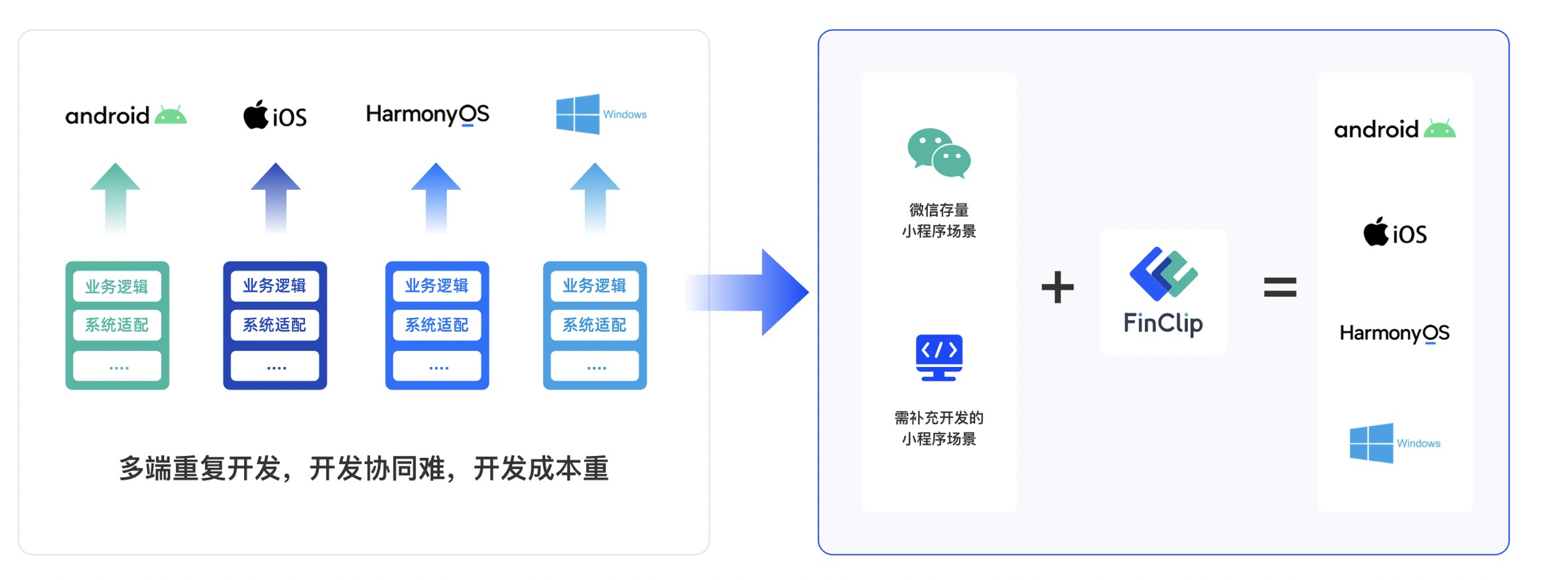
uniapp开发app框架在提升开发效率中的独特优势与应用探索
656
2022-10-19

CHeSF是Chrome Headless爬取框架

Introduction
In the era of Big Data, the web is an endless source of information. For this reason, there are plenty of good tools/frameworks to perform scraping of web pages.
So, I guess, in an ideal world there should be no need of a new web scraping framework. Nevertheless, there are always subtle differences between theory and practice. The case of web scraping made no exceptions.
Real world web pages are often full of javascript codes that alter the DOM as the user requests/navigates pages. Consequently, scraping javascript intensive web pages could be impossible.
Such considerations were the sparks that gave birth to CHeSF, the Chrome Headless Scraping Framework. To make a long story short, CHeSF relies on both selenium-python and ChromeDriver to perform scraping of webpages also when javascript makes it impossible.
I know that already exists some nice solutions to this problems, but in my point of view CHeSF is simpler: you just create a class that inherits from it, define the parse method and launch it with a start url.
The framework is still very alpha. You should expect that things could change rapidly. Currently, there is no documentation, nor packaging. There is just an example showing how you could use the framework to easily scrape TripAdvisor reviews. Personally, I used it to collect this dataset, i.e. a collection of more than 220k TripAdvisor reviews.
Basic usage
CHeSF borrows its working philosophy (in part) from Scrapy, i.e. making a scraping tool means creating (at least) a python class.
import sysimport os# the path to the crhome driver executablepath_to_chrome_driver_exe = 'path_to_chromedriver.exe'# currently, no packages exists for CHeSF, so use this hack until # I'll have some free time to implement packagingpath_to_chesf = 'path_to_chesf_in_your_system'sys.path.insert(0, os.path.abspath(path_to_chesf))from chesf import CHeSF, MAX_ATTEMPTSclass TripAdvisorScraper(CHeSF): def __init__(self): super().__init__(path_to_chrome_driver_exe, debug=False) # this is the core of the Scraper, you must define it since by # convention is the callback called with the first url passed, # after, you can define other callbacks def parse(self): # the main pro of CHeSF is that you could use directly # javascript to parse the page script = """ let urls = []; let anchors = document.querySelectorAll("a.property_title.prominent"); for (let a of anchors) urls.push(a.href); return urls; """ # the array returned from the javascript is automagically # transformed to a python list (this is selenium magic) links = self.call_js(script) for link in links: print(link) # you could use both xpath and css selectors (just change the # method you use) next_page = self.css('a.nav.next.taLnk.ui_button.primary', timeout=1) if len(next_page) > 0: # clicks are immediately executed self.enqueue_click(next_page[0], self.parse) start_url = 'https://tripadvisor.com/Hotels-g187791-c2-Rome_Lazio-Hotels.html'scraper = TripAdvisorScraper()try: scraper.start(start_url)except: scraper.quit() raise
Contacts
In case of questions and/or suggestions, write me a note using my GitHub contact email.
Mini FAQ
Q. Hey man, it absolutely doesn't work! What's wrong? A. Please, check that your ChromeDriver is suitable for the Chrome version you are using.
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。


发表评论

暂时没有评论,来抢沙发吧~