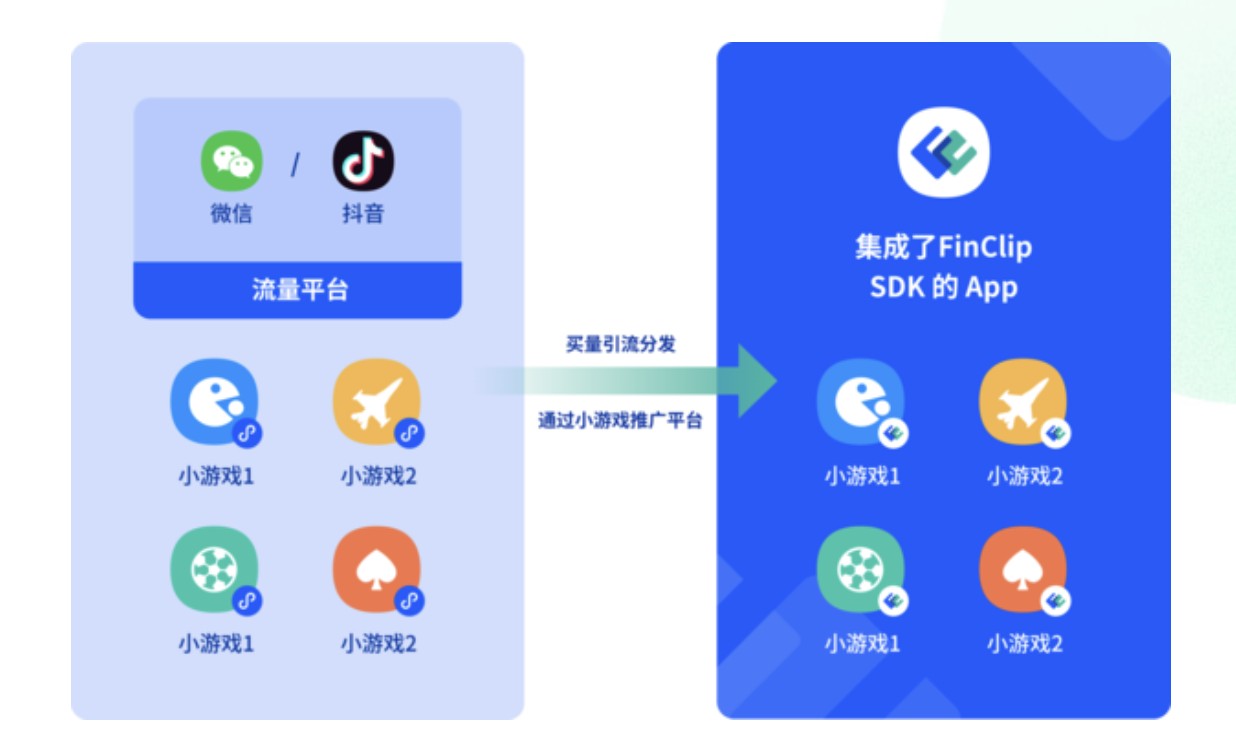
如何利用小游戏开发框架提升企业小程序的用户体验与运营效率
658
2022-09-19

手把手教你进行Scrapy中item类的实例化操作(scrapy.item)
")
接下来我们将在爬虫主体文件中对Item的值进行填充。
1、首先在爬虫主体文件中将Item模块导入进来,如下图所示。
2、第一步的意思是说将items.py中的ArticleItem类导入到爬虫主体文件中去,将两个文件串联起来,其中items.py的部分内容如下图所示。
3、将这个ArticleItem类导入之后,接下来我们就可以对这个类进行初始化,并对其进行相应值的填充。首先去parse_detail函数下对其进行实例化,实例化的方法也十分简单,如下图所示。
4、接下来,我们将填充对应的值。实际上我们在之前通过Xpath或者CSS选择器已经获取到了目标数据,如下图所示,现在要做的就是依次填充目标字段的值。
5、我们可以像字典一样来给目标字段传值,例如item[“title”]= title,其他的目标字段的填充也是形如该格式,填充完成之后如下图所示。
其中,目标字段可以参考items.py中定义的item,这样可以加快填充的速度。
6、到这里,我们已经将需要填充的字段全部填充完成了,之后我们需要调用yield,这点十分重要。再调用yield之后,实例化后的item就会自动传递到pipeline当中去。可以看到下图中的pipelines.py中默认给出的代码,说明pipeline其实是可以接收item的。
7、到这里,关于实例化item的步骤就已经完成了,是不是比较简单呢?我们后面把pipeline配置起来,一步一步的将Scrapy串起来。
看完本文有收获?请转发分享给更多的人
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。


发表评论

暂时没有评论,来抢沙发吧~