CentOS 7.8 部署 Graylog 3
如何从已有的 ELK 体系迁移到全新的 EFGM 体系,获取更好的日志聚合、分析、展现功能呢?

 分享到微信
分享到微信前言
在使用 Graylog 之前我们也有尝试过业界流行的 Kibana,但 Kibana 在数据格式化、视图归档与分类、账户权限分类等方面一直达不到易用性上的要求,且因为数据格式化难以操作,查询日志时会附带大量的干扰信息。
辗转我们找到 Graylog,Graylog 在各方面都完美解决了以上痛点,于是我们从就有的 ELK 体系迁移到新的 EFGM(ElasticSearch、Filebeat、Graylog、MongoDB)体系。
服务安装
安装 MongoDB
直接添加源然后 yum,因为这个很小而且不需要额外配置,可以直接 yum。
vim /etc/yum.repos.d/mongodb-org-3.6.repo
[mongodb-org-4.0]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/4.0/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-4.0.asc
写完源直接 yum,yum 好直接启动就完事了,没什么要调的。
yum -y install mongodb-orgsystemctl enable mongodsystemctl start mongod
安装 ElasticSearch
注意 Graylog3 不支持 ES7,只能使用 ES6.8.3
先去官网下 rpm 包,然后直接 rpm 装就行了。除非你网络环境很科学,否则从外网 yum 是很慢的,别想偷懒了,自己去下安装包吧。
rpm -ivh elasticsearch-6.8.3.rpm
首先要修改 ES 的配置文件:
vim /etc/elasticsearch/elasticsearch.yml
cluster.name: graylog
path.data: /data/elasticsearch
action.auto_create_index: .watches,.triggered_watches,.watcher-history-*
cluster.name: 当前这个 ES 的名字。
path.data: 把索引文件存放在哪里。默认是在 /var/lib。
action.auto_create_index: 这个配置很重要,这个是 ES 弱智化必备参数,代表 ES 接收到任何新数据,都不会为他们自动创建 Index(索引),索引管理由 Sidecar 和 Graylog 全面接管,包括创建新索引这种操作。
然后修改服务配置文件,根据自己的路径重写一下 JAVA_HOME:vim /etc/sysconfig/elasticsearch
JAVA_HOME=/usr/java/default
修改完成后直接启动就可以了。systemctl enable elasticsearchsystemctl start elasticsearch
安装Graylog
首先先去官网下 rpm 包,然后直接 rpm 安装。
rpm -ivh graylog-server-3.1.2-1.noarch.rpmvim /etc/graylog/server/server.conf
修改配置文件:
password_secret = 4EIJkaHtdCnH0NeF
root_password_sha2 = 995387810961981bc36c819f9e963c2edf18bed677b875e654ef2917270e2218
data_dir = /data/graylog-server
http_bind_address = 0.0.0.0:9000
http_publish_uri = http://graylog.civ.ax:9000/
elasticsearch_hosts = http://127.0.0.1:9200
password_secret: 这个是要求 8位以上的,不够 8 位启动会报错,根据自己需要设。
root_password_sha2: 这个是要输入上面密码的 sha256 对应密文,可以直接用工具算,例如:echo -n "4EIJkaHtdCnH0NeF" | sha256sum
data_dir: Graylog 的数据都存放在哪里。
http_bind_address: 是否固定监听 IP。
http_publish_uri: 外网的访问地址,这个地址在查询的时候会用到,比如 Graylog 请求自己的 API 的时候。
elasticsearch_hosts: ES 的地址,因为我们是同服务器部署,所以直接是127。如果你不在本机,这里也要对应改写。
然后修改服务配置文件,注意这里跟 ES 不一样,这个是要写到可执行文件的路径的:
vim /etc/sysconfig/graylog-server
JAVA=/usr/java/default/bin/java
然后直接启动就可以了。
systemctl enable graylog-serversystemctl start graylog-server
如果提示报错,请查看 /var/log/graylog-server/ 下的日志文件,或journalctl -xe -u graylog。
安装 Sidecar
先去官网下包,然后直接 rpm 装。
rpm -ivh graylog-sidecar-1.0.2-1.x86_64.rpm
编辑配置文件:vim /etc/graylog/sidecar/sidecar.yml
server_url: "http://172.16.9.112:9000/api/"
server_api_token: ""
node_name: "APIServer1"
update_interval: 10
send_status: true
server_url: 这个填 Graylog-server 的地址,通常不建议走公网。
server_api_token: 当前这台 Sidecar 自己的秘钥,这个等会会说到,先放着不填。
node_name: 用于辨识是从哪个 Sidecar node 发来的消息,这个很有必要设置一下,做图表统计会用到。
update_interval: 多久 Sidecar 向 Graylog 报告一次自己的运行状况和抓取最新配置文件,单位推测是秒,没明说。
send_status: 是否向 Graylog 报告自己的状态信息,说是关掉可以减负,但是必要不大。
下面还有诸多配置,比如 Sidecar 自己本身就可以抓取日志,但我们这里配合用 Filebeat ,所以就不开启相关配置了。
配置完成后直接启动就就可以了,注意命令区别。
graylog-sidecar -service installsystemctl start graylog-sidecar
如果启动后有问题,就去 /var/lib/graylog-sidecar 看日志。
安装 Filebeat
不重复了,下包装。rpm -ivh filebeat-7.4.0-x86_64.rpm
Graylog 没说对 Filebeat 有什么版本限制,应该直接上最新的就行了(落笔这会儿最新是7.4.0)。
Filebeat 本身没什么调的,在Graylog 套件里, Filebeat 活得比 ES 还工具人,配置全靠 Sidecar 下发,你在这里开关什么都没意义……直接启动跑就行了。systemctl enable filebeatsystemctl start filebeat
这时候访问 Graylog 页面基本就可以直接访问通了,地址就是你在上面配的 http_publish_uri。
这还没完,服务只是起来了而已,现在的 Graylog 还什么都做不了。
Graylog 基本功能配置
在进行任何配置之前,先来了解一下本文所有用到的工具的逻辑关系:
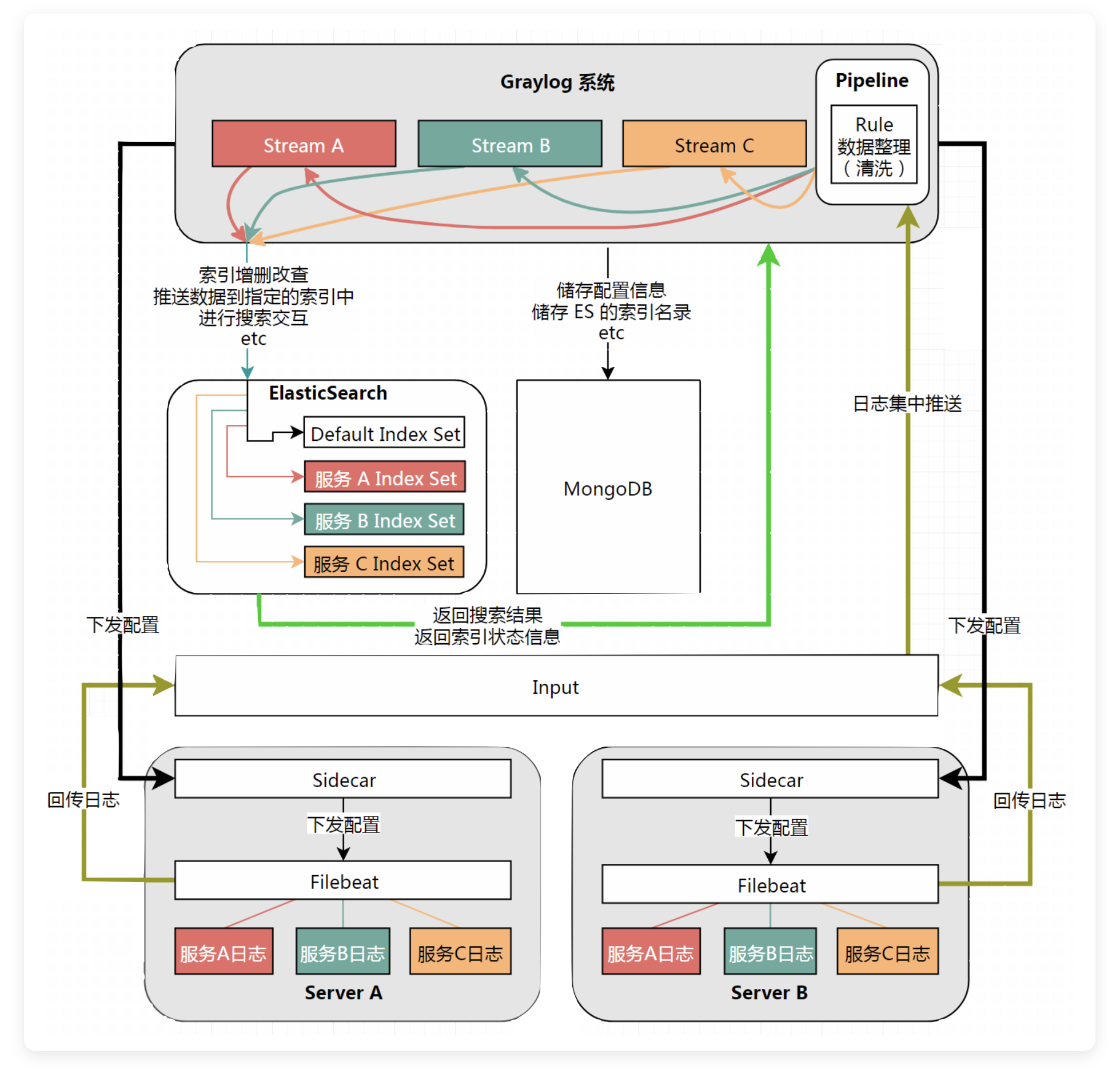
看不懂没关系,很正常的。
额外说明:本文不涉及 Alarm 模块(告警监控模块)的调配
让 Sidecar 正常工作
记得之前提到的 server_api_token,Sidecar 秘钥吗,在 Graylog 的主页的导航栏的 System 选项卡里,找到 Sidecar,在页面第一部分选择 “Create or reuse a token for the graylog-sidecar user”,并在新页面中定义自己新 Sidecar 的 Token Name。
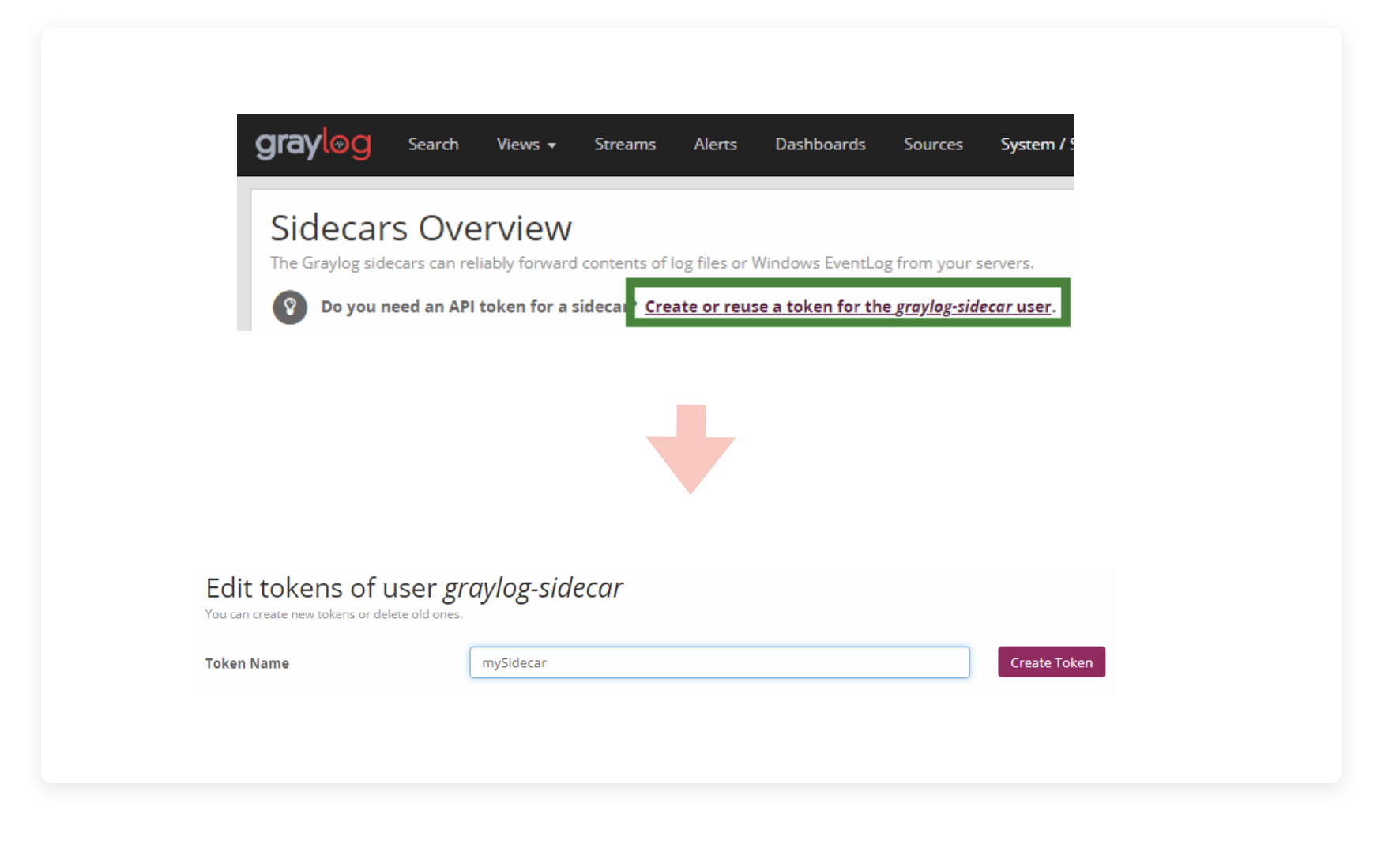
填好点 Create Token 就能创建了,然后点击右边的 “Copy to clipboard”,复制秘钥,再回到我们之前提到的配置文件中,把秘钥粘贴进双引号里,然后重启 Sidecar 就可以了。

Sidecar 重启后,我们就可以在 Sidecar Overview 界面看到 node 了,这时候还没用,只是 node 向 Graylog 报活而已,我们还没有下发配置。
设置入口点 Inputs
在建立配置之前,我们要设定接收器,也就是 Inputs。
在 System 里找到 Inputs,在左侧下拉框选择 Beats,点击 Launch new input
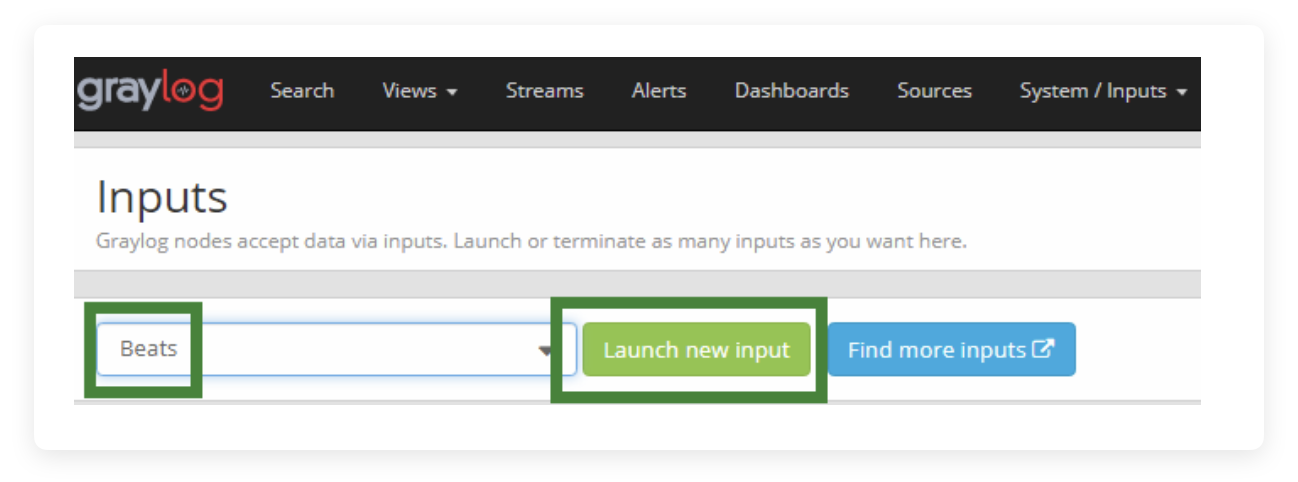
- Title: 这个可以随便写,稍后可以改
- Bind Address: 是否写死监听 IP,比如写成本机内网 IP,或者一个域名,默认是 0.0.0.0,网络环境复杂,比如同时从内网公网收集日志的情况下建议不 bind
- Port: 监听哪个端口,也就是 Inputs 开放哪个端口用于接收 Sidecar 的日志推送
- Recive Buffer Size: 最大允许的接收器缓存大小,相当于一次超过这个数值的日志包推过来会失效,通常来说基本摸不到这个极限,单位 Byte,默认1048576,也就是 1MB
- No. of worker threads: 这个用于指定有多少个线程在处理日志接收,超大并发量的可以酌情调整。
- Do not add Beats type as prefix: 这个很重要,一定要打钩,稍后会讲到。
点击 Save 就可以保存了。以后我们很少会再调这个配置。
当然,你可以建立多个 Input,不同之间的区别由端口控制。
建立 Sidecar 配置
点击右上角的“Configuration”,在右侧选择“Create Configuration”。在新页面中:
- Name: Sidecar 名字,随后可以改。
- Configuration Color: 色块标记,用于区分的,随后可以改
- Collector: 收集器。这里选 Filebeat on Linux,因为我们是用 Filebeat 做日志收集。
配置 Filebeat 的参数
重头戏来了
这里先贴上示例配置文件,逐行讲解:
# Needed for Graylog
fields_under_root: true
## ↑ 用于定义你的特别字段,比如下面那些。这些被标记为 under_root 的数值拥有最高优先级,会覆盖掉任何在这之后的字段,按排列的先后顺序覆盖,比如你如果写了两个 fields.source,那么只有最靠前的会生效;如果你在下面的 fleid 里自定义了 fields.source,也会被这里面 under_root 的给覆盖掉。
fields.collector_node_id: ${sidecar.nodeName}
## ↑ 这个“sidecar.nodeName”变量,就是在配置 Sidecar 时候提到的那个“nodeName”,记起来了吗?这个用于图表统计和消息分类很有必要。
fields.source: ${sidecar.nodeName}
## ↑ 一定要留意加入了这行配置!!否则日志展示界面“Source”会提示“unknown”,图表也会很难做,因为你再多服务器,也只有一个来源“unknown”。
## 另外说回为什么上面“Do not add Beats type as prefix”要勾选的问题。如果那个勾没打,那么这里的“fields.source”和“sidecar.nodeName”都会不叫这个名字,也就是说你这套配置你套进去,“Source”一样是“unknown”,因为人根本不叫“fields.source”。叫啥我还没摸出来,总之打钩后,按我调的这套配置是没问题的。
fields.gl2_source_collector: ${sidecar.nodeId}
# Mobile API #这里创建第一个 filebeat.inputs 配置。
filebeat.inputs:
- type: log #指定日志收集类型,因为是收集 tomcat 日志,所以 type 是 log。
paths:
- /data/service/api/logs/catalina-daemon.out
## ↑ 指定日志位于哪个路径,可以用“*”号,或者写多行“-”的方式来指定多个路径。
multiline.pattern: '^[[:space:]]+(?:at\b|\.{3}\B)|^Caused by:'
## ↑ 这里很重要,这个是决定 Filebeat 能不能收集 Java 堆栈日志这种多行日志的配置。这个正则和相关参数可以照抄。不要用 Filebeat 官方的正则,那个正则是错误的。
multiline.negate: false
multiline.match: after
tags: Catalina-MobileAPI
## ↑ 打了这个 tags 后,这些附加信息会随着 Filebeat 的信息流一起传过来,可以更易于分类消息是从哪个地方,或哪个服务采集来的,这个对后面做分类搜索——也就是 Stream 会用到,也算是很重要的一个配置,否则你多个服务发来的日志经由同一个 Input 进来,所有日志都没有标记特征信息,会变得很难以区分。
## 还有一个用法是写 fields,比如:
# fields:
# server: mobileapi-catalina
## 这个 field 实际上是一个自定义的“key: value”,你可以写任何东西,比如我上面写了“server: mobileapi-catalina”,你可以写成类似“foo: bar”等任何东西,这个 fields 的作用跟上面的 tags 类似,只不过 tags 更“正式化”一点,用 Filebeat 和 Logstash 对接过的人应该知道这个用法。
# PCAPI
## ↑ 不赘述了,配置一样,但是注意“filebeat.inputs”只写一次,不要重复写了,重复写只会生效最靠近底下的一个。
- type: log
paths:
- /data/service/pcapi/logs/catalina-daemon.out
multiline.pattern: '^[[:space:]]+(?:at\b|\.{3}\B)|^Caused by:'
multiline.negate: false
multiline.match: after
tags: Catalina-PCAPI
# Bank
- type: log
paths:
- /data/service/bank/logs/catalina-daemon.out
multiline.pattern: '^[[:space:]]+(?:at\b|\.{3}\B)|^Caused by:'
multiline.negate: false
multiline.match: after
tags: Catalina-Bank
# Metabase
## ↑ 这里比较例外,Metabase 是个用 Docker 起的服务,所以这里的 type 是 docker
- type: docker
## ↑ 这个写法其实局限性极大,应该说 filebeat 收集单容器(没上 K8s)都很局限性,因为只支持容器 ID 或容器的日志路径,你更新一次容器,ID 就变了,但K8s 支持容器名定义。
containers.ids:
## ↑ 这里指定了一个容器 ID,能不能写短 ID 我没测,应该理论上是没问题的。
- 'a67b30747290fc0e31f3cbfdc494fef20f54aed29cdc7d8b842ed6f3b3bad9c2'
tags: Docker-Metabase # tags 用法,不赘述了
multiline.pattern: '^.|^\#+'
## ↑ 这个也是为了匹配多行日志的,metabase 会有一些很神奇的日志格式,比如 echo 上色什么的,这些对 Filebeat 很不友好,因为会抓到大量的中括号和斜杠。
multiline.negate: false
multiline.match: after
output.logstash:
## ↑ 这里指定将收集到的日志输出到哪里
hosts: ${user.hostIP}
## ↑ 调用了一个参数 ${user.hostIP},这个参数可以在右侧的“Variables”选项卡设置。你只需要起名和填写内容就行了,这里写我们在 Input 里配置的信息,比如我没有在 Graylog-server 的配置中启用 bind,所有 Sidecar 都在一个大内网,端口是 5044,那么就是 172.16.9.111:5044。Save 后会自动生成一个参数名,比如上面的 ${user.hostIP}
path: #这两行是用于覆写 filebeat 日志输出记录的配置
data: /var/lib/graylog-sidecar/collectors/filebeat/data
logs: /var/lib/graylog-sidecar/collectors/filebeat/log全部写完后,点击 Save,这一条配置就保存下来了。
点击右上角的 Administration ,进入管理界面,找到我们刚连接上来的新 Sidecar,点击那个 filebeat 勾选上,在右侧下拉菜单中点击 Configuration,点击我们刚写好的配置文件。随后在新的弹窗中确认关联,等待状态从问号变成三角,这套配置就加载成功了!
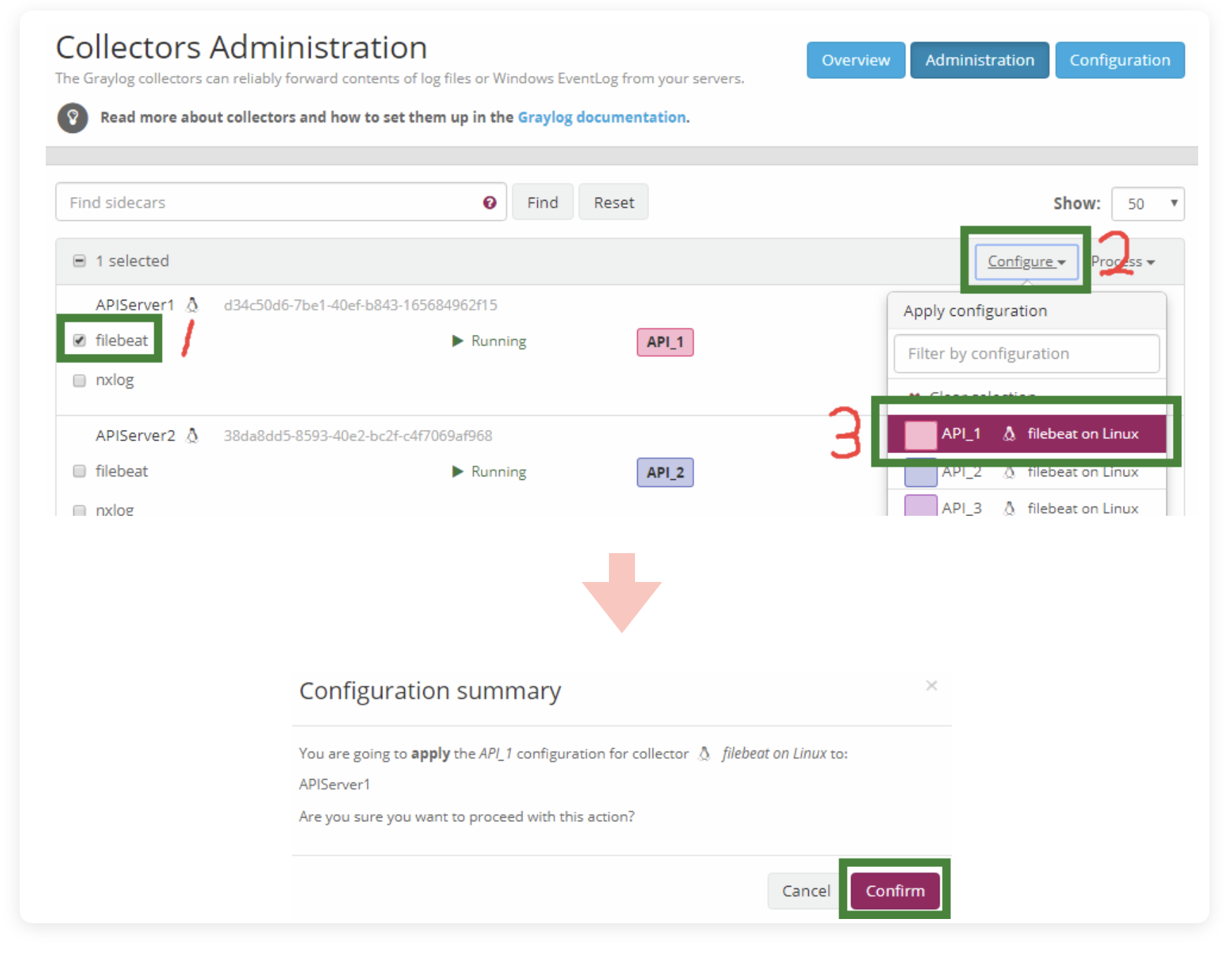
这时候我们就能在 Search 页面看到日志进来的消息了。
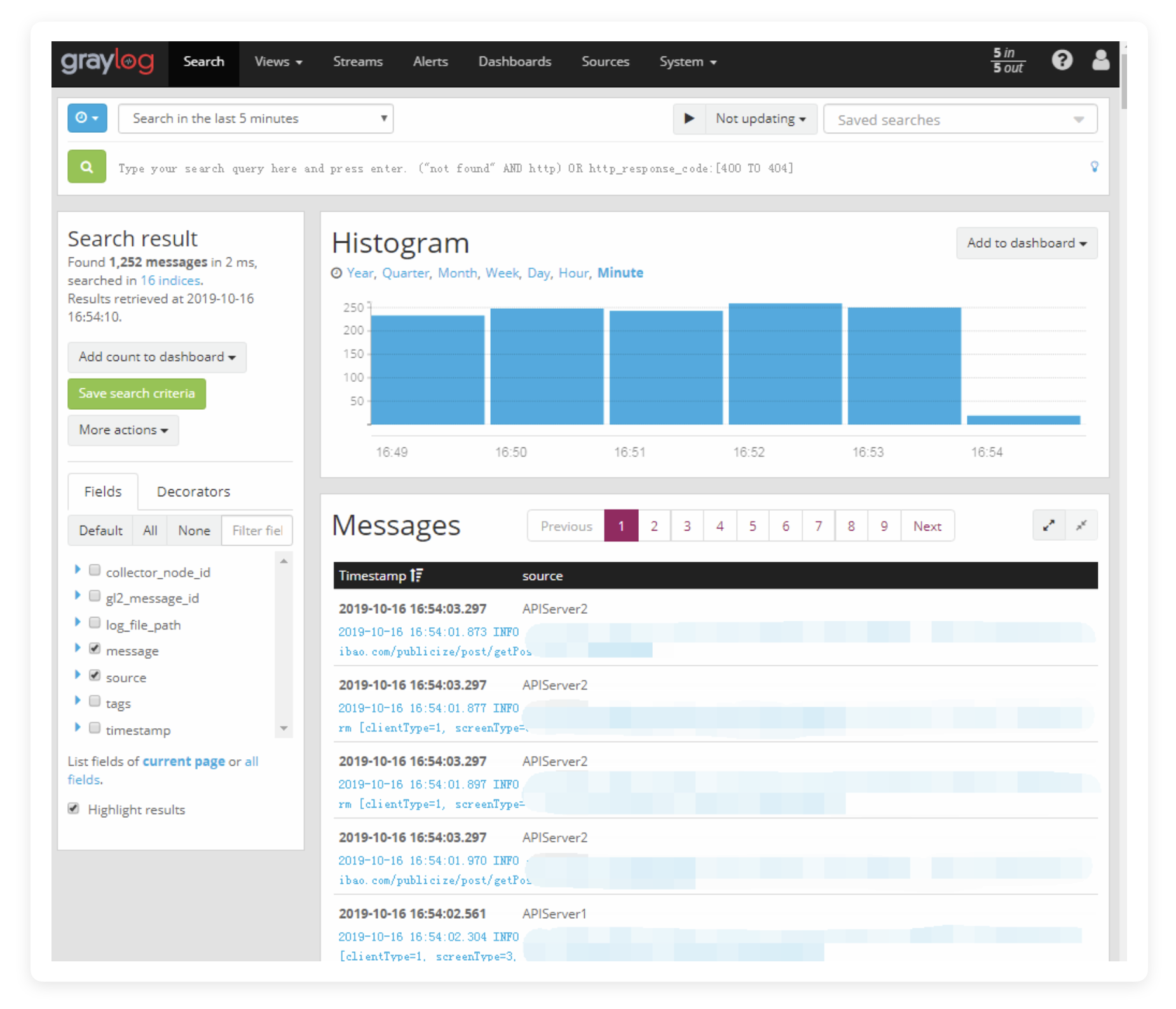
日志规整与分类
使用 Pipeline 处理日志
是否觉得左侧的 Fields 太多太乱?我们来写 Pipeline 规整一下。
点击“Add new pipeline”:
- Title: Pipeline 的标题,这个稍后可以改。
- Description: 描述。稍后可以改。
创建后,点击右上角的“Manage rules” ,点击“Create Rule”,创建一条新的 pipeline 规则:
- Descriptiontion: 描述。稍后可以改
- Rule source: 重头戏,脚本内容,我这里直接提供全文,逐行讲解:
rule "funciton RemoveFields" # 规则名,起头句,相当于 import。
when # 一个判断条件,逻辑很简单。
has_field("beats_type")
## ↑ 当存在 fields("beats_type") 时——实际上这个 fields 不可能不存在,当然,你也可以设为其他你需要的 fields。
then
remove_field("beats_type");
## ↑ 删除以下声明的 fields。这个 fields 的名称写法跟你在 Search 页面上看到的名字一致。
remove_field("@metadata_beat");
remove_field("@metadata_type");
remove_field("@metadata_version");
remove_field("@timestamp");
remove_field("agent_ephemeral_id");
remove_field("agent_id");
remove_field("agent_type");
remove_field("agent_version");
remove_field("ecs_version");
remove_field("host_name");
remove_field("input_type");
remove_field("log_offset");
remove_field("agent_hostname");
remove_field("gl2_message_id");
remove_field("filebeat_stream");
end
写完后点击 Save 保存,这时候还没有分配让 Pipeline 处理哪个信息流,所以需要回到 Manage Pipeline 页面,点击右侧的 Edit
在新页面中,再点击 Edit connections,点击你要处理的信息流,比如 All message
然后点击 Add new stage,就可以指定 Pipeline 在处理这个信息流时的执行步骤,其中会有这些字段:
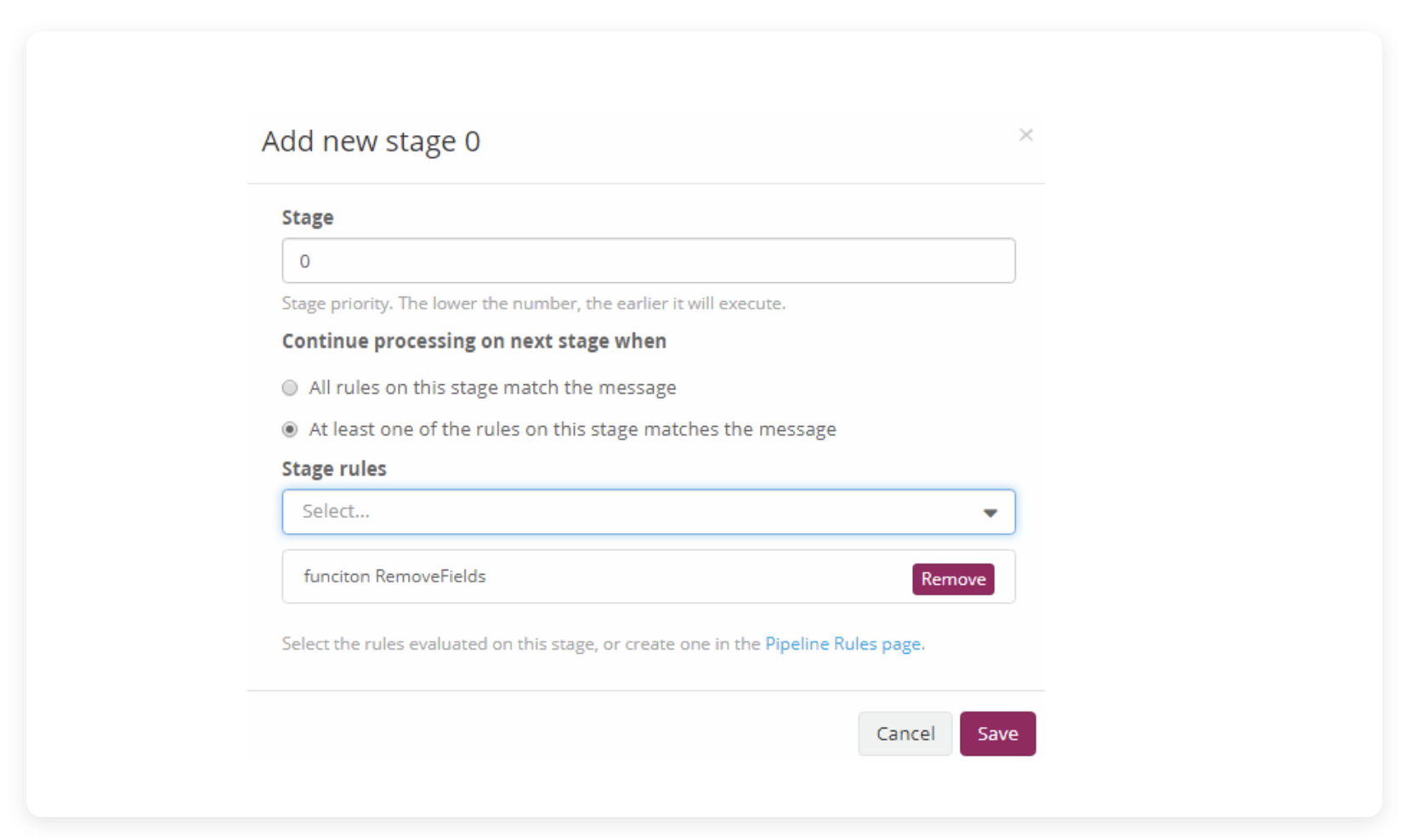
- Stage: 步骤顺序。输入“1” ,表示第一步执行本操作。
- Stage rules: 执行哪一个“Rule”,在下拉里选择刚才写的脚本,表示执行 function RemoveFields 这个 rule。
- Continued processing next stage when: 当满足什么条件时,流转到下一 Stage(不是当前 Stage)操作。因为 Stage 可以建立多个,单个 Stage 里的 rule 也是可以多选的,所以这里有两个选框:
- ○ All rules on this stage match the message: “所有的rule都执行完毕后,进行下一个 Stage”
- ◎ At least one of the rules on this stage matches the message: “只要有一个rule执行完毕,就进入下一个 Stage”
因为我们只有一个 rule 也只有一个 stage,所以这里选什么都没差,有多 stage 需求的可以注意一下这里的配法。
Stage 配好后,Pipeline 是直接生效的,不需要点什么操作了,这时候回到 Search 界面,随便点击一条最新的消息展开看,可以看到消息短了很多,许多 Fields 都被删掉了。
为单个服务建立独立索引
从 ELK 走过来的都知道一个问题,多数据源且数据量大的时候,最好分多个 Index。单 Index 滚雪球越滚越大,会越查越慢,所以在对日志检索分类之前,先来配置多个 Index:
在 System / Sidecar 界面点击 Indices,可以看到默认只有三个索引,所有推过来的消息全部都挤在在 Default index set 中,一旦滚起来,只会越查越慢。
这里我们开始创建新的索引,点击右上角 Create index set:
- Title: 索引的标题,稍后可以改。
- Description: 同上。
- Index prefer: 这个相当于是索引的名字。这个是 ES 里 Index name 的配置,值会存档到 MongoDB 以及 ES 中,以后不能改,建议写个自己能看懂的,比如myService-api。如果有用到“-”号要注意,两个 Index prefer 如果横杠前相同,横杠后不同,也会被报冲突,比如 aaa-bbb 与 aaa-c123d 会被报冲突。
- Analyzer: 要使用什么分析器。这个是 ES 里的 Analyzer 配置。如果你的 ES 自己建了分析器的话,比如自定义了词元过滤器(tokenfilter)和分词器(tokenizer)的分析器(Analyzer),这里输入你的分析器的名字可以直接调用。如果有其他文字或者任何特殊需求,要用到特别的分析器的话,这里可以自定义。不过默认 Standard 就已经能满足大部分需求了,比如能支持中文和英文的日志检索,但是跟 smartcn 比的话还是无法理解词语,所有的词都会被拆成单字,也就是说你搜词必须双引号括起来。不太确定能不能以逗号分隔的形式多选分析器。
- index shards: 这个涉及到 ES 的分片概念,可以去查看相关文档。
- index replicas: 索引副本,默认0。
- max. number of segments: 当触发 ES 对 index 的 optimization 时,最大的切割份数。默认是1,这个是做 Index rotate 切割时定义用的参数。
- Fields type refresh interval: Fields 列表的变动(比如被前面的 Pipeline 删掉)多久会更新到 Index 里,默认是5 ,单位未知,推测分钟。
- Select rotation strategy: 使用什么方法进行索引切割。索引切割是维护索引易用性和查询速度很重要的一环,以前在给 ES 写索引模版的时候这点就很烦人,现在 Graylog 全自动配置了。三个可选项,信息条数、索引大小、日期,建议按日期。
- Select retention stratege: 如何处理过期的索引。删除索引、close index(这个不确定是什么操作,可能是不再引用但保留数据?)、不做任何事情。由于我对日志本身有额外的永久化存档处理,所以这种用于搜索的日志数据基本没必要保留,可以直接删掉。
- max number of indices: 至少保留多少个切割后的数据,也就是存档多少份历史数据。
- 全部配置完成后,点击 Save,这一条 Index 就创建完了。建议多个服务建立多个索引,或来自单 Source 的所有建立一个索引,都可以,看各人需要进行分类。
数据流(Stream)分类
索引建立好后,我们需要开始对 Stream 进行分类。
因为我们刚创建的一条索引(可能你已经创建了多条了),实际上并没有任何实质性的分类效果,只是预先分好不同的坑位而已。目前情况下,所有的日志数据推进来后,仍然是走的默认 Stream ,也就是你能在导航栏的 Stream 选项卡里看到的那个 All messages。
打个比方,目前的默认情况下,现在只配有一个自来水厂(目前只配置了一个 Sidecar,可以配置多个),一个水龙头(目前只配置了一个 Input,可以配置多个),一个水管(目前默认只有一个 Stream,可以配置多个),两个杯子(目前配置了两个 Index 集,一个是默认的 Default Index Set,一个是上面我们刚新建的 Index Set),这里的水管就是我们目前提到的 Stream。
按照正常的理解思路,水从一个水龙头进来后,如果只有一根水管,你是无论如何也分不到两个杯子里的,也就是说我们刚建好的 Index 实际上完全没用上。确实,你可以把我们新建的 Index 设为默认,那么我们就用自己的杯子换掉了原厂的杯子,但这不是解决问题的办法,如果我们有多个服务,也就是多个杯子,这时候必须要拉新的水管,才能同时给多个杯子里装水。
点击导航栏的 Stream 选项卡,打开 Stream 列表。这里展示了目前你所拥有的所有 Stream。如果没错的话,你当前只有三个 Stream,其中的 All Message 就充当了当前环境下的主水管。
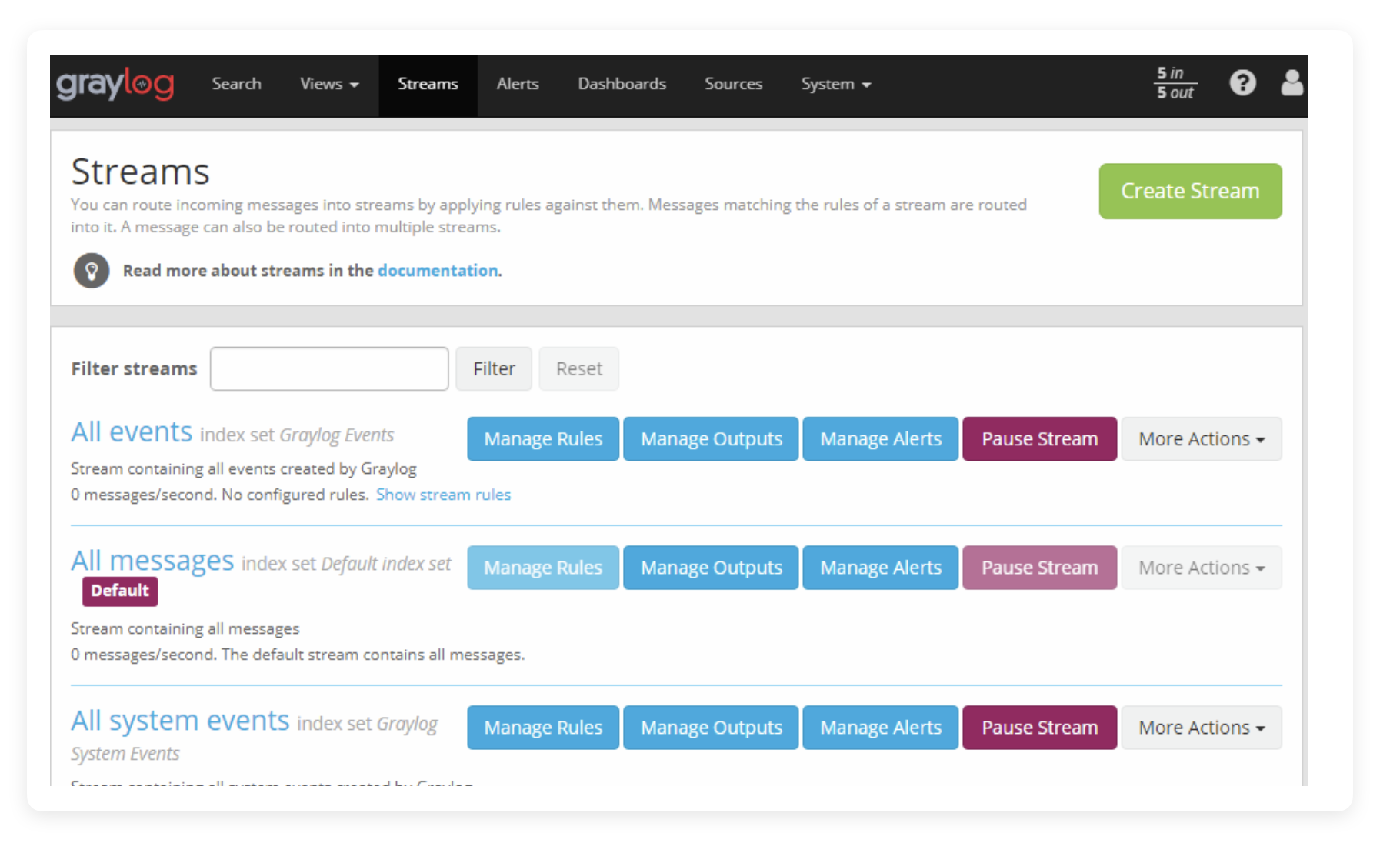
既然我们已经有了两个杯子(可能你已经建了多个杯子),那么我们就要接入一个全新的水管。
点击右侧的 Create Stream:
- Title: 标题。这个稍后可以改
- Description: 描述。稍后可以改
- Index Set: 使用哪个 Index ,也就是前面提到的“杯子”,在下拉列表里可以选择自己的 Index,代表这个 Stream 会将所有符合匹配规则(稍后讲到)的数据捕获到自己的数据流里,同时储存到指定的 Index 中,这个稍后也可以改。
- Remove matches from 'All Messages' Stream: 这个参数要注意一下,如果打上勾,那么所有被本 Stream 捕获的日志数据,都会从默认的 All Message 中移除。也就是说,如果不勾,那你的数据就有双份,勾了,你的数据就只有单份。但是同样地,默认的 All Message Stream 用的是 Default Index Set,如果你建立了多个 Stream,全部都不勾选这个,All Message 的 Index 压力就会很大。这个按照自己的实际情况配置吧,我在调这一块的时候,我是打了勾的。
Stream 建立好后,还是无法发挥作用的,并不是因为右侧的 Start Stream 没有点,而是我们还没有写 Rules,也就是 Stream 无法知道应该抓取什么样的数据,相当于水龙头里流的是各式各样的混合液,你的水管没法从中分离出纯净水,那么我们要给水管设定判定规则,决定符合什么条件的才算“纯净水”。
点击新规则右侧的 More Actions,在下拉菜单中点击 Quick add rule
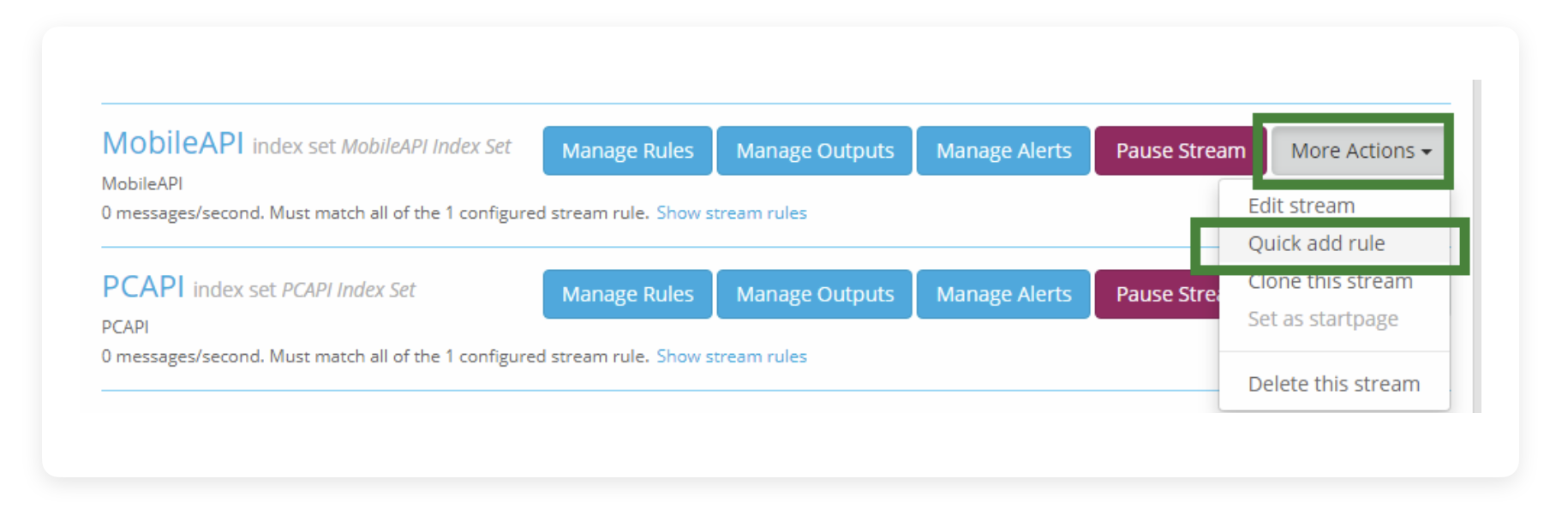
在弹出的选框中:
- Field: 从哪个 Field 进行判断。这里就要重新提到我们之前在对 Sidecar 进行配置时,那里的“tags”参数的作用了。我们给每个服务都定义了特别的“tags”,就是为了这里用到。
- Type: 匹配规则。默认是“match exactly(全量匹配)”,这里用作分类的话可以选“contain(包含)”选项,其他选项如果有需要可以自己调试。
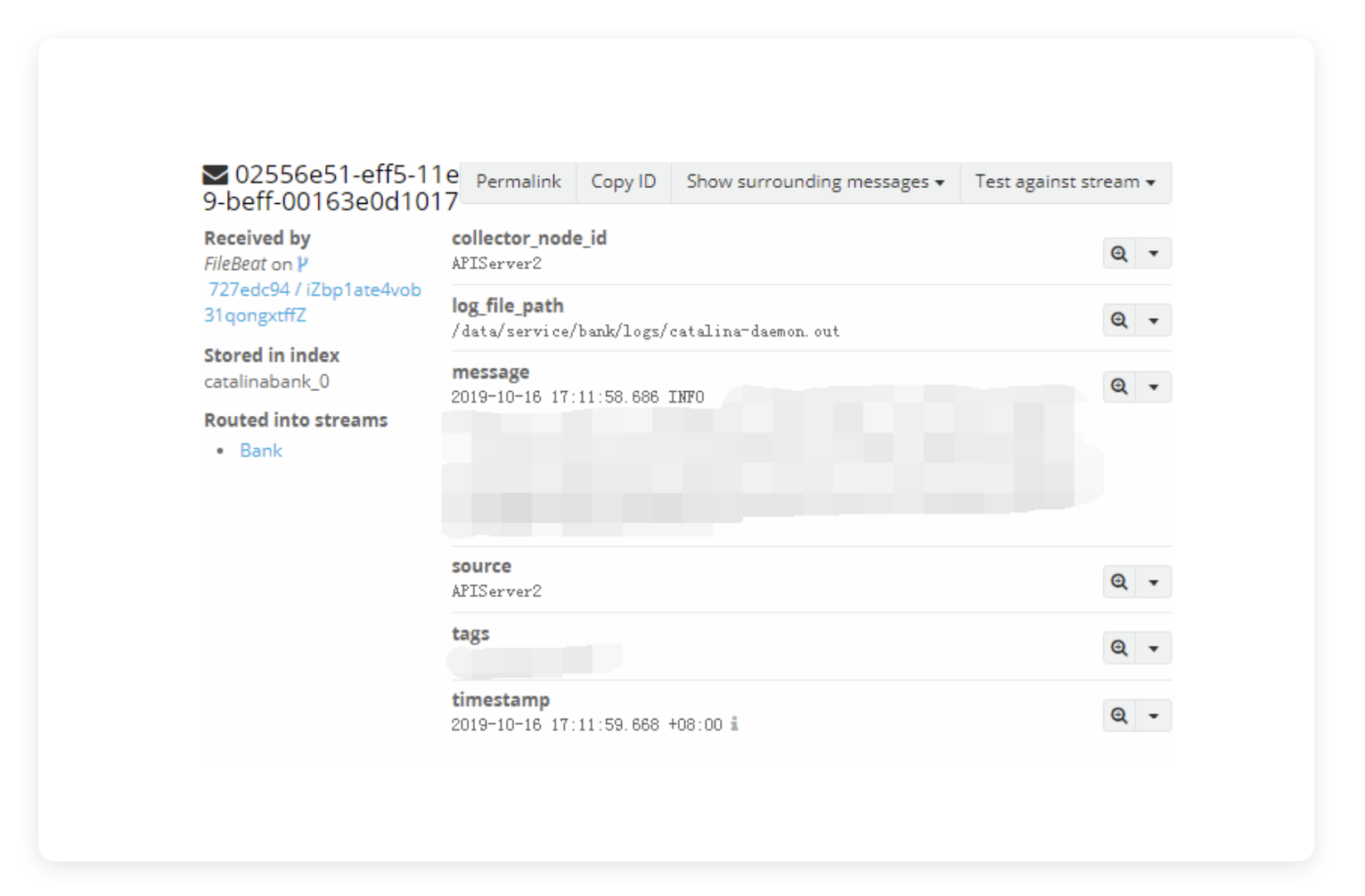
- Value: 要匹配 Fields 中的哪个值。你可以观察一下我们在对 Sidecar 配置完成后,发进来的日志的详细信息——点击 Search 页面,再点击右侧的任意一条日志,将其展开。
展开后,其中的 tags 项中如下图所示:
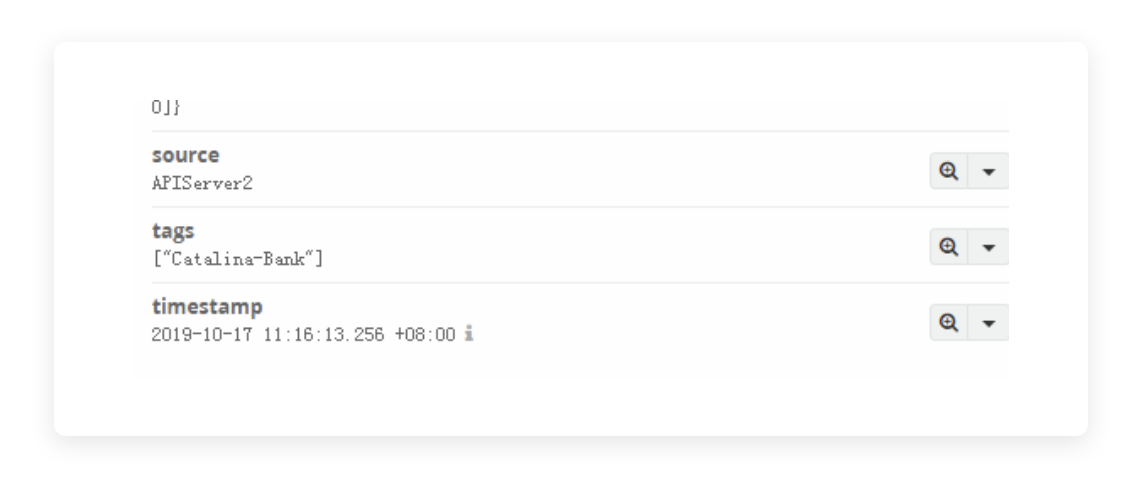
这里会有一个我们自定义的 Vaule(这个 Value 就是这里要填入的东西),比如 “["Catalina-Bank"]”,那么这里写 Bank 就行了,只要能符合我们使用的识别规则“Contain”就可以。
- Inverted: 是否反选。也就是对 Type 进行反向选择,如果你选“contain”,还打钩了这个框,那就是“not contain”,其他规则也类似。
- Description: 描述,稍后可以改。
快速规则添加完成后,只要点击 Start Stream,Stream 就可以根据你设定的 Rule 抓取日志了。这里来进一步讲解一下另一个配置:
点击左侧的 Manage Rules,点击下拉框中你自建的 Input,点击右侧的 Load Message,就可以临时载入一条信息:
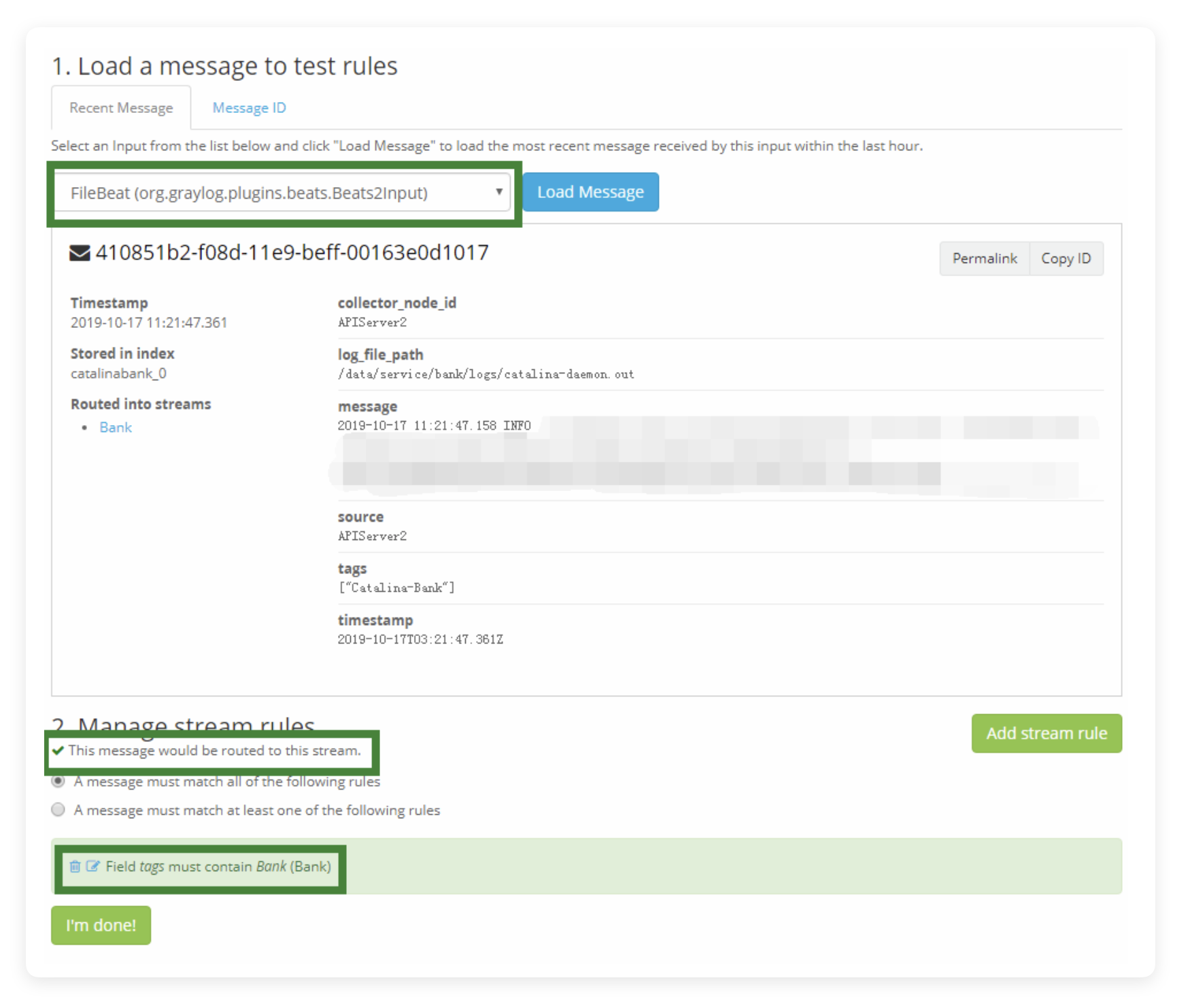
你能在这个信息中看到大部分能够被你用来设立匹配规则的 field。
为什么说大部分呢,因为仍有部分 field 是 Graylog 自带的,这些是不会在这个页面里展示。还有一点要了解,这个 field 是由你在我们先前提到的“Pipeline”中过滤出来的。也就是说,如果这里缺少了你需要的 field,很可能是“Pipeline”中被你过滤掉了,或是在 Sidecar 的配置文件中没有定义正确,这是一个查错的思路。
然后看到下面的选项,如果你的规则设定的没问题,那么会有一个正确的提示信息(代表你的 Rules 通过了 Graylog 的自动检测),当然,偶尔也会报红框
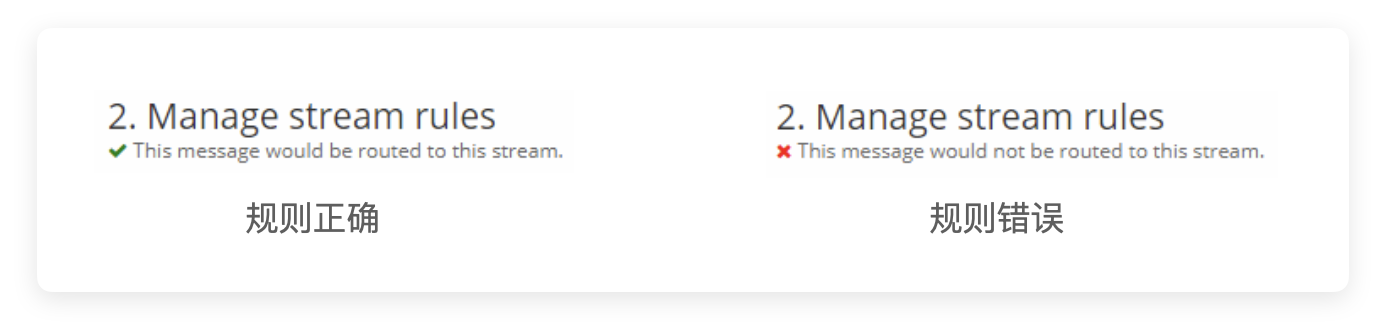
这个错误提示上确实说“这条日志不会被流转到这个 Stream”,但这时候实际上并不代表真正出了问题,因为确实是“这条日志”不会流转而已,不代表符合你匹配规则的不会流转。
这通常会发生在什么情况下呢?
比如我的 Graylog,只有一个 Input,但是有12个服务。虽然都分了不同的 Stream ,但是有一个服务异常活跃,一直在刷日志,那么你能从上面 Load Message 载进来的日志,就多数时候都是这个活跃服务的日志。但你想正在调试的 Stream,对应的服务可能目前是一个不活跃的状态,例如定时器,那么你载不到定时器的日志,就会有这个提示错误。
这种时候完全可以忽视,只要你的 Rule 中匹配的规则没有错就行。当然,你也可以不加载日志,使用上面的 Message ID 和 Index Name 来进行日志提取,查看是否匹配你的 Rule。Message ID 就是在每一条日志展开详情后,那一长串字符,Index Name 就是下面的“Stored in index”。
切换到 Message ID 选项卡,填入这两个数据,点击 Load message,就可以加载到你指定的日志了。
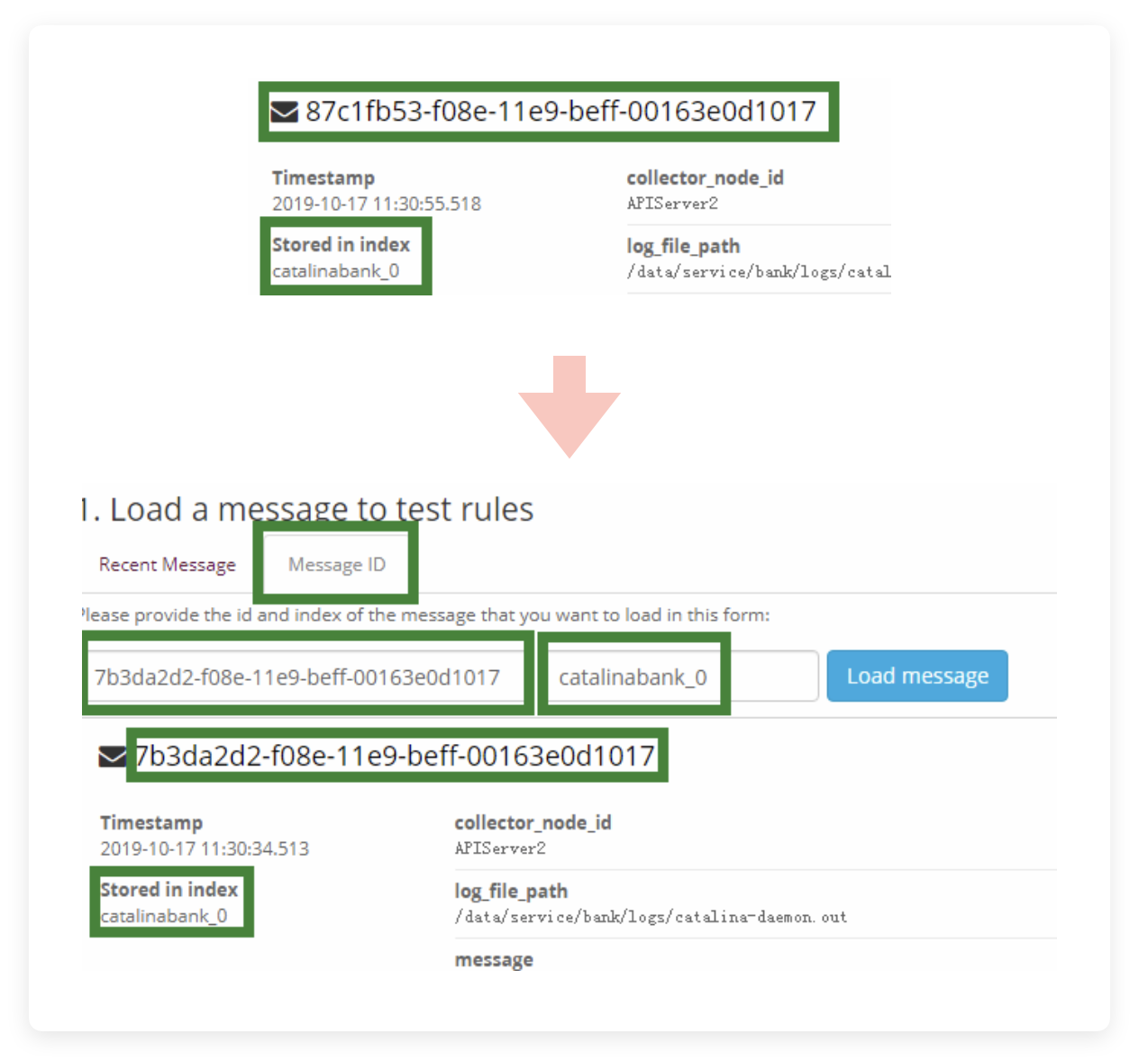
如果提取出来的日志是你想进行处理的日志,同时匹配规则又没问题的话,这里也会亮绿灯的。
这里在 Manage stream rules 里,还有两个选项:
- ◎ A message must match all of the following rules: 日志必须满足下列所有的 rule 才会流转到这个 Stream 中。这个是应对多 rule 时的配置
- ○ A message must match at least one of the following rules: 日志只需满足至少一条 rule 即可。也就是说尽管有多个 rule,只要满足其中一条,日志也会被抓取进来。
当全部配置完成后,点击 I'm done 保存,退回到 Stream 的概览界面,在 Stream 启动的情况下,也就是右侧的 Start Stream 按钮的位置当前显示 Pause Stream 的时候,直接点击左侧你的 Stream 的名字,即可看到当前 Stream 中被 rule 抓取到的所有的日志。
噢,别忘了去修改“Pipeline”中的“Connection stream”,新建立的 Stream 需要重新与 Pipeline 脚本进行关联,否则新的 Stream 里,消息是不会被删掉那些多得要命还烦人的 fields 的。
完结
至此,整套 Graylog 就已经完全可用了,当然是作为管理者(admin)而言。
如果你是为公司,或是为一个集体组织部署,这个界面通常是不会开放给其他人的,你也不想你辛苦配的服务被人一通乱搞,这里就要开始分权:
点击 System ,点击 Authentication,进入到用户管理界面,点击右上角的 Add new user。
- Username: 用户名,用作登录鉴权要素之一,稍后无法改。
- Full Name: 展示用的昵称,稍后可以改。
- Email Address: 这个是对应通知等告警服务用的,本次教程不会提到告警服务。这个稍后可以改。
- Password: 密码,用作登录鉴权要素之一,稍后可以改。
- Roles: 角色。Graylog 内置有几个,比如 Reader 是只能进行公开数据查阅等基本操作。
- Sessions do not time out: 闲置多久后就踢下线,通常我是不勾选的。
- Timeout: 超时判断时间,配合上面那个勾选框用的。
- Time Zone: 时区,根据自己的需要设置就行。
全部设好后,点击 Create User 就可以创建了
但是注意,这新用户创建后是没法用的,登录进去就是一片白板,因为我们还没有给他分配任何的 Stream Permission。
按照官方的建议,不建议给用户分配内建的 Roles 后,再进行权限细调这种操作。比如 Reader 默认是一片白板,我们重新分 Stream Permission 相当于在某些界面中部分越权到了 Views User 的级别。按照严谨的操作,我们应该去左侧 Roles 界面里,创建我们自己定义的 Roles(因为官方默认的 Roles 无法定义),然后在新建的 Roles 里再细分权限,然后去用户中启用我们自定义的 Role。
但是我目前情况下,只需要区分一个 Admin 账户,和一个全公司共享的 Query 账户而已,所以我们直接进行越权分配:
首先进入 User accounts ,点击左侧的 User ,在页面中找到你要设置的用户,选择对应右侧的 Edit 按钮,新页面中的 Stream Permissions 就可以配置用户能访问哪些 Streams,勾选前面教程刚提到的新的 Stream。
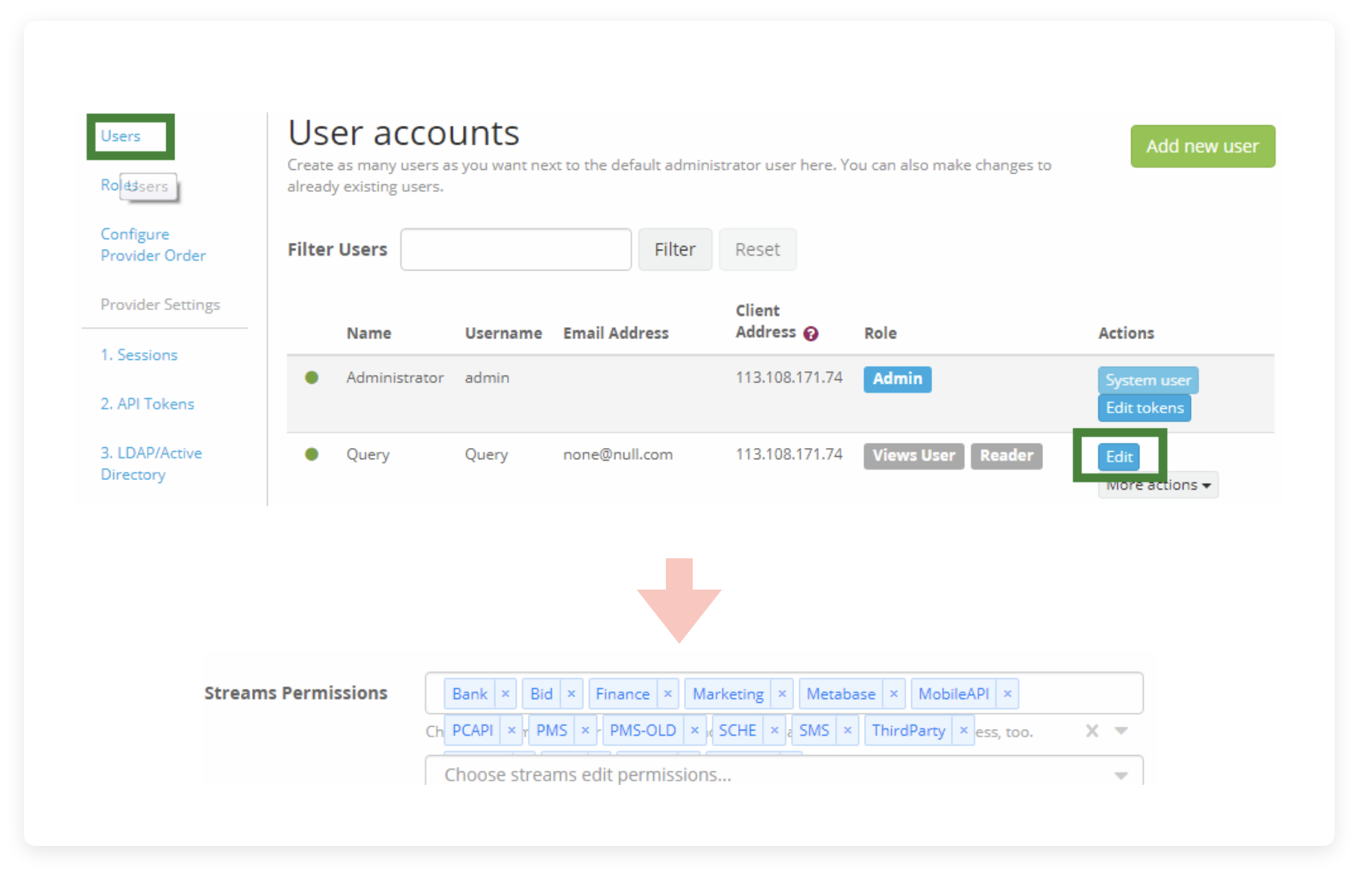
配置好后,点击下面的 Update User,即可完成权限更改。当然更下面还有一个 Change user role,如果你自定义了 Role,可以在这里进行更改。
这时一个新用户就已经创建完成了,这个新用户可以进行权限内的所有操作,比如我们给他分配的在某个 Stream 里进行查阅的操作。
一些填坑的经历
Filebeat、Graylog、ES、Sidecar 无法启动
看日志啊朋友!!至少你都开始用到 Graylog 了,cd、cat 和 tail 至少会用吧。
Filebeat: 说实话出问题的几率极小,基本可以假装这东西不存在,能跑起来,进程在,就结了,不用管活得怎样。
ES: 这个东西算是一个麻烦集合体,无论是 ELK 架构,还是 Graylog 架构,都永远是调得最麻烦也维护最麻烦的那个。通常会由于什么原因起不来呢,我调试的时候总结了一下:
- 权限不对:比如我最开始的时候,没发现 ES 能在配置文件里改数据的储藏位置,傻乎乎地移动 /var/lib/elasticsearch 然后做软链,那么很自然地权限就错了,软链的权限是 root,移过去的文件也是 root,然后报错起不来。修复也很简单,
chown -Rf elasticsearch:elasticsearch ${目录地址}就行了,软链和数据目录都要改。 - 配置不对:官方文档里,
action.auto_create_index: false这个配置实际上是不能用的,启动起来后,ES 的错误日志就会报 “规则过于严格”,所以我这里用的是action.auto_create_index: .watches,.triggered_watches,.watcher-history-*,这也是官方的解决办法之一。 - Java 目录没写: 这个就不详述了,照着本教程做是不会出现这种问题的
- Sidecar: 这家伙也很少会报错,多数时候也是因为 Java 目录没写,其他错误看 /var/log/graylog-sidecar 就行了。
- Graylog: Graylog 的报错基本都会打在日志里,看 /var/log/graylog-server 就行了。
Deflector exists as an index and is not an alias.
这个问题只要不瞎调 ES,几乎是不会出现的。
首先我们理解一下这个 Deflector。直接翻译是叫“变流器”,作用是什么呢?
比如说 Graylog 里的 Indices 列表中,有一个 myIndex 名称的索引,Graylog 在设定这个索引的时候,会自动把第一个索引在 ES 中命名“myIndex_0”,如果发生了rotation(切割),那么下一个就会变成“myIndex_1”这样。
那这种随着时间会越用越久,名字越切花样越多,肯定不能接受啊,所以 Graylog 会同时加上一个 alias。

具体的 alias 使用 curl -X GET "localhost:9200/*?pretty 可以在 ES 里查到,通常是 “[索引名_deflector]” 的规律Graylog 对索引的交互操作——比如写数据,切割之类的,全部会根据 deflector 来指定,也就是 deflector 实际上是一个类似软链一样的昵称,用于指定哪一个索引是目前正在被激活使用的。
前面我们反复提到,Graylog 希望全盘接管 ES 的索引功能,包括创建删除修改这些,如果你没禁止 ES 自动创建索引,也就是 ES 配置文件中的 action.auto_create_index 没有正确被设定。
ES 就会自动为新进来的数据建立索引,然后就会出现个问题:ES 新建索引的时候可没那么多顾忌,来啥命名啥,万一不幸命中了 Graylog 的保留字段,也就是这种“[索引名_deflector]”格式的字段,Graylog 就会检测到,哪怕这个“索引名”并未重复,只要命中了“_deflector”这个格式,就会报上面那条错,“Deflector exists as an index and is not an alias”:“变流器当前作为索引名,而不是作为昵称存在。”
重复看三遍,理解一下这句话:“ES 由于设置错误,根据传入的数据自动创建了一个 Index 名为“[索引名_deflector]”的索引,而这种命名模式是 Graylog 所不接受的,会自动检测出来且报错。”
解决方法也很简单:curl -X GET "localhost:9200/*?pretty 列出现在所有的索引curl -X DELETE "localhost:9200/×××_deflector?pretty 删掉问题索引
如果有必要的话,删掉后重启一次 Graylog 就可以了。
不过某些时候,就算重启后,这个错误在 Graylog 页面上的 Notification 也很可能不会消失,不用管,直接点右上角的 × 关掉就行了。