关于 A/B 测试那些事儿
借助达尔文雀演化论,让我们更好的了解 AB 测试。

 分享到微信
分享到微信
A/B 测试,听起来好像就是在 A 和 B 两个方案中择优选择一个的样子。
但是判断的标准是什么,如何实现一直没有思考过。
正好最近在做数据分析方面的工作,稍有接触,Mark 一下。
A/B test 起源
A/B 测试,其实源于学术层面的“随机对照试验”,作为一种方法论,这种对照试验有着悠久的历史:
- 1747 年,为了治疗坏血病,皇家海军的外科医生 James Lind 设计了一项实验。他测试了苹果醋、大麦水、橘子等六种不同药方。最终发现新鲜的橘子为最佳的治疗药物,尽管那时并不清楚是橘子中维 C 的作用。
- 1835 年,医学史上第一次“双盲实验”在纽伦堡实现。一位名为弗里德里希的公共卫生官员,为对抗当时颇为流行的顺势疗法开启了一个赌注:将 25 瓶顺势疗法盐水和 25 瓶蒸馏水分发给 50 位双盲受试者。最后 8 位声称产生了治疗效果,但揭盲后发现,有 3 位喝的其实是蒸馏水,弗里德里希赢得了赌注。
- 1944 年,在制造原子弹的过程中,曼哈顿计划的领军科学家奥本海默,用 3 种方法测试如何分离铀 235,这一步骤成为整个项目中最关键的环节之一。
- 1960 年代,大卫·奥格威用对照测试的方法验证广告的有效性——写两条不同的文案并要求报纸将其各印一半,同时在文案中留下索取免费样品的邮编和地址,但样式不一样,最终根据实际样品索取量来观察哪种文案效果更好。
可以清楚地看到,随机对照实验作为一种方法论,在现代科学和商业发展中发挥了重要作用。
它本质上能通过控制单一变量的方法来寻找最优解决方案,已经被广泛运用到工程学、医学、教育学和多个领域的商业实践中。
而我们今天要聊的 A/B 测试其实就是随机对照实验在互联网领域的具体应用。
A/B测试,互联网巨头的标配
2000 年 2 月 27 日,谷歌搜索部门的一位工程师进行了互联网时代的第一次 A/B 测试——他想知道搜索结果每页展示多少条是效果最好的,当时默认为 10。
实验是这样设计的:对于 0.1% 的搜索流量,每页显示 20 条结果;另外两个 0.1% 分别显示 25 条、30 条。
这次测试从直接结果看并不成功——由于技术故障,实验组页面的加载速度明显慢于对照组,最终导致实验的相关指标下降。
但谷歌因此获得了意外收获——他们发现即便是 0.1 秒的加载延迟也会显著影响用户满意度。很快,谷歌将改善响应时间提升为高优先级事项。
以这次实验为开端,A/B 测试在谷歌内部快速流行起来。
2013 年,今日头条在起名字的时候,创始团队没有头脑风暴,没有投票,没有老大拍板儿,而是采用科学实验的方式,通过数据确定了头条的名称。
首先将 App Store 上各类免费榜单的前 10 名整理出来;然后根据名字归类(朗朗上口白话类,内涵情怀类,模拟特殊声音类,公司名+用途类等),分析各类的占比,分析结论是朗朗上口的大白话效果最好。再然后,对于设计的名称,分渠道 A/B 测试,确定先验效果类似的发布渠道,分别投放,界面功能 logo 完全一样,统计各个渠道的用户下载和活跃等核心数据指标,最后测得《今日头条》效果最好。

在 Facebook,CEO 扎克伯格曾公开宣称:“在任何给定的时间点,都不会只有一个版本的 Facebook 在线上运行,而是有超过一万个,我们的实验框架能随时发现和感知用户最细微的行为差异。”
三、增长离不开 A/B 测试
在了解如何科学进行一项 A/B 测试之前,我们需要对“A/B 测试是什么”有一个定性的认识。
相信绝大部分人对 A/B 测试的认知是这样的:
两套产品方案,分别让 50% 的用户各自访问不同的两个方案,观察谁的数据效果更好。
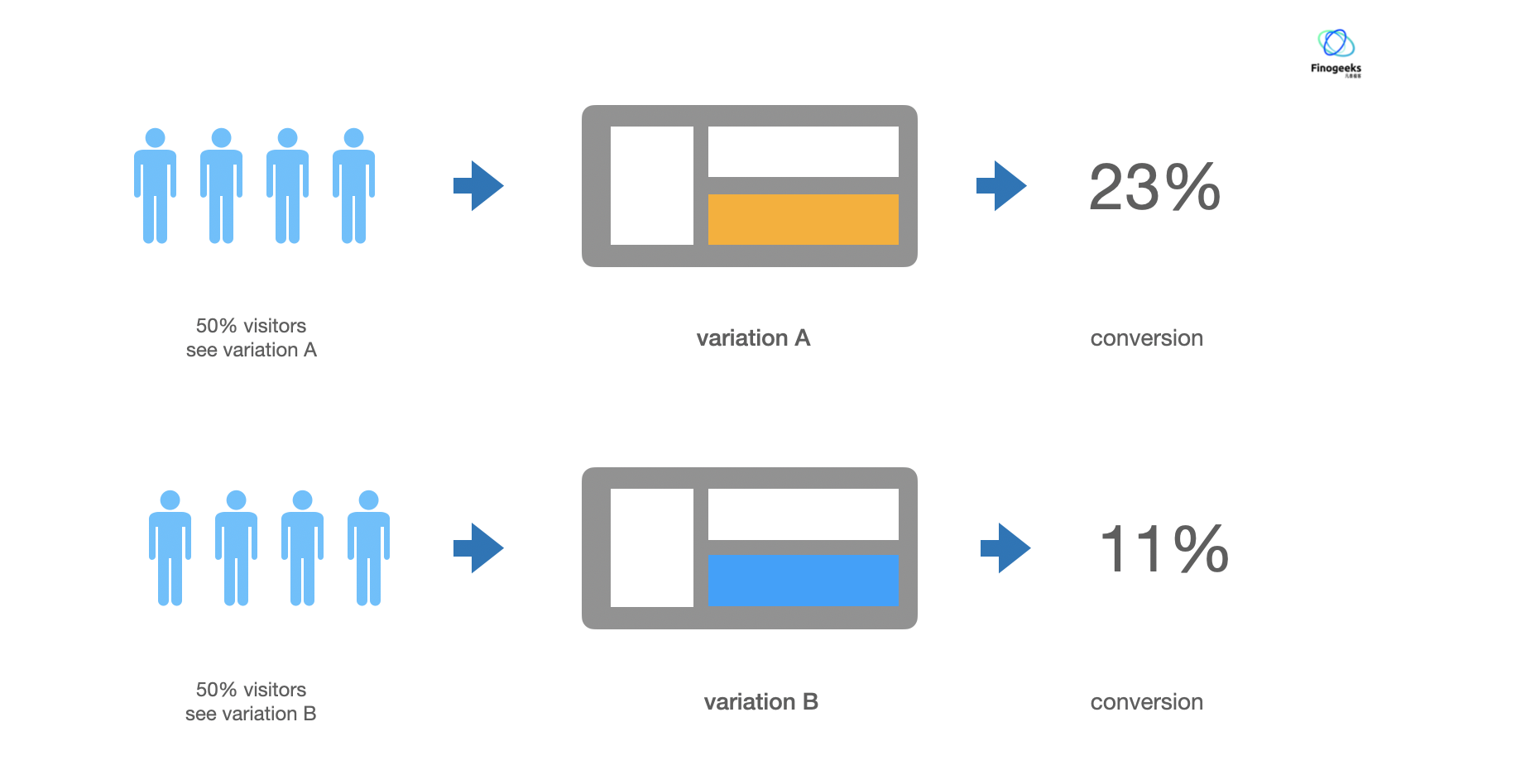

那 A/B 测试的本质到底是什么?自然界中达尔文雀演化的例子已经告诉了我们答案:
达尔文雀族群是生活在加拉帕古斯群岛的多种近缘雀鸟物种的统称。他们之所以被称作为达尔文雀,是因为达尔文发现,它们在体型上几乎完全相同,仅仅只有鸟喙形态不同,并且种类多达十几种,分布在群岛不同的位置。研究结果证明,这些雀鸟族群源属同一种鸟类,因为群岛上不同地方的环境差异,让它们进化出了最适合当前环境的鸟喙。
达尔文雀的选择进化是自然界中活生生的 A/B 测试例子,而这个例子也揭示了 A/B 测试的本质:A/B 测试是一个特定条件下去择优的过程。
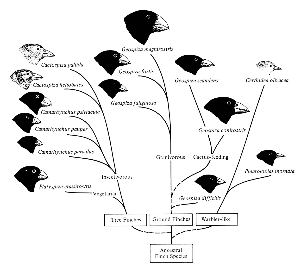

在这个案例中,我们还能发现 A/B 测试 3 个最主要的特征:
1)A/B 测试是多方案并行的,并不是传统认知上的 A、B 两种方案:就像达尔文雀同时进化出了多达 18 种鸟喙。
2)一个 A/B 测试只有一个变量:达尔文雀的演化只影响了鸟喙这一个部位,而其他部位并没有变化。
3)一定遵循了某些规则或特定环境:只有在群岛自然环境的影响下,才能让它们进化出适合当前环境的鸟喙。
正如达尔文雀通过进化出更优的新形态来适应当前的自然环境那样,A/B 测试也是在当前环境下找到最适合用户的产品方案的过程。
在 A/B 测试时,我们犯了什么错?
我们理解了 A/B 测试之后,回顾我们之前做的所谓“A/B 测试”,以及验证产品假设的过程,能找到很多不够严谨的地方,我们在这里一一列举:
做测试时只测两种方案。
我们已经知道,A/B 测试其实是多方案并行的。在很多场合下,我们对一个产品假设其实会有各种各样的争议,但我们通常会被惯性思维所驱使,认为这个假设“非对即错”,正确的方法“不是 A 就是 B”。我们应当对自己的业务有更多的思考,列出足够多的合理假设,并尝试。
新功能发布先上一个新版本,和上一个时间段的老版本对比数据。
这种验证假设的方法不能称做 “A/B 测试”,并且缺乏严谨性。犯这种错误,是因为惯性思维使得我们脑中通常会有这样一个认知:产品两个不同版本的用户一直都是同一批人,会有相同的需求场景以及行为倾向。
这种认知最大的漏洞就是时间 。显然,不同时间周期中的用户行为是不同的,那用户行为反应出的数据自然就会不同:双十一前和双十一后,用户的消费倾向会不同;入夏前和入夏后,用户的生活作息会不同;产品上个版本有强运营的活动,而这个版本没有,用户在产品上的注意力会发生变化...
即使我们控制产品本身的运营节奏,时间周期性造成的用户行为变化通常也是很难预测并量化的,这对产品数据的严谨程度造成了很大的挑战。由于 A/B 测试不受这些因素带来的影响,所以它能够在业界得到越来越多的应用。
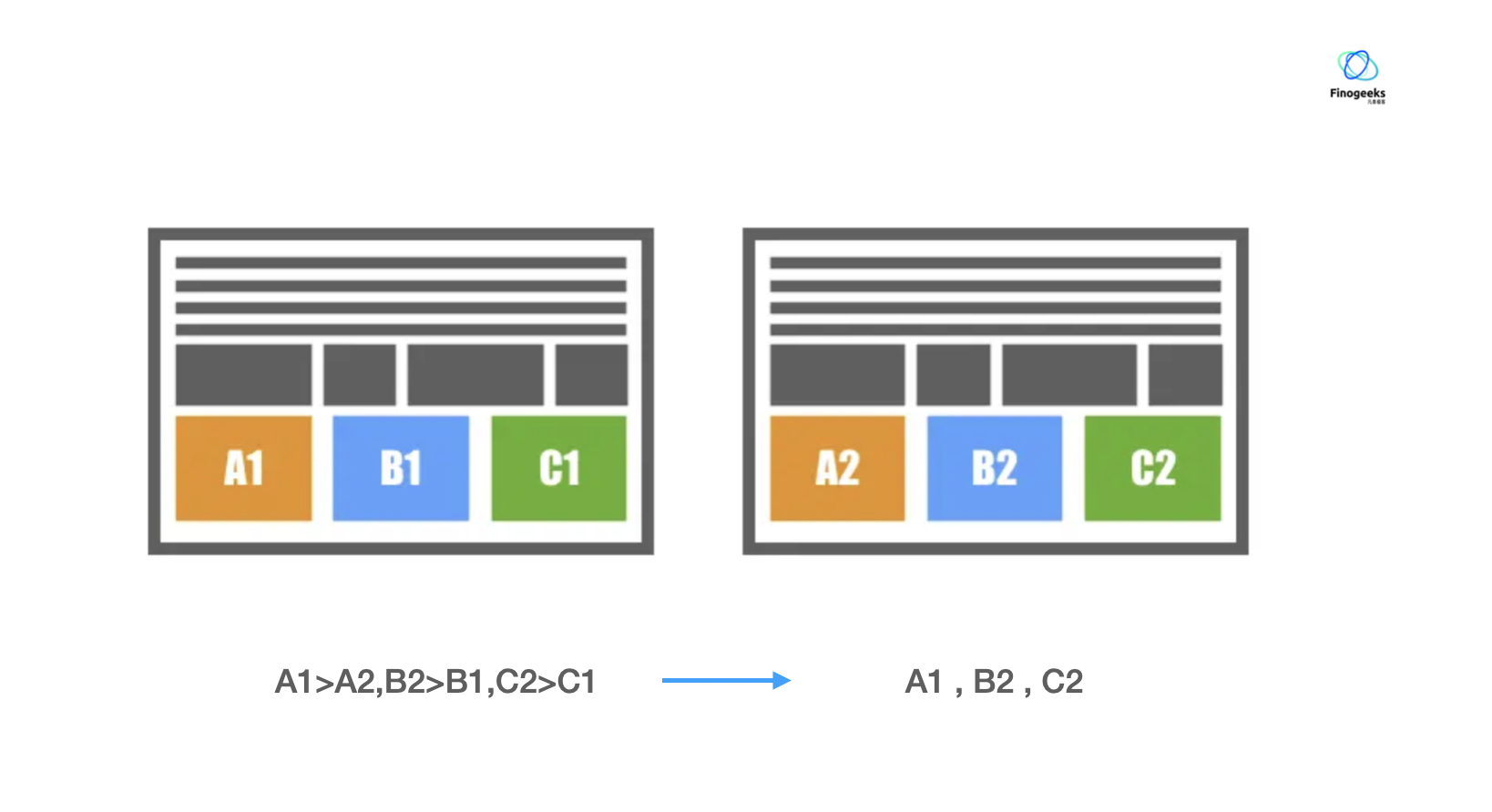
修改产品的两处或更多地方并 A/B 测试,只观察整体指标
我们在达尔文雀的案例中已经提到,A/B 测试的特点是一个测试只有一个变量。因为在这个特定条件下,我们能够容易的推断:A/B 测试中引起产品数据的变化,一定是这单个模块的策略调整引起的。一旦一个产品页面/流程修改了两处以上,如果只看整体数据,那这个页面/流程数据变化的原因将无从追究,因为你根本不知道数据变化到底是哪个模块引起的,每个模块到底发挥了积极的作用,还是消极的作用。
但这并不是说我们不能同时修改一个业务流程的多处地方。相反,在实际的产品与业务迭代中,因为业务本身的需要,这种情况不可避免地发生,需要有一个解决办法。
既然一个 A/B 测试实验只能有一个变量,我们就可以认为:一个业务流程上的有多少各地方进行了调整,那这个业务流程上就同时进行着对应数量的 A/B 测试实验。将这些产品流程上的每处策略调整都抽离成一个个独立的 A/B 测试实验,分别观察同一个整体指标的变化,能取出每个实验的最优方案。每个实验最优方案的组合,就是整个产品模块的最优解。
A/B测试的真正价值
第一点,最直观的一点,A/B测试能真正落地数据驱动,帮助企业科学决策。
在传统的经验主义运营模式下,业务负责人能力再强,也难免有失手的时候。但作为一种前置验证的手段,A/B测试的价值不仅能帮助企业准确评估哪个方案更好,还能评估出好多少、为决策提供量化参考。
第二点,同时也是科学决策的另一面,A/B测试能帮助企业规避风险。
假如一个带有错误特性的新版本全量推给用户,影响的可能是千万、甚至上亿用户的体验,后续挽回损失的代价也同样让企业难以承受。A/B测试可以通过分流出小部分流量进行测试,将负面影响控制在实验范围内,防止错误决策造成更大的损失。“A/B测试本质上,是帮助我们提高选择、判断的准确性,以及提升决策时的效率,降低成本。”
第三点,从企业发展的长远角度看,A/B测试是企业复利式增长的新标配,其尽可能地让企业的每个决策都带来正向收益,持续循环,最终实现指数级增长。
一家公司,从初创企业到独角兽,再到成为行业巨头,整个过程中最令人惊叹的地方往往是:这家企业需要在每个重要节点都做出正确的选择。如果稍有不慎,哪怕只是一次错误,也可能让原处于高歌猛进状态的企业走起下坡路。道理不难懂,难点在于,没有人能看到未来,只能尽最大努力基于已有信息作判断。而A/B测试,是一个把消费者行为数据化、用数据对行为进行量化反馈的过程,这对企业预判趋势大有裨益。
A/B测试的重要性日益凸显,价值已经非常明确。挑战当然有,但当企业真正掌握这把增长利剑时,业务增长路径就会豁然开朗。
参考内容
达尔文雀相关介绍: https://zh.wikipedia.org/wiki/%E9%81%94%E7%88%BE%E6%96%87%E9%9B%80
🤔 如何借助 FinClip 在业务决策中作出明智选择
FinClip 致力于帮助企业移动应用实现模块化开发,企业可以将不同业务功能以小程序形式替代,每个业务模块自行更新、迭代,不再受限于整体 App 发版流程,业务灵活度、开发敏捷度,都将获得极大提升。
通过这种开发模式,有利于运营人员针对移动应用进行 A/B test:
- 通过小程序自身的热更新机制,可以绕过 App 应用市场漫长的审核周期,快速完成功能上线;
- 在测试过程中,可实现实时回滚,纵使线上版本出现问题,也能够回滚至发布前版本;
- 借助「小程序容器」将 App 各个业务模块的代码完美隔离,不影响宿主 App 。
FinClip 不仅提供自定义规则发布引擎,帮助运营人员有效进行业务决策。还可以将复杂的规则配置可视化,只需简单几步,即可完成个性化业务规则推送设置。
- 这些设置既可以是最常见的用户列表、年龄、地域、时间;
- 也可以是一些技术指标,如手机型号、系统版本;
- 更可以自由的添加具有业务特征的规则,如是否为高级付费用户、是否关联过公司其他产品等。
同时,FinClip SDK 可自动上报相关数据,实现测试发布完整闭环,无需对每一个小程序都进行业务埋点开发,并且针对需要复杂业务数据回传的小程序而言,由于 FinClip SDK 有规范的数据上报协议,因此只需完成少量开发,即可实现最准确的数据上报回传。