GPUs by the environment variable CUDA_VISIBLE_DEVICES
Running from a JSON configuration file
If options become too many to handle comfortably, you can run Ganzo with a JSON configuration file. There are two way to do this.
If you have already run an experiment, and you try to run it again, Ganzo suggests you to keep going from where it was left (this can even be forced by using the --restore flag).
Otherwise, if it is the first time that you run an experiment, you can create a JSON file containing some of the command line options, and ask Ganzo to load the configuration from this file using the --from-json flag. Command line and JSON options can also be mixed freely, with JSON options taking precedence.
Assuming you have an option file called options.json, you can load it with
python src/ganzo.py --from-json options.json
If you need a reference file, you can run any experiment, look at the generated options file, and tweak that.
Inference
If you already have a trained model, you can use Ganzo to perform inference. For this, you just need to pass a minimal set of arguments to Ganzo, namely --model-dir and --experiment. You can optionally specify the number of samples to generate with the option --num-samples. The script to perform inference is called deh.py, so you can invoke it like this:
python src/deh.py --model-dir $MODELS --experiment $EXPERIMENT --num-samples 10
The other options will be read from the file options.json that is saved next to the models, although you can override specific options on the command line. Not all training options make sense at inference time, those that are not relevant are just ignored.
Some options are just flags that may have been set a training time, for instance --sample-from-fixed-noise. If you need to override it, just prepend a no to the flag name, for instance
python src/deh.py --model-dir $MODELS --experiment $EXPERIMENT --num-samples 10 --no-sample-from-fixed-noise
Architecture
Ganzo is structured into modules that handles different concerns: data loading, generators, discriminators, loss functions and so on. Each of these modules defines some classes that can be exported and used on their own, or can be used fully through configuration, for instance from a JSON file.
To do so, each module defines a main class (for instance, loss.Loss, or data.Data), that has two static methods:
from_options(options, *args) initializes a class from an object representing the options. This object is a argparse.Namespace object that is obtained by parsing command line options or JSON configuration files. Most classes only require the options object in order to be instantiated, but in some cases, other arguments are passed in as well -- for instance the loss function requires the discriminator in order to compute generator loss.add_options(parser) takes as input an argparse.ArgumentParser object, and adds a set of arguments that are relevant to the specific module. This is typically done by adding an argument group. Of course, options are not constrained to be used by the module that introduces them: for instance, data.Data adds the argument batch-size, that is used by many other modules.
Having each module defined by configuration allows Ganzo to wire them without knowing much of the specifics. The main loop run at training time looks like this:
data = Data.from_options(options)generator = Generator.from_options(options)discriminator = Discriminator.from_options(options)loss = Loss.from_options(options, discriminator)noise = Noise.from_options(options)statistics = Statistics.from_options(options)snapshot = Snapshot.from_options(options)evaluation = Evaluation.from_options(options)game = Game.from_options(options, generator, discriminator, loss)for _ in range(options.epochs): losses = game.run_epoch(data, noise) statistics.log(losses) snapshot.save(data, noise, generator) if evaluation.has_improved(losses): # save models
You can write your own training script by adapting this basic structure. It should be easy: the source of ganzo.py is less than 100 lines, most of which deal with handling the case of restoring a training session.
Components
The following goes in detail about the various components defined by Ganzo: their role, the classes that they export, and the options that they provide for configuration.
Data
This module handles the loading of the image datasets.
Datasets can come in various formats: single image datasets (with or without a labeling) and datasets of input/output pairs. A single image dataset can be used to train a standard GAN, while having the labels can be used for conditioned GANs. Datasets of pairs can be used for tasks of image to image translation, such as super resolution or colorization.
Also, datasets can be stored in different ways. The simplest one is a folder containing images, possibly split into subfolders representing categories. But some datasets are stored in a custom way - for instance MNIST or LSUN.
The module data defines the following classes:
SingleImageData: Loads datasets of single images, possibly matched with a corresponding label. Takes care of resizing/cropping images, batching, shuffling and distributing the work of data loading across a number of workers. Each batch has shape B x C x W x H whereB is the batch sizeC is the number of channels (1 for B/W images, 3 for colors)W is the image widthH is the image height
The module data exports the following options:
data-format: the format of the dataset, such as single-imagedata-dir: the (input) directory where the images are storeddataset: the type of dataset, such as folder, mnist or lsunimage-class: this can be used to filter the dataset, by restricting it to the images having this labelimage-size: if present, images are resized to this sizeimage-colors: can be 1 or 3 for B/W or color imagesbatch-size: how many images to consider in each minibatchloader-workers: how many workers to use to load data in background
Generator
This module defines the various generator architectures.
The module generator defines the following classes:
FCGenerator TODO describe itConvGenerator TODO describe itGoodGenerator TODO describe it
The module generator exports the following options:
generator: the type of generator (fc or conv)generator-dropout: the amount of dropout to use between generator layers - leave unspecified to avoid using dropoutgenerator-layers: how many layers to use in the generator
Discriminator
This module defines the various generator architectures.
The module discriminator defines the following classes:
FCDiscriminator TODO describe itConvDiscriminator TODO describe itGoodDiscriminator TODO describe it
The module discriminator exports the following options:
discriminator: the type of discriminator (fc or conv)discriminator-dropout: the amount of dropout to use between discriminator layers - leave unspecified to avoid using dropoutdiscriminator-layers: how many layers to use in the discriminator
Loss
This module defines classes that compute the loss functions both for the generator and the discriminator. The reason why they are coupled is that the loss function for the generator needs access to the discriminator anyway.
The module loss defines the following classes:
GANLoss: the standard GAN loss from [1]WGANLoss: the Wasserstein GAN loss from [2]WGANGPLoss like WGAN, but uses gradient penalty instead of weight clipping [3]Pix2PixLoss: the loss for Pix2Pix from [4]
[1] https://arxiv.org/abs/1406.2661 [2] https://arxiv.org/abs/1701.07875 [3] https://arxiv.org/abs/1704.00028 [4] https://arxiv.org/abs/1611.07004
The module loss exports the following options:
--loss: the type of loss (gan, wgan, wgan-gp or pix2pix)--gradient-penalty-factor: the gradient penalty factor (λ) in WGAN-GP--soft-labels: if true, use soft labels in the GAN loss (randomly fudge the labels by at most 0.1)--noisy-labels': if true, use noisy labels in the GAN loss (sometimes invert labels for the discriminator)--noisy-labels-frequency: how often to invert labels for the discriminator--l1-weight: weight of the L¹ distance contribution to the GAN loss
Noise
This modules defines classese that generate random noise. Most GAN generators can be seen as implementing a map {latent space} -> {images}, where the latent space is some fixed Euclidean space. The noise generators implement sampling in latent space, so generating an image consists of sampling a random noise and applying the generator.
The module noise defines the following classes:
GaussianNoise: A generator of Gaussian noise
The module noise exports the following options:
state-size: the dimension of the latent space
Statistics
This module defines classes that handle logging stastistics such as time spent during training and the various losses. At this moment, logging can happen either on the console or via TensorBoard.
The module statistics defines the following classes:
NoStatistics: a class that just drops the logging informationConsoleStatistics: a class that displays logging information on the consoleFileStatistics: a class that writes logging information into a fileTensorBoardStatistics: a class that logs information via TensorBoard (requires TensorBoardX)
The module statistics defines the following options:
log: either none, console, file or tensorboardlog-file: when using --log file this determines the file where logs are written. If missing, it defaults to $OUTPUT_DIR/$EXPERIMENT/statistics.log.
Snapshot
This module define classes that periodically take example snapshot images and save them.
The module snapshot defines the following classes:
FolderSnaphot: a class that saves images on disk in a predefined folderTensorBoardSnaphot: a class that saves images via TensorBoard (requires TensorBoardX)
The module snapshot defines the following options:
save-images-as: either folder or tensorboardoutput-dir: directory where to store the generated imagessnapshot-size: how many images to generate for each sample (must be <= batch-size)sample-every: how often to sample images (in epochs)sample-from-fixed-noise: if this flag is on, always use the same input noise when sampling, otherwise generate new random images each time
Evaluation
This module defines criteria that can be used to evaluate the quality of the produced images. Ganzo will save the model whenever these have improved.
The module evaluation defines the following classes:
Latest: always returns true, thus letting Ganzo always save the latest modelsGeneratorLoss: defines that evaluation has improved when the loss for the generator decreases
The module evaluation defines the following options:
evaluation-criterion: either latest or generator-loss
Game
This module defines classes that implement the actual GAN logic, which has a few variants.
The module game defines the following classes:
StandardGame: the usual GAN game that opposes a generator, taking random noise as input, and a discriminator to learn classify real and fake samplesTranslateGame: a game that uses the generator to perform an image translation task. This is different from StandardGame, since the generator receives as input real images from a given domain, and needs to produce as output images in a different domain. The discriminator learns to classify real and fake samples, but both are overlaid to the original input, in order to evaluate the quality of the translation.
The module game defines the following options:
evaluation-criterion: either standard or translategenerator-iterations: number of iterations on each turn for the generatordiscriminator-iterations: number of iterations on each turn for the discriminatorgenerator-lr: learning rate for the generatordiscriminator-lr: learning rate for the discriminatorbeta1: first betabeta2: second betamax-batches-per-epoch: maximum number of minibatches per epoch
Extending Ganzo
Ganzo can be extended by defining your custom modules. To do this, you do not need to write your training script (although this is certainly doable). If you want to define custom components and let Ganzo take advantage of them, you need to follow four steps:
write your custom component (this can a be a data loader, a generator, a loss function...). You will need to make sure that it can be initialized via an option object and that it exposes the same public methods as the other classes (for instance, a loss function exposes two public methods def for_generator(self, fake_data, labels=None) and def for_discriminator(self, real_data, fake_data, labels=None))let Ganzo be aware of your component by registering itadd an enviroment variable to make Ganzo find your moduleoptionally, add your custom options to the argument parser.
To make this possible, Ganzo uses a registry, that can be found under registry.py. This exports the Registry singleton and the register decorator function (also, the RegistryException class, which you should not need).
Custom components and the registry
When you write your custom component, you need to register it in the correct namespace. This can be done with the Registry.add function, or more simply with the register decorator. In both cases you will need to provide the namespace (e.g. loss for a loss function) and the name of your component (this is your choice, just make sure not to collide with existing names). For instance, registering a CustomLoss class can be done like this:
from registry import register@register('loss', 'custom-loss')class CustomLoss: # make sure that your __init__ method has the same signature # as the existing components def __init__(self, options, discriminator): # initialization logic here # more class logic here, for instance the public API def for_generator(self, fake_data, labels=None): pass def for_discriminator(self, real_data, fake_data, labels=None): pass
This can also be done more explicitly by adding your class to the registry:
from registry import Registryclass CustomLoss: # make sure that your __init__ method has the same signature # as the existing components def __init__(self, options, discriminator): # initialization logic here # more class logic here, for instance the public API def for_generator(self, fake_data, labels=None): pass def for_discriminator(self, real_data, fake_data, labels=None): passRegistry.add('loss', 'custom-loss', CustomLoss)
You will then be able to select your custom loss function by passing the command line argument --loss custom-loss. Both register and Registry.add take a flag default which means that the registered component will be selected as default when the corresponding command line option is missing. This can be used only once, though, and it is already taken by the default components of Ganzo, so you should not pass default=True while registering your component.
Finding your module
Of course, at this point Ganzo is not aware that your module exists, or that it defines and register new components. You need to make sure that Ganzo actually imports your module, so that your custom logic is run. This cannot be done with a flag on the command line: the reason is that you are able to add custom options to the argument parser, so your modules must be found before reading the command line options.
To do this, we use an environment variable GANZO_LOAD_MODULES, which should contain a comma-separated list of python modules that you want to import before Ganzo starts. These modules should be on the Python path, so that they can be imported by name. For instance, if you have defined your loss inside custom.py, you can call Ganzo like this:
GANZO_LOAD_MODULES=custom python src/ganzo.py # more options here
Customizing options
Probably, your custom component will need some degrees of freedom that are not applicable in general, and this means that you need to be able to extend the command line parser. To do this, import the decorator with_option_parser from the registry module and define a function that takes a parser argument and extends it. This function is also passed the train argument, which you can use to only activate certain options during training (or only during inference).
It is advised to namespace your options into their own argument group, in order to make the help message more understandable. An example would be
from registry import with_option_parser@with_option_parserdef add_my_custom_options(parser, train): group = parser.add_argument_group('custom') group.add_argument('foos', type=int, default=3, help='the number of foos') if train: group.add_argument('bars', type=int, default=5, help='the number of bars')
Using Ganzo as a library
All components in Ganzo are designed to be used together by configuration, but this is not a requirement by any means. If you want to write your custom training and inference scripts, and only need access to some of Ganzo's generators, discriminators, loss function and so on, this is easily doable.
All classes need in the constructor an options parameter , which is an instance of argparse.Namespace. Other than that, you can just import and use the classes as needed. For example
from argparse import Namespacefrom ganzo.generator import UGeneratoroptions = Namespace()options.generator_layers = 5options.generator_channels = 3generator = UGenerator(options)
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。


发表评论

暂时没有评论,来抢沙发吧~