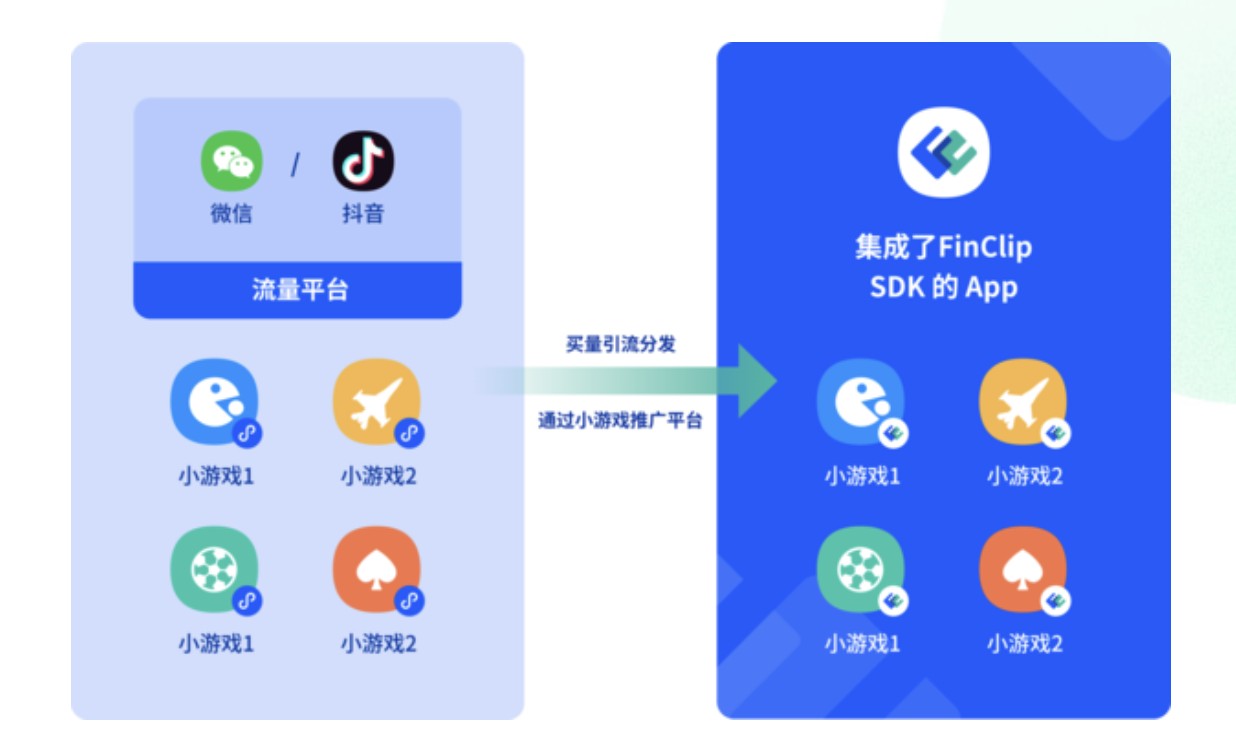
如何利用小游戏开发框架提升企业小程序的用户体验与运营效率
825
2022-09-28

KUBERNETES服务健康检查功能梳理

简介
K8S服务健康检查从两个维度进行,分别为:就绪状态检查(readiness)和存活状态检查(liveness)。
存活探针和就绪探针被称作健康检查。这些容器探针是一些周期性运行的小进程,这些探针返回的结果如(成功,失败或者未知)反映容器在Kubernetes的状态。基于结果Kubernetes会判断如何处理每个容器,以保障集群服务高可用性和业务与连续性。
名词解释
readiness:用于探测HTTP是否就绪,是否可以接受业务请求。如果ReadinessProbe探针检测到失败,则Pod的状态被修改。Endpoint Controller将从Service的Endpoint中删除包含该容器所在Pod的Endpoint。liveness:用于探测HTTP是否存活,如果LivenessProbe探针探测到容器不健康,则kubelet杀掉该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含LivenessProbe探针,则kubelet认为该容器的LivenessProbe探针返回的值永远是“Success”。
使用场景
readiness 使用场景:
Pod对象启动后,容器应用通常需要一段时间才能完成其初始化过程,例如加载配置或数据,甚至有些程序需要运行某类的预热过程,若在此阶段完成之前接入客户端的请求,势必会因为等待太久而影响用户体验,这时就需要就绪探针。如果没有将就绪探针添加到pod中,它们几乎会立即成为服务端点。如果应用程序需要很长时间才能开始监听传入连接,则在服务启动但尚未准备好接收传入连接时,客户端请求将被转发到该pod。因此,客户端会看到"连接被拒绝"类型的错误。
liveness 使用场景:
Liveness探针让Kubernetes知道你的应用程序是状态是否健康。但是如果liveness检查结果是fail就会直接kill container,当然如果你的restart policy 是always 会重启pod。备注:pod重启策略:PodSpec 中有一个 restartPolicy 字段,可能的值为 Always、OnFailure 和 Never 。默认为Always。
支持检测类型:
Kubernetes 支持三种方式来执行探针:exec:在容器中执行一个命令,如果命令退出码返回0则表示探测成功,否则表示失败;tcpSocket:对指定的容IP及端口执行一个TCP检查,如果端口是开放的则表示探测成功,否则表示失败;[200,300) 中,则一切正常。如果存活探测器的状态代码是 4xx 或 5xx ,则代表pod已被重启。如果就绪探测器的状态代码是 4xx 或 5xx ,那么pod会被标记为不健康,并且Kubernetes为了提高可靠性和正常运行时间将不会再将HTTP请求转发给它。
探测执行返回结果类型
有以下三种返回结果,每次仅会返回一种:Success:Container通过了检查。Failure:Container未通过检查。Unknown:未能执行检查,因此不采取任何措施。
探测(健康检查)配置参数
通用配置,通过下面的配置能准确的控制 liveness 和 readiness 检查时间策略:initialDelaySeconds:容器启动后第一次执行探测是需要等待多少秒。periodSeconds:执行探测的频率。默认是10秒,最小1秒。timeoutSeconds:探测超时时间。默认1秒,最小1秒。successThreshold:探测失败后,最少连续探测成功多少次才被认定为成功。默认是 1。对于 liveness 必须是 1。最小值是 1。failureThreshold:探测成功后,最少连续探测失败多少次才被认定为失败。默认是 3。最小值是 1。HTTP probe 中可以给 pod 的 IP。您可能想在 header 中设置 “Host” 而不是使用 IP。scheme:连接使用的 schema,默认HTTP。path: 访问的HTTP server 的 path。header。HTTP运行重复的 header。port:访问的容器的端口名字或者端口号。端口号必须介于 1 和 65525 之间。
健康检查的最佳实践列表:
建议应用程序开发人员遵循最佳实践如下:
1:存活和就绪的结果处理程序需要是互相独立的程序接口:
如前所述,对于在K8s中部署的每个产品服务,应该提供2个接口分别处理HTTP请求“存活”和“就绪”的健康检查,确保接口能够完成健康检查使命。
2:不要把“存活/就绪”探针的逻辑与你的程序解耦:
这适用于作业处理应用程序。对于K8s集群确保服务容器内运行应用程序状态正常非常重要,集群能够帮助我们对服务实施自动健康检查。如果存活/就绪逻辑被解耦了在新进程中运行,则结果不准确。不要在“存活”处理程序里实现任何逻辑判断,如果进程正在运行,直接返回状态200,如果不是,则返回5xx或者true、false。让liveness健康检查快速的获取状态代码来做出决定,返回异常则Kubernetes会重新启动pod。提高服务的可靠性。
3:在“就绪”探针的处理程序中实现逻辑,以便提供有关应用程序准备情况的详情:
就绪探针让K8s知道pod是否已准备好接收HTTP请求。作为开发人员,在此处实现一些逻辑来检查应用程序的所有后端依赖的可用性非常重要。当实现就绪处理程序时,需要清楚的知道您的应用程序依赖于哪些功能。换句话说,在就绪处理程序里,需要运行所有步骤以保证应用程序已准备好接收和处理版本:1.6+镜像:nginx
就绪检查 5 秒一次;
readinessProbe: failureThreshold: 3 - name: Host value: localhost path: / port: 80 scheme: HTTP initialDelaySeconds: 10 periodSeconds: 5
存活状态检查 9 秒一次:
livenessProbe: failureThreshold: 3 - name: Host value: 127.0.0.1 path: /50x.html port: 80 scheme: HTTP initialDelaySeconds: 60 periodSeconds: 9 successThreshold: 1 timeoutSeconds: 200
服务输出日志
可以看到服务输出日志如下:
[30/Mar/2020:12:26:16 +0000] "GET / HTTP/1.1" 200 612 "-" "kube-probe/1.16" "-" <===就绪检查[30/Mar/2020:12:26:21 +0000] "GET / HTTP/1.1" 200 612 "-" "kube-probe/1.16" "-" <===就绪检查#就绪检查 5 秒一次: 2020:12:26:16s ~ 21s 正好5s[30/Mar/2020:12:26:24 +0000] "GET /50x.html HTTP/1.1" 200 537 "-" "kube-probe/1.16" "-" <===健康检查[30/Mar/2020:12:26:26 +0000] "GET / HTTP/1.1" 200 612 "-" "kube-probe/1.16" "-" <===就绪检查[30/Mar/2020:12:26:31 +0000] "GET / HTTP/1.1" 200 612 "-" "kube-probe/1.16" "-" <===就绪检查[30/Mar/2020:12:26:33 +0000] "GET /50x.html HTTP/1.1" 200 537 "-" "kube-probe/1.16" "-" <===健康检查#存活状态检查 9 秒一次:2020:12:26:24s ~ 33s 正好9s!
验证结果如下:
1:进程启动后就绪检查还会继续执行吗?进程启动后就绪检查会按照设置检查时间策略继续运行。2:存活检查时间可以单独设置吗?存活健康检查的时间策略可以单独定义。3:就绪检查、存活检查设置检查时间会相互影响吗?两个检查的时间相互独立,互不影响。
参考文档:
https://itsiv.com/2020/03/30/%e5%b0%b1%e7%bb%aa%e7%8a%b6%e6%80%81%e6%a3%80%e6%9f%a5readiness%e5%92%8c%e5%ad%98%e6%b4%bb%e7%8a%b6%e6%80%81%e6%a3%80%e6%9f%a5liveness/
https://jianshu.com/p/d87a50272310
https://codercto.com/a/40504.html
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。


发表评论

暂时没有评论,来抢沙发吧~