
洞察掌握android电视app开发中的安全与合规策略,提升企业运营效率
3026
2022-10-01

Apache Pulsar 是灵活的发布-订阅消息系统(Flexible Pub/Sub messaging),采用分层分片架构。
关于发布-订阅模型的概念,主要从多租户、灵活的消息系统、云原生构架、分片的流(Segmented Streams)等方面来强调 Apache Pulsar 的功能和特性。
租户和命名空间(namespace)是 Pulsar 支持多租户的两个核心概念。
在租户级别,Pulsar 为特定的租户预留合适的存储空间、应用授权与认证机制。
在命名空间级别,Pulsar 有一系列的配置策略(policy),包括存储配额、流控、消息过期策略和命名空间之间的隔离策略。
Pulsar 做了队列模型和流模型的统一,在 Topic 级别只需保存一份数据,同一份数据可多次消费。以流式、队列等方式计算不同的订阅模型大大提升了灵活度。
Pulsar 使用计算与存储分离的云原生架构,数据从 Broker 搬离,存在共享存储内部。上层是无状态 Broker,复制消息分发和服务;下层是持久化的存储层 Bookie 集群。Pulsar 存储是分片的,这种构架可以避免扩容时受限制,实现数据的独立扩展和快速恢复。
Pulsar 将无界的数据看作是分片的流,分片分散存储在分层存储(tiered storage)、BookKeeper 集群和 Broker 节点上,而对外提供一个统一的、无界数据的视图。其次,不需要用户显式迁移数据,减少存储成本并保持近似无限的存储。
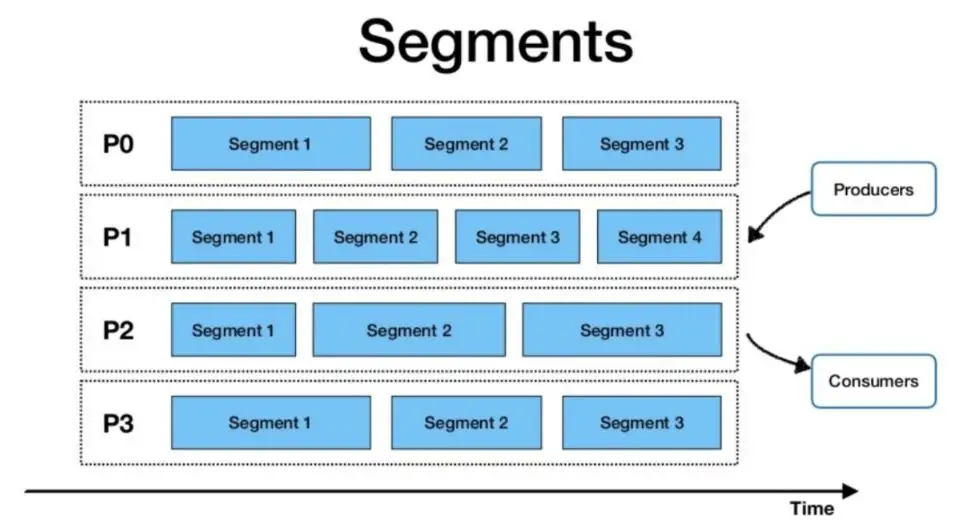
Pulsar 中的跨地域复制是将 Pulsar 中持久化的消息在多个集群间备份。在 Pulsar 2.4.0 中新增了复制订阅模式(Replicated-subscriptions),在某个集群失效情况下,该功能可以在其他集群恢复消费者的消费状态,从而达到热备模式下消息服务的高可用。

层级存储的优势:
Infinite Stream: 以流的方式永久保存原始数据
分区的容量不再受限
充分利⽤云存储或现有的廉价存储 ( 例如 HDFS)
数据统⼀表征:客户端无需关⼼数据究竟存储在哪⾥

>>> Spark
https://github.com/streamnative/pulsar-spark
自 Spark 2.2 版本 Structured Streaming 正式发布,Spark 只保留了 SparkSession 作为主程序入口,你只需编写 DataSet/DataFrame API 程序,以声明形式对数据的操作,而将具体的查询优化与批流处理执行的细节交由 Spark SQL 引擎进行处理。
对于一个数据处理作业,需要定义 DataFrame 的产生、变换和写出三个部分,而将 Pulsar 作为流数据平台与 Spark 进行集成正是要解决如何从 Pulsar 中读取数据(Source)和如何向 Pulsar 写出运算结果(Sink)两个问题。
>>> Flink
https://github.com/streamnative/pulsar-flink
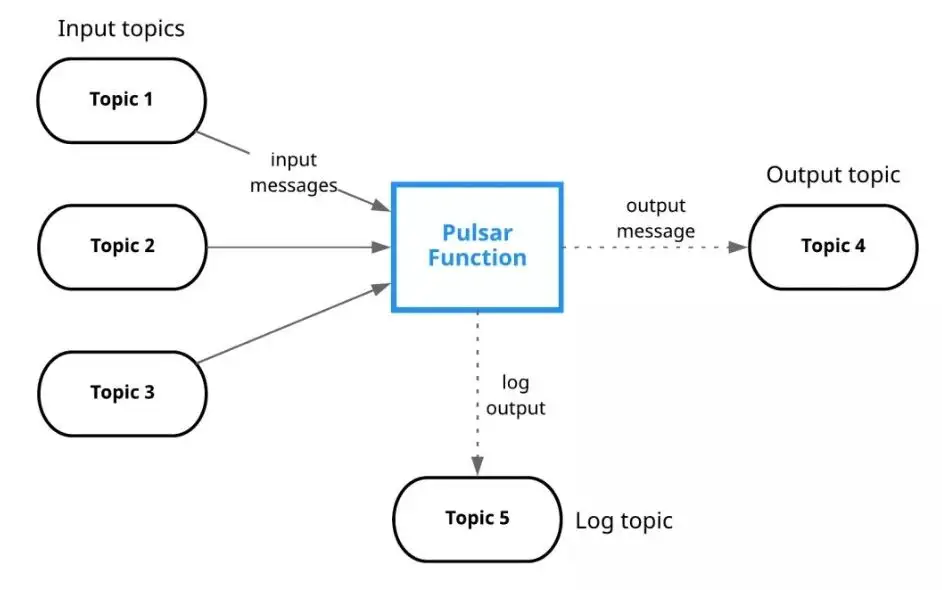
Pulsar 能以不同的方式与 Apache Flink 融合,一些可行的融合包括,使用流式连接器(Streaming Connectors)支持流式工作负载,或使用批式源连接器(Batch Source Connectors)支持批式工作负载。
Pulsar 还提供了对 Schema 的原生支持,可以与 Flink 集成并提供对数据的结构化访问,例如,使用 Flink SQL 在 Pulsar 中查询数据。另外,还能将 Pulsar 作为 Flink 的状态后端。由于 Pulsar 具有分层架构(Apache BookKeeper 支持下的 Streams 和 Segmented Streams),因此可以将 Pulsar 作为存储层并存储 Flink 状态。
>>> Presto
Pulsar 使用 Pulsar SQL 查询历史消息,使用 Presto 引擎高效查询 BookKeeper 中的数据。Presto 是用于大数据解决方案的高性能分布式 SQL 查询引擎,可以在单个查询中查询多个数据源的数据。如下是使用 Pulsar SQL 查询的示例。
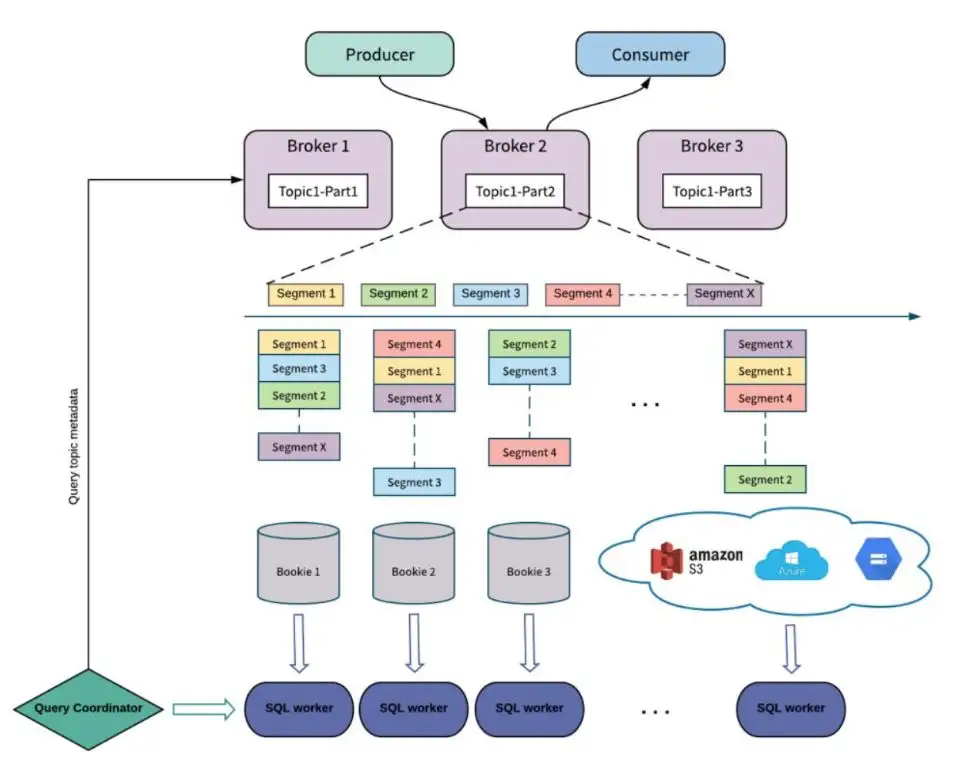
批处理是对有界的数据进行处理,通常数据以文件的形式存储在 HDFS 等分布式文件系统中。流处理将数据看作是源源不断的流,流处理系统以发布/订阅方式消费流数据。当前的大数据处理框架,例如 Spark、Flink 在 API 层和执行层正在逐步融合批、流作业的提交与执行,而 Pulsar 由于可以存储无限的流数据,是极佳的统一数据存储平台。
>>> Pulsar Manager
https://github.com/apache/pulsar-manager
此前,Pulsar 已有监控工具 Dashboard ,但它侧重于对 Pulsar 的简单监控(如搜集并展示 Tenants、Namespaces、Topics 和 Subscriptions 等监控信息),无法进行高阶管理(如对 Tenant、Namespace 和 Topic 等进行增加、删除、更新等操作),尤其是集群数量较多时,仅通过命令行工具 pulsar-admin 进行管理,效果却不尽人意,而 Apache Pulsar Manager 正是对这一空白的补充。
Apache Pulsar Manager 是一个基于网页的 GUI 管理和监控工具,帮助 Pulsar 管理员和用户管理和监控 Tenant、Namespace、Topic、Subscription、Broker 和 Cluster 等,并支持动态配置多种环境。
>>> Kafka on Pulsar (KoP)
KoP 是 StreamNative 的一大创新和尝试。StreamNative 通过 KoP 帮助用户不受应用迁移和重写所困扰,高效便捷地帮助用户解决了痛点问题,并开创性地连接了 Pulsar 和 Kafka 两大开源社区。
>>> Pulsar-io-Kafka
https://github.com/streamnative/pulsar-io-kafka
对于实时数据处理中 Kafka 数据的导入,使用 StreamNative 开源的 pulsar-io-kafka 项目,可以把 Kakfa 中的数据读出并写入到 Pulsar 中。
上述就是小编为大家整理的关于Apache Pulsar 简介(什么是Apache Pulsar)的内容。
国内(北京、上海、广州、深圳、成都、重庆、杭州、西安、武汉、苏州、郑州、南京、天津、长沙、东莞、宁波、佛山、合肥、青岛)凡泰极客软件分析、比较及推荐。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。


发表评论

暂时没有评论,来抢沙发吧~