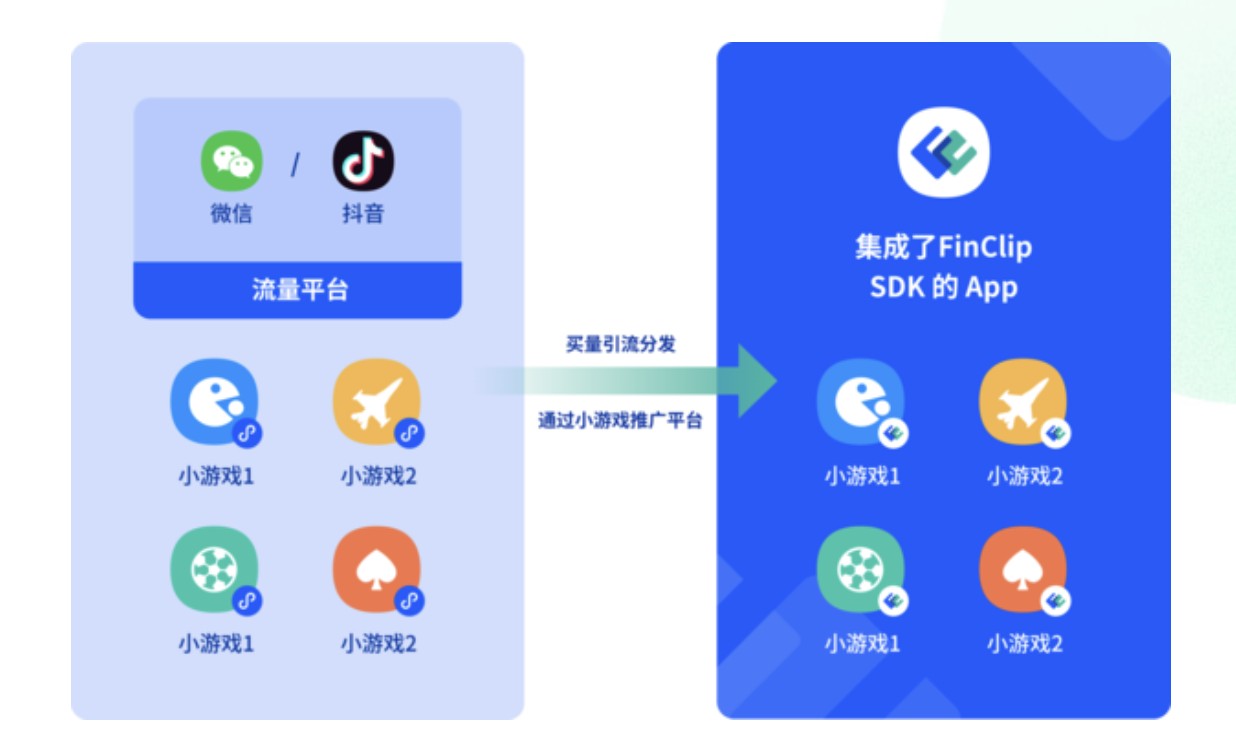
如何利用小游戏开发框架提升企业小程序的用户体验与运营效率
2877
2022-09-21

Python之根据条件筛选特定行(python筛选在某时间段内的行)
")
原博客链接https://blog.csdn-/u010770993/article/details/70312506
一、选取几列组成新的dataframe:
df = df[['A列列名', 'S列列名', 'H列列名']]
二、选取某列'STATUS'里面元素为"ACTIVE"的行,即删掉列STATUS元素不是ACTIVE的行
df = df[df['STATUS'] == "ACTIVE"]
(单项条件搜索,类似SELECT ALL WHERE df.STATUS = ACTIVE)
三、选取'BADTHING'列为元素空的行,即去掉BADTHING所在列中的空行所在行数据,组成一个新的dataframe
df = df[df['BADTHING'].isnull()]
(空值搜索)
四、选取GOODREASON列元素为列表['quality', 'cheap']内元素的行,即可用特定列表内容进行筛选
df = df[df['GOODREASON'].isin(['quality', 'cheap'])]
(多项条件搜索,类似SELECT ALL WHERE df.GOODREASON= quality AND cheap)
五、分组并进行遍历,运用groupby和for:
groupByNew = df.groupby('CITY', sort=False)
for name, groupData in groupByNew:
# TODO …… ……
如代码所示,我们可以对dataframe以某列'CITY'进行分组。我们如何取出某组的数据呢?当然是用
for循环。取出来的name即是组名,而groupData同样是一个dataframe,可以进行更进一步操作。
六、对Series数据进行排序:
series= series.sort_values(ascending=False) # 进行从大到小排序
进阶:关于groupby的一些信息:
在进行groupby运算后,直接打印会得一个object信息,添加groups参数后
print df.groupby(by=['CITY']).groups
打印出来会是带group标签和原数据行标签(也就是原来dataframe里面对应行的index)的组合信息:
{'BEIJING': [25998L, 26134L, 26135L, 26235L, 26340L], 'SHANGHAI': [33370L, 33426L, 33541L], 'CHENGDU': [26153L]
我们可以看到,按照groups来print,得出city为北京的情况下,对应原来的行标签第25998行、26134行等
即使指定了某列:
print df.groupby(by=['CITY'])['QUANTITY'].groups
依然会得出相同的结果:
{'BEIJING': [25998L, 26134L, 26135L, 26235L, 26340L], 'SHANGHAI': [33370L, 33426L, 33541L], 'CHENGDU': [26153L]
除非我们把每个分组的所有行都整理成一行,如用sum来求和:
print df.groupby(by=['CITY'])['QUANTITY'].sum()
这样就可以成功转换成dataframe了:
CITY
BEIJING 5
SHANGHAI 207
CHENGDU 518
……
汇总说明如下:
print '----------NEW------------\n', type(df.groupby(by=['CITY']))
print '----------NEW------------\n', type(df.groupby(by=['CITY']).sum())
print '----------NEW------------\n', type(df.groupby(by=['CITY'])['QUANTITY'])
print '----------NEW------------\n', type(df.groupby(by=['CITY'])['QUANTITY'].sum())
所得结果为:
----------NEW------------
----------NEW------------
----------NEW------------
----------NEW------------
说明:
一个dataframe经过groupby以后得到的类型是pandas.core.groupby.DataFrameGroupBy。而用for in循环取出的每个项的类型是pandas.core.frame.DataFrame
一个dataframe经过groupby再进行sum以后仍然是dataframe(不过具体通过那一列来sum有待考证)
一个dataframe经过groupby以后再进行列选取,得到的是pandas.core.groupby.SeriesGroupBy类型。可知用for in循环取出的是pandas.core.series.Series
一个series经过groupby再进行sum以后仍然是series
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。


发表评论

暂时没有评论,来抢沙发吧~