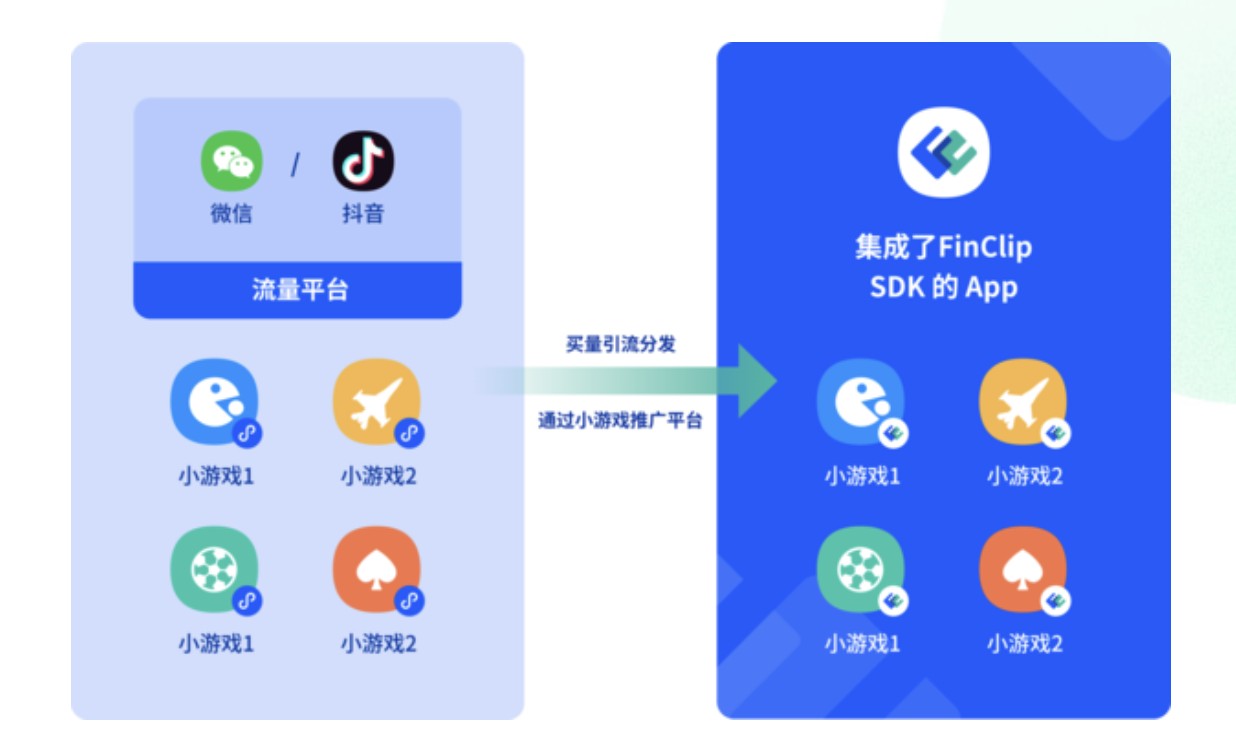
如何利用小游戏开发框架提升企业小程序的用户体验与运营效率
814
2022-09-19

初探numpy(初探后面用什么词)
")
前言
在我们浏览网页,浏览器会渲染输出HTML、JS、CSS等信息;通过这些元素,我们就可以看到我们想要查看的新闻,图片,电影,评论,商品等等。一般情况下我们看到自己需要的内容,图片可能会复制文字并且-图片保存,但是如果面对大量的文字和图片,我们人工是处理不过来的,同时比如类似百度需要每天定时获取大量网站最新文章并且收录,这些大量数据与每天的定时的工作我们是无法通过人工去处理的,这时候爬虫的作用就体现出来了。
内容介绍:
话不多说,直接开始,开始我们的论坛爬虫旅程。
1、模块导入
# encoding:utf8
import requestsfrom bs4 import BeautifulSoup
导入requests网络数据请求模块,用于网络爬虫。导入BeautifulSoup尾页解析模块,用于网页数据处理。
2、获取url资源
获取一个url,通过requests.get()方法,获取页面的信息,这是一个获取url资源的模块。
3、获取子帖列表
获取一个url,调用第一个函数解析财经论坛页面,获取到其中的子帖子的url,存放在list中。这个方法得到了该链接下所有子帖的网络链接,为接下来的数据爬取做准备。子帖列表如下:
4、解析页面
把list中的url通过for循环一个一个解析页面,获取其中我们想要的内容,然后把得到的内容存放在指定的电脑的位置里。
5、传入参数
输入爬取的网页名称以及数据保存路径,本文未对爬取的数据进行进一步解析。爬取结果如下,包括主帖的内容已经跟贴的内容。
版权声明:本文内容由网络用户投稿,版权归原作者所有,本站不拥有其著作权,亦不承担相应法律责任。如果您发现本站中有涉嫌抄袭或描述失实的内容,请联系我们jiasou666@gmail.com 处理,核实后本网站将在24小时内删除侵权内容。


发表评论

暂时没有评论,来抢沙发吧~