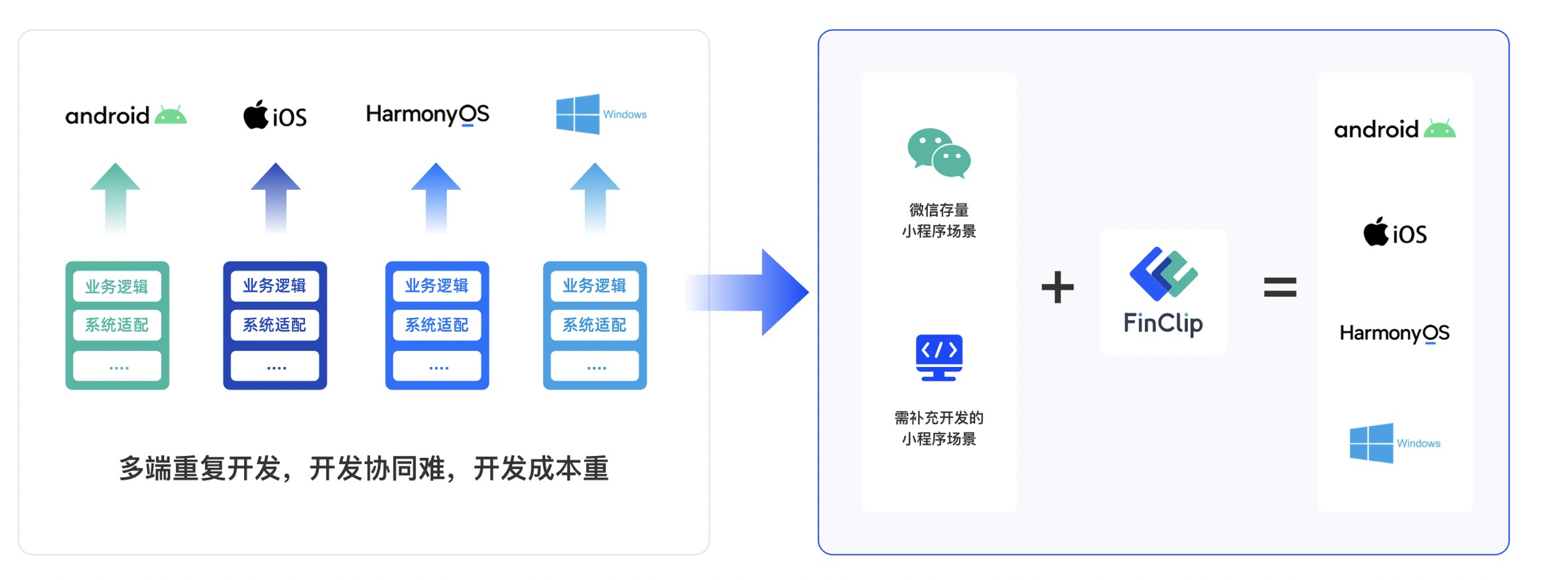
uniapp开发app框架在提升开发效率中的独特优势与应用探索
1068
2022-10-17

chewy - 高级Elasticsearch Ruby框架

Sponsored by
Chewy
Chewy is an ODM and wrapper for the official Elasticsearch client.
Table of Contents
Why Chewy?InstallationUsageClient settingsAWS ElasticSearch configuration Index definitionType default import optionsMulti (nested) and object field typesParent and children typesGeo Point fieldsCrutches™ technologyWitchcraft™ technologyRaw ImportIndex creation during importJournalingTypes accessIndex manipulationIndex update strategiesNestingNon-block notationDesigning your own strategies Rails application strategies integrationActiveSupport::Notifications supportNewRelic integrationSearch requestsComposing requestsPaginationNamed scopesScroll APILoading objectsLegacy DSL incompatibilities Rake taskschewy:resetchewy:upgradechewy:updatechewy:syncchewy:deployParallelizing rake taskschewy:journal Rspec integrationMinitest integration TODO a.k.a coming soonContributing
Why Chewy?
Multi-model indices. Index classes are independent from ORM/ODM models. Now, implementing e.g. cross-model autocomplete is much easier. You can just define the index and work with it in an object-oriented style. You can define several types for index - one per indexed model. Every index is observable by all the related models. Most of the indexed models are related to other and sometimes it is necessary to denormalize this related data and put at the same object. For example, you need to index an array of tags together with an article. Chewy allows you to specify an updateable index for every model separately - so corresponding articles will be reindexed on any tag update. Bulk import everywhere. Chewy utilizes the bulk ES API for full reindexing or index updates. It also uses atomic updates. All the changed objects are collected inside the atomic block and the index is updated once at the end with all the collected objects. See Chewy.strategy(:atomic) for more details. Powerful querying DSL. Chewy has an ActiveRecord-style query DSL. It is chainable, mergeable and lazy, so you can produce queries in the most efficient way. It also has object-oriented query and filter builders. Support for ActiveRecord, Mongoid and Sequel.
Installation
Add this line to your application's Gemfile:
gem 'chewy'
And then execute:
$ bundle
Or install it yourself as:
$ gem install chewy
Usage
Client settings
There are two ways to configure the Chewy client: the Chewy.settings hash and chewy.yml
You can create this file manually or run rails g chewy:install.
# config/initializers/chewy.rbChewy.settings = {host: 'localhost:9250'} # do not use environments
# config/chewy.yml# separate environment configstest: host: 'localhost:9250' prefix: 'test'development: host: 'localhost:9200'
The resulting config merges both hashes. Client options are passed as is to Elasticsearch::Transport::Client except for the :prefix, which is used internally by Chewy to create prefixed index names:
Chewy.settings = {prefix: 'test'} UsersIndex.index_name # => 'test_users'
The logger may be set explicitly:
Chewy.logger = Logger.new(STDOUT)
See config.rb for more details.
Aws Elastic Search
If you would like to use AWS's ElasticSearch using an IAM user policy, you will need to sign your requests for the es:* action by injecting the appropriate headers passing a proc to transport_options.
Chewy.settings = { host: 'http://my-es-instance-on-aws.us-east-1.es.amazonaws.com:80', transport_options: { headers: { content_type: 'application/json' }, proc: -> (f) do f.request :aws_signers_v4, service_name: 'es', region: 'us-east-1', credentials: Aws::Credentials.new( ENV['AWS_ACCESS_KEY'], ENV['AWS_SECRET_ACCESS_KEY']) end } }
Index definition
Create /app/chewy/users_index.rb
class UsersIndex < Chewy::Indexend
Add one or more types mapping
class UsersIndex < Chewy::Index define_type User.active # or just model instead_of scope: define_type Userend
Newly-defined index type class is accessible via UsersIndex.user or UsersIndex::User
Add some type mappings
class UsersIndex < Chewy::Index define_type User.active.includes(:country, :badges, :projects) do field :first_name, :last_name # multiple fields without additional options field :email, analyzer: 'email' # Elasticsearch-related options field :country, value: ->(user) { user.country.name } # custom value proc field :badges, value: ->(user) { user.badges.map(&:name) } # passing array values to index field :projects do # the same block syntax for multi_field, if `:type` is specified field :title field :description # default data type is `string` # additional top-level objects passed to value proc: field :categories, value: ->(project, user) { project.categories.map(&:name) if user.active? } end field :rating, type: 'integer' # custom data type field :created, type: 'date', include_in_all: false, value: ->{ created_at } # value proc for source object context endend
See here for mapping definitions.
Add some index- and type-related settings. Analyzer repositories might be used as well. See Chewy::Index.settings docs for details:
class UsersIndex < Chewy::Index settings analysis: { analyzer: { email: { tokenizer: 'keyword', filter: ['lowercase'] } } } define_type User.active.includes(:country, :badges, :projects) do root date_detection: false do template 'about_translations.*', type: 'text', analyzer: 'standard' field :first_name, :last_name field :email, analyzer: 'email' field :country, value: ->(user) { user.country.name } field :badges, value: ->(user) { user.badges.map(&:name) } field :projects do field :title field :description end field :about_translations, type: 'object' # pass object type explicitly if necessary field :rating, type: 'integer' field :created, type: 'date', include_in_all: false, value: ->{ created_at } end endend
See index settings here. See root object settings here.
See mapping.rb for more details.
Add model-observing code
class User < ActiveRecord::Base update_index('users#user') { self } # specifying index, type and back-reference # for updating after user save or destroyendclass Country < ActiveRecord::Base has_many :users update_index('users#user') { users } # return single object or collectionendclass Project < ActiveRecord::Base update_index('users#user') { user if user.active? } # you can return even `nil` from the back-referenceendclass Badge < ActiveRecord::Base has_and_belongs_to_many :users update_index('users') { users } # if index has only one type # there is no need to specify updated typeendclass Book < ActiveRecord::Base update_index(->(book) {"books#book_#{book.language}"}) { self } # dynamic index and type with proc. # For book with language == "en" # this code will generate `books#book_en`end
Also, you can use the second argument for method name passing:
update_index('users#user', :self)update_index('users#user', :users)
In the case of a belongs_to association you may need to update both associated objects, previous and current:
class City < ActiveRecord::Base belongs_to :country update_index('cities#city') { self } update_index 'countries#country' do # For the latest active_record changed values are # already in `previous_changes` hash, # but for mongoid you have to use `changes` hash previous_changes['country_id'] || country endend
You can observe Sequel models in the same way as ActiveRecord:
class User < Sequel::Model update_index('users#user') { self }end
However, to make it work, you must load the chewy plugin into Sequel model:
Sequel::Model.plugin :chewy_observe # for all models, or...User.plugin :chewy_observe # just for User
Type default import options
Every type has default_import_options configuration to specify, suddenly, default import options:
class ProductsIndex < Chewy::Index define_type Post.includes(:tags) do default_import_options batch_size: 100, bulk_size: 10.megabytes, refresh: false field :name field :tags, value: -> { tags.map(&:name) } endend
See import.rb for available options.
Multi (nested) and object field types
To define an objects field you can simply nest fields in the DSL:
field :projects do field :title field :descriptionend
This will automatically set the type or root field to object. You may also specify type: 'objects' explicitly.
To define a multi field you have to specify any type except for object or nested in the root field:
field :full_name, type: 'text', value: ->{ full_name.strip } do field :ordered, analyzer: 'ordered' field :untouched, index: 'not_analyzed'end
The value: option for internal fields will no longer be effective.
Parent and children types
To define parent type for a given index_type, you can include root options for the type where you can specify parent_type and parent_id
define_type User.includes(:account) do root parent: 'account', parent_id: ->{ account_id } do field :created_at, type: 'date' field :task_id, type: 'integer' endend
Geo Point fields
You can use Elasticsearch's geo mapping with the geo_point field type, allowing you to query, filter and order by latitude and longitude. You can use the following hash format:
field :coordinates, type: 'geo_point', value: ->{ {lat: latitude, lon: longitude} }
or by using nested fields:
field :coordinates, type: 'geo_point' do field :lat, value: ->{ latitude } field :long, value: ->{ longitude }end
See the section on Script fields for details on calculating distance in a search.
Crutches™ technology
Assume you are defining your index like this (product has_many categories through product_categories):
class ProductsIndex < Chewy::Index define_type Product.includes(:categories) do field :name field :category_names, value: ->(product) { product.categories.map(&:name) } # or shorter just -> { categories.map(&:name) } endend
Then the Chewy reindexing flow will look like the following pseudo-code (even in Mongoid):
Product.includes(:categories).find_in_batches(1000) do |batch| bulk_body = batch.map do |object| {name: object.name, category_names: object.categories.map(&:name)}.to_json end # here we are sending every batch of data to ES Chewy.client.bulk bulk_bodyend
But in Rails 4.1 and 4.2 you may face a problem with slow associations (take a look at https://github.com/rails/rails/pull/19423). Also, there might be really complicated cases when associations are not applicable.
Then you can replace Rails associations with Chewy Crutches™ technology:
class ProductsIndex < Chewy::Index define_type Product do crutch :categories do |collection| # collection here is a current batch of products # data is fetched with a lightweight query without objects initialization data = ProductCategory.joins(:category).where(product_id: collection.map(&:id)).pluck(:product_id, 'categories.name') # then we have to convert fetched data to appropriate format # this will return our data in structure like: # {123 => ['sweets', 'juices'], 456 => ['meat']} data.each.with_object({}) { |(id, name), result| (result[id] ||= []).push(name) } end field :name # simply use crutch-fetched data as a value: field :category_names, value: ->(product, crutches) { crutches.categories[product.id] } endend
An example flow will look like this:
Product.includes(:categories).find_in_batches(1000) do |batch| crutches[:categories] = ProductCategory.joins(:category).where(product_id: batch.map(&:id)).pluck(:product_id, 'categories.name') .each.with_object({}) { |(id, name), result| (result[id] ||= []).push(name) } bulk_body = batch.map do |object| {name: object.name, category_names: crutches[:categories][object.id]}.to_json end Chewy.client.bulk bulk_bodyend
So Chewy Crutches™ technology is able to increase your indexing performance in some cases up to a hundredfold or even more depending on your associations complexity.
Witchcraft™ technology
One more experimental technology to increase import performance. As far as you know, chewy defines value proc for every imported field in mapping, so at the import time each of this procs is executed on imported object to extract result document to import. It would be great for performance to use one huge whole-document-returning proc instead. So basically the idea or Witchcraft™ technology is to compile a single document-returning proc from the type definition.
define_type Product do witchcraft! field :title field :tags, value: -> { tags.map(&:name) } field :categories do field :name, value: -> (product, category) { category.name } field :type, value: -> (product, category, crutch) { crutch.types[category.name] } endend
The type definition above will be compiled to something close to:
-> (object, crutches) do { title: object.title, tags: object.tags.map(&:name), categories: object.categories.map do |object2| { name: object2.name type: crutches.types[object2.name] } end }end
And don't even ask how is it possible, it is a witchcraft. Obviously not every type of definition might be compiled. There are some restrictions:
Use reasonable formatting to make method_source be able to extract field value proc sources.Value procs with splat arguments are not supported right now.If you are generating fields dynamically use value proc with arguments, argumentless value procs are not supported yet:
[:first_name, :last_name].each do |name| field name, value: -> (o) { o.send(name) }end
However, it is quite possible that your type definition will be supported by Witchcraft™ technology out of the box in the most of the cases.
Raw Import
Another way to speed up import time is Raw Imports. This technology is only available in ActiveRecord adapter. Very often, ActiveRecord model instantiation is what consumes most of the CPU and RAM resources. Precious time is wasted on converting, say, timestamps from strings and then serializing them back to strings. Chewy can operate on raw hashes of data directly obtained from the database. All you need is to provide a way to convert that hash to a lightweight object that mimics the behaviour of the normal ActiveRecord object.
class LightweightProduct def initialize(attributes) @attributes = attributes end # Depending on the database, `created_at` might # be in different formats. In PostgreSQL, for example, # you might see the following format: # "2016-03-22 16:23:22" # # Taking into account that Elastic expects something different, # one might do something like the following, just to avoid # unnecessary String -> DateTime -> String conversion. # # "2016-03-22 16:23:22" -> "2016-03-22T16:23:22Z" def created_at @attributes['created_at'].tr(' ', 'T') << 'Z' endenddefine_type Product do default_import_options raw_import: ->(hash) { LightweightProduct.new(hash) } field :created_at, 'datetime'end
Also, you can pass :raw_import option to the import method explicitly.
Index creation during import
By default, when you perform import Chewy checks whether an index exists and creates it if it's absent. You can turn off this feature to decrease Elasticsearch hits count. To do so you need to set skip_index_creation_on_import parameter to false in your config/chewy.yml
Journaling
You can record all actions that were made to the separate journal index in ElasticSearch. When you create/update/destroy your documents, it will be saved in this special index. If you make something with a batch of documents (e.g. during index reset) it will be saved as a one record, including primary keys of each document that was affected. Common journal record looks like this:
{ "action": "index", "object_id": [1, 2, 3], "index_name": "...", "type_name": "...", "created_at": "
This feature is turned off by default. But you can turn it on by setting journal setting to true in config/chewy.yml. Also, you can specify journal index name. For example:
# config/chewy.ymlproduction: journal: true journal_name: my_super_journal
Also, you can provide this option while you're importing some index:
CityIndex.import journal: true
Or as a default import option for an index:
class CityIndex define_type City do default_import_options journal: true endend
You may be wondering why do you need it? The answer is simple: not to lose the data.
Imagine that you reset your index in a zero-downtime manner (to separate index), and at the meantime somebody keeps updating the data frequently (to old index). So all these actions will be written to the journal index and you'll be able to apply them after index reset using the Chewy::Journal interface.
Types access
You can access index-defined types with the following API:
UsersIndex::User # => UsersIndex::UserUsersIndex.type_hash['user'] # => UsersIndex::UserUsersIndex.type('user') # => UsersIndex::UserUsersIndex.type('foo') # => raises error UndefinedType("Unknown type in UsersIndex: foo")UsersIndex.types # => [UsersIndex::User]UsersIndex.type_names # => ['user']
Index manipulation
UsersIndex.delete # destroy index if it existsUsersIndex.delete!UsersIndex.createUsersIndex.create! # use bang or non-bang methodsUsersIndex.purgeUsersIndex.purge! # deletes then creates indexUsersIndex::User.import # import with 0 arguments process all the data specified in type definition # literally, User.active.includes(:country, :badges, :projects).find_in_batchesUsersIndex::User.import User.where('rating > 100') # or import specified users scopeUsersIndex::User.import User.where('rating > 100').to_a # or import specified users arrayUsersIndex::User.import [1, 2, 42] # pass even ids for import, it will be handled in the most effective wayUsersIndex::User.import User.where('rating > 100'), update_fields: [:email] # if update fields are specified - it will update their values only with the `update` bulk action.UsersIndex.import # import every defined typeUsersIndex.import user: User.where('rating > 100') # import only active users to `user` type. # Other index types, if exists, will be imported with default scope from the type definition.UsersIndex.reset! # purges index and imports default data for all types
If the passed user is #destroyed?, or satisfies a delete_if type option, or the specified id does not exist in the database, import will perform delete from index action for this object.
define_type User, delete_if: :deleted_atdefine_type User, delete_if: -> { deleted_at }define_type User, delete_if: ->(user) { user.deleted_at }
See actions.rb for more details.
Index update strategies
Assume you've got the following code:
class City < ActiveRecord::Base update_index 'cities#city', :selfendclass CitiesIndex < Chewy::Index define_type City do field :name endend
If you do something like City.first.save! you'll get an UndefinedUpdateStrategy exception instead of the object saving and index updating. This exception forces you to choose an appropriate update strategy for the current context.
If you want to return to the pre-0.7.0 behavior - just set Chewy.root_strategy = :bypass.
:atomic
The main strategy here is :atomic. Assume you have to update a lot of records in the db.
Chewy.strategy(:atomic) do City.popular.map(&:do_some_update_action!)end
Using this strategy delays the index update request until the end of the block. Updated records are aggregated and the index update happens with the bulk API. So this strategy is highly optimized.
:resque
This does the same thing as :atomic, but asynchronously using resque. The default queue name is chewy. Patch Chewy::Strategy::Resque::Worker for index updates improving.
Chewy.strategy(:resque) do City.popular.map(&:do_some_update_action!)end
:sidekiq
This does the same thing as :atomic, but asynchronously using sidekiq. Patch Chewy::Strategy::Sidekiq::Worker for index updates improving.
Chewy.strategy(:sidekiq) do City.popular.map(&:do_some_update_action!)end
:active_job
This does the same thing as :atomic, but using ActiveJob. This will inherit the ActiveJob configuration settings including the active_job.queue_adapter setting for the environment. Patch Chewy::Strategy::ActiveJob::Worker for index updates improving.
Chewy.strategy(:active_job) do City.popular.map(&:do_some_update_action!)end
:shoryuken
This does the same thing as :atomic, but asynchronously using shoryuken. Patch Chewy::Strategy::Shoryuken::Worker for index updates improving.
Chewy.strategy(:shoryuken) do City.popular.map(&:do_some_update_action!)end
:urgent
The following strategy is convenient if you are going to update documents in your index one by one.
Chewy.strategy(:urgent) do City.popular.map(&:do_some_update_action!)end
This code will perform City.popular.count requests for ES documents update.
It is convenient for use in e.g. the Rails console with non-block notation:
> Chewy.strategy(:urgent)> City.popular.map(&:do_some_update_action!)
:bypass
The bypass strategy simply silences index updates.
Nesting
Strategies are designed to allow nesting, so it is possible to redefine it for nested contexts.
Chewy.strategy(:atomic) do city1.do_update! Chewy.strategy(:urgent) do city2.do_update! city3.do_update! # there will be 2 update index requests for city2 and city3 end city4..do_update! # city1 and city4 will be grouped in one index update requestend
Non-block notation
It is possible to nest strategies without blocks:
Chewy.strategy(:urgent)city1.do_update! # index updatedChewy.strategy(:bypass)city2.do_update! # update bypassedChewy.strategy.popcity3.do_update! # index updated again
Designing your own strategies
See strategy/base.rb for more details. See strategy/atomic.rb for an example.
Rails application strategies integration
There are a couple of predefined strategies for your Rails application. Initially, the Rails console uses the :urgent strategy by default, except in the sandbox case. When you are running sandbox it switches to the :bypass strategy to avoid polluting the index.
Migrations are wrapped with the :bypass strategy. Because the main behavior implies that indices are reset after migration, there is no need for extra index updates. Also indexing might be broken during migrations because of the outdated schema.
Controller actions are wrapped with the configurable value of Chewy.request_strategy and defaults to :atomic. This is done at the middleware level to reduce the number of index update requests inside actions.
It is also a good idea to set up the :bypass strategy inside your test suite and import objects manually only when needed, and use Chewy.massacre when needed to flush test ES indices before every example. This will allow you to minimize unnecessary ES requests and reduce overhead.
RSpec.configure do |config| config.before(:suite) do Chewy.strategy(:bypass) endend
ActiveSupport::Notifications support
Chewy has notifying the following events:
search_query.chewy payload
payload[:index]: requested index classpayload[:request]: request hash
import_objects.chewy payload
payload[:type]: currently imported type payload[:import]: imports stats, total imported and deleted objects count:{index: 30, delete: 5} payload[:errors]: might not exists. Contains grouped errors with objects ids list:{index: { 'error 1 text' => ['1', '2', '3'], 'error 2 text' => ['4']}, delete: { 'delete error text' => ['10', '12']}}
NewRelic integration
To integrate with NewRelic you may use the following example source (config/initializers/chewy.rb):
require 'new_relic/agent/instrumentation/evented_subscriber'class ChewySubscriber < NewRelic::Agent::Instrumentation::EventedSubscriber def start(name, id, payload) event = ChewyEvent.new(name, Time.current, nil, id, payload) push_event(event) end def finish(_name, id, _payload) pop_event(id).finish end class ChewyEvent < NewRelic::Agent::Instrumentation::Event OPERATIONS = { 'import_objects.chewy' => 'import', 'search_query.chewy' => 'search', 'delete_query.chewy' => 'delete' }.freeze def initialize(*args) super @segment = start_segment end def start_segment segment = NewRelic::Agent::Transaction::DatastoreSegment.new product, operation, collection, host, port if (txn = state.current_transaction) segment.transaction = txn end segment.notice_sql @payload[:request].to_s segment.start segment end def finish if (txn = state.current_transaction) txn.add_segment @segment end @segment.finish end private def state @state ||= NewRelic::Agent::TransactionState.tl_get end def product 'Elasticsearch' end def operation OPERATIONS[name] end def collection payload.values_at(:type, :index) .reject { |value| value.try(:empty?) } .first .to_s end def host Chewy.client.transport.hosts.first[:host] end def port Chewy.client.transport.hosts.first[:port] end endendActiveSupport::Notifications.subscribe(/.chewy$/, ChewySubscriber.new)
Search requests
Long story short: there is a new DSL that supports ES2 and ES5, the previous DSL version (which supports ES1 and ES2) documentation was moved to LEGACY_DSL.md.
If you want to use the old DSL - simply do Chewy.search_class = Chewy::Query somewhere before indices are initialized.
The new DSL is enabled by default, here is a quick introduction.
Composing requests
The request DSL have the same chainable nature as AR or Mongoid ones. The main class is Chewy::Search::Request. It is possible to perform requests on behalf of indices or types:
PlaceIndex.query(match: {name: 'London'}) # returns documents of any typePlaceIndex::City.query(match: {name: 'London'}) # returns cities only.
Main methods of the request DSL are: query, filter and post_filter, it is possible to pass pure query hashes or use elasticsearch-dsl. Also, there is an additional
PlaceIndex .filter(term: {name: 'Bangkok'}) .query { match name: 'London' } .query.not(range: {population: {gt: 1_000_000}})
See https://elastic.co/guide/en/elasticsearch/reference/current/query-dsl.html and https://github.com/elastic/elasticsearch-ruby/tree/master/elasticsearch-dsl for more details.
An important part of requests manipulation is merging. There are 4 methods to perform it: merge, and, or, not. See Chewy::Search::QueryProxy for details. Also, only and except methods help to remove unneeded parts of the request.
Every other request part is covered by a bunch of additional methods, see Chewy::Search::Request for details:
PlaceIndex.limit(10).offset(30).order(:name, {population: {order: :desc}})
Request DSL also provides additional scope actions, like delete_all, exists?, count, pluck, etc.
Pagination
The request DSL supports pagination with Kaminari and WillPaginate. An appropriate extension is enabled on initializtion if any of libraries is available. See Chewy::Search and Chewy::Search::Pagination namespace for details.
Named scopes
Chewy supports named scopes functionality. There is no specialized DSL for named scopes definition, it is simply about defining class methods.
See Chewy::Search::Scoping for details.
Scroll API
ElasticSearch scroll API is utilized by a bunch of methods: scroll_batches, scroll_hits, scroll_wrappers and scroll_objects.
See Chewy::Search::Scrolling for details.
Loading objects
It is possible to load ORM/ODM source objects with the objects method. To provide additional loading options use load method:
PlacesIndex.load(scope: -> { active }).to_a # to_a returns `Chewy::Type` wrappers.PlacesIndex.load(scope: -> { active }).objects # An array of AR source objects.
See Chewy::Search::Loader for more details.
In case when it is necessary to iterate through both of the wrappers and objects simultaneously, object_hash method helps a lot:
scope = PlacesIndex.load(scope: -> { active })scope.each do |wrapper| scope.object_hash[wrapper]end
Legacy DSL incompatibilities
Filters advanced block DSL is not supported anymore, elasticsearch-dsl is used instead.Things like query_mode and filter_mode are in past, use advanced DSL to achieve similar behavior. See Chewy::Search::QueryProxy for details.preload method is no more, the collection returned by scope doesn't depend on loading options, scope always returns Chewy::Type wrappers. To get ORM/ODM objects, use #objects method.Some of the methods have changed their purpose: only was used to filter fields before, now it filters the scope. To filter fields use source or stored_fields.types! method is no more, use except(:types).types(...)Named aggregations are not supported, use named scopes instead.A lot of query-level methods were not ported: everything that is related to boost and scoring. Use query manipulation to provide them.Chewy::Type#_object returns nil always. Use Chewy::Search::Response#object_hash instead.
Rake tasks
For a Rails application, some index-maintaining rake tasks are defined.
chewy:reset
Performs zero-downtime reindexing as described here. So the rake task creates a new index with unique suffix and then simply aliases it to the common index name. The previous index is deleted afterwards (see Chewy::Index.reset! for more details).
rake chewy:reset # resets all the existing indicesrake chewy:reset[users] # resets UsersIndex onlyrake chewy:reset[users,places] # resets UsersIndex and PlacesIndexrake chewy:reset[-users,places] # resets every index in the application except specified ones
chewy:upgrade
Performs reset exactly the same way as chewy:reset does, but only when the index specification (setting or mapping) was changed.
It works only when index specification is locked in Chewy::Stash::Specification index. The first run will reset all indexes and lock their specifications.
See Chewy::Stash::Specification and Chewy::Index::Specification for more details.
rake chewy:upgrade # upgrades all the existing indicesrake chewy:upgrade[users] # upgrades UsersIndex onlyrake chewy:upgrade[users,places] # upgrades UsersIndex and PlacesIndexrake chewy:upgrade[-users,places] # upgrades every index in the application except specified ones
chewy:update
It doesn't create indexes, it simply imports everything to the existing ones and fails if the index was not created before.
Unlike reset or upgrade tasks, it is possible to pass type references to update the particular type. In index name is passed without the type specified, it will update all the types defined for this index.
rake chewy:update # updates all the existing indicesrake chewy:update[users] # updates UsersIndex onlyrake chewy:update[users,places#city] # updates the whole UsersIndex and PlacesIndex::City typerake chewy:update[-users,places#city] # updates every index in the application except every type defined in UsersIndex and the rest of the types defined in PlacesIndex
chewy:sync
Provides a way to synchronize outdated indexes with the source quickly and without doing a full reset.
Arguments are similar to the ones taken by chewy:update task. It is possible to specify a particular type or a whole index.
See Chewy::Type::Syncer for more details.
rake chewy:sync # synchronizes all the existing indicesrake chewy:sync[users] # synchronizes UsersIndex onlyrake chewy:sync[users,places#city] # synchronizes the whole UsersIndex and PlacesIndex::City typerake chewy:sync[-users,places#city] # synchronizes every index in the application except every type defined in UsersIndex and the rest of the types defined in PlacesIndex
chewy:deploy
This rake task is especially useful during the production deploy. It is a combination of chewy:upgrade and chewy:sync and the latter is called only for the indexes that were not reset during the first stage.
It is not possible to specify any particular types/indexes for this task as it doesn't make much sense.
Right now the approach is that if some data had been updated, but index definition was not changed (no changes satisfying the synchronization algorithm were done), it would be much faster to perform manual partial index update inside data migrations or even manually after the deploy.
Also, there is always full reset alternative with rake chewy:reset.
Parallelizing rake tasks
Every task described above has its own parallel version. Every parallel rake task takes the number for processes for execution as the first argument and the rest of the arguments are exactly the same as for the non-parallel task version.
https://github.com/grosser/parallel gem is required to use these tasks.
If the number of processes is not specified explicitly - parallel gem tries to automatically derive the number of processes to use.
rake chewy:parallel:resetrake chewy:parallel:upgrade[4]rake chewy:parallel:update[4,places#city]rake chewy:parallel:sync[4,-users]rake chewy:parallel:deploy[4] # performs parallel upgrade and parallel sync afterwards
chewy:journal
This namespace contains two tasks for the journal manipulations: chewy:journal:apply and chewy:journal:clean. Both are taking time as the first argument (optional for clean) and a list of indexes/types exactly as the tasks above. Time can be in any format parsable by ActiveSupport.
rake chewy:journal:apply["$(date -v-1H -u +%FT%TZ)"] # apply journaled changes for the past hourrake chewy:journal:apply["$(date -v-1H -u +%FT%TZ)",users] # apply journaled changes for the past hour on UsersIndex only
Rspec integration
Just add require 'chewy/rspec' to your spec_helper.rb and you will get additional features: See update_index.rb for more details.
Minitest integration
Add require 'chewy/minitest' to your test_helper.rb, and then for tests which you'd like indexing test hooks, include Chewy::Minitest::Helpers.
Since you can set :bypass strategy for test suites and manually handle import for the index and manually flush test indices using Chewy.massacre. This will help reduce unnecessary ES requests
But if you require chewy to index/update model regularly in your test suite then you can specify :urgent strategy for documents indexing. Add Chewy.strategy(:urgent) to test_helper.rb.
DatabaseCleaner
If you use DatabaseCleaner in your tests with the transaction strategy, you may run into the problem that ActiveRecord's models are not indexed automatically on save despite the fact that you set the callbacks to do this with the update_index method. The issue arises because chewy indices data on after_commit run as default, but all after_commit callbacks are not run with the DatabaseCleaner's' transaction strategy. You can solve this issue by changing the Chewy.use_after_commit_callbacks option. Just add the following initializer in your Rails application:
#config/initializers/chewy.rbChewy.use_after_commit_callbacks = !Rails.env.test?
TODO a.k.a coming soon:
Typecasting supportupdate_all supportMaybe, closer ORM/ODM integration, creating index classes implicitly
Contributing
Fork it (http://github.com/toptal/chewy/fork)Create your feature branch (git checkout -b my-new-feature)Implement your changes, cover it with specs and make sure old specs are passingCommit your changes (git commit -am 'Add some feature')Push to the branch (git push origin my-new-feature)Create new Pull Request
Use the following Rake tasks to control the Elasticsearch cluster while developing.
rake elasticsearch:start # start Elasticsearch cluster on 9250 port for testsrake elasticsearch:stop # stop Elasticsearch
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。


发表评论

暂时没有评论,来抢沙发吧~